「Stable Diffusionで作成できる画像を活用したい」
「Stable Diffusionを動画編集に利用したい」
このような場合には、この記事の内容が参考になります。
この記事では、Stable Diffusionで作成したキャラ画像を動画で利用する方法について解説しています。
本記事の内容
- Stable Diffusionの活用
- Stable Diffusionによるキャラクターの作成
- GFPGANによる画像の高画質化
- gTTSによる音声合成
- Wav2Lipによる動画作成
それでは、上記に沿って解説していきます。
Stable Diffusionの活用
Stable Diffusionを使うと、テキストから画像を生成できます。
Stable Diffusionについては、次の記事で説明しています。

Stable Diffusionを使った結果、キャラクター画像も簡単に作成できます。
その画像を利用すれば、表現の幅が広がります。
例えば、次のような解説動画を作成することが可能になります。
ただし、Stable Diffusionではキャラクター画像を作成しているだけです。
その画像をもとにして、キャラクターが話す動画を作成しています。
この記事では、そのための手順を解説していきます。
- Stable Diffusionによるキャラクターの作成
- GFPGANによる画像の高画質化
- gTTSによる音声合成
- Wav2Lipによる動画作成
この手順で説明を進めます。
以上、Stable Diffusionの活用を説明しました。
次は、Stable Diffusionによるキャラクターの作成を説明します。
Stable Diffusionによるキャラクターの作成
Stable Diffusionで画像を作成する上では、プロンプトがキーとなります。
呪文と呼ばれるヤツですね。
この呪文は、次のようなサイトから手に入れることができます。
https://lexica.art/
赤枠で囲ったテキストが、画像生成の呪文となります。
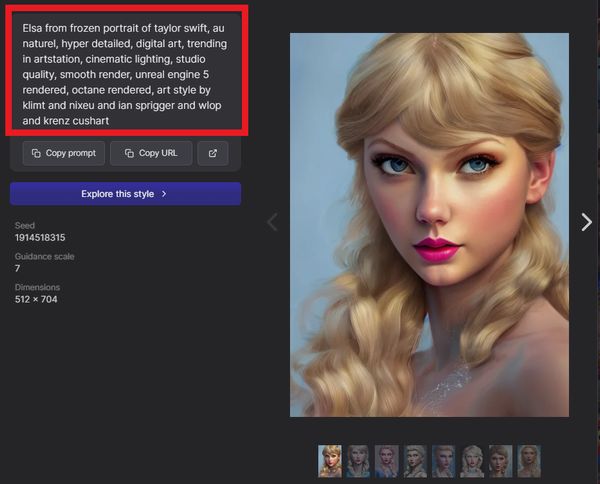
自分で一から考えるよりも、先行者の知恵を借りていきましょう。
コピーした呪文を自分の好みに改変していけば、効率的に進めることができます。
いろいろと試すうちに、気に入ったキャラクターを見つけることができるでしょう。
今回は、上記呪文で1発目に次の画像を生成できました。

以上、Stable Diffusionによるキャラクターの作成を説明しました。
次は、GFPGANによる画像の高画質化を説明します。
GFPGANによる画像の高画質化
GFPGANについては、次の記事をご覧ください。

GFPGANでの処理は、必須ではありません。
ただ、GFPGANの処理を実施した方が画像の質がUPします。
左がオリジナル画像です。
そして、右がGFPGANで高画質化した画像になります。

今回は、オリジナル画像自体の質が高いです。
そのため、そこまで劇的に見た目が変わったという印象はありません。
でも、GFPGANで高画質化した方がベターです。
以上、GFPGANによる画像の高画質化を説明しました。
次は、gTTSによる音声合成を説明します。
gTTSによる音声合成
画像は、ここまでの作業で用意できました。
ここでは、音声を作成していきます。
ここでも、AIの力を借ります。
と言っても、Googleの力を借りるだけです。
詳細は、次の記事で説明しています。

音声は、上記で作成したmp3を利用します。
以上、gTTSによる音声合成を説明しました。
次は、Wav2Lipによる動画作成を説明します。
Wav2Lipによる動画作成
画像と音声が、ここまでの作業で用意できました。
それらのファイルをWav2Lipで処理します。
Wav2Lipのインストールについては、次の記事で説明しています。

また、上記記事では動画と音声を合成しています。
今回は、画像と音声を合成します。
利用するコマンドは、動画と音声の合成の場合と変わりません。
python inference.py --checkpoint_path checkpoints/wav2lip.pth --face 画像ファイルのパス --audio 音声ファイルのパス
画像については、PNG画像だと上手くいかないケースがあります。
そのため、JPGを利用するようにしましょう。
コマンドを実行して成功すると、動画が作成されます。
その動画単体でも使い道はあるかもしれません。
ただ、他の動画と合わせた方が効果的になります。
次のような解説動画のような感じですね。
以上、Wav2Lipによる動画作成を説明しました。

