Yahooファイナンスのスクレイピングを行います。
今回は、過去の株価を取得します。
いわゆる時系列データというモノです。
時系列データがあれば、チャートも描くことができます。
本記事の内容
- ここまでの流れ【Yahooファイナンスのスクレイピング】
- 時系列ページのスクレイピング仕様
- 時系列ページから株価時系列データを抽出
それでは、上記に沿って解説していきます。
ここまでの流れ【Yahooファイナンスのスクレイピング】
Yahooファイナンスのスクレイピングに関しては、段階を踏んで解説しています。
今回は、時系列ページのスクレイピングがメインです。
下記で過去の同シリーズを記載します。
第1弾

第2弾

第3弾

第1弾の記事は、スクレイピングをする上では必読の内容です。
その内容を理解していないと、犯罪者になってしまうかもしれません。
第2弾の記事は、銘柄コードのリストの作成方法を解説しています。
全部で3849件の銘柄リストを取得できました。
このようなリストを作成するのが、スクレイピングの基本中の基本です。
そして、このリストをもとに取得したいデータのページにアクセスが可能となります。
Yahooファイナンスなら、そのためのベースが銘柄コードなのです。
第3弾の記事では、銘柄コードをもとに企業情報ページへアクセスしています。
そして、企業情報ページから企業情報をスクレイピングしています。
第4弾となる今回は、時系列ページから情報を抽出していきます。
では、時系列ページからデータを抽出するための仕様を確認していきます。
時系列ページのスクレイピング仕様
まずは、時系列ページの確認からです。
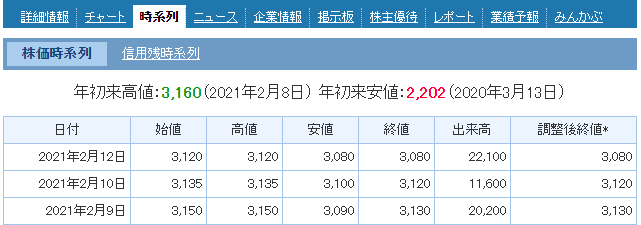
上記を見ればわかるように、時系列データには次の二つが存在します。
- 株価時系列データ
- 信用残時系列データ
本記事では、株価時系列データを対象とします。
おそらく、時系列データと言えば、株価時系列データという認識の人がほとんどでしょう。
信用残データも株価との相関関係があるはずです。
その意味では、取得する価値はあるのかもしれません。
もちろん、他にも用途はあるでしょう。
しかし、今回は株価時系列データをターゲットにします。
株価時系列データをターゲットにする場合、考えるべきポイントは以下。
- 株価時系列データページのURL作成
- データ表示条件の決定
- 改ページ対応
- 株価時系列データの抽出
それぞれを下記で説明します。
株価時系列データページのURL作成
株価時系列データページのURLについて説明しておきます。
銘柄コードのリストから、自動的に各銘柄ごとの株価時系列データページのURLを作成します。
そのときの形式は、以下となります。
「https://stocks.finance.yahoo.co.jp/stocks/history/?code=●」
●は、銘柄コードです。
上記形式のURLで株価時系列データページにアクセス可能となります。
例えば、株式会社 極洋(1301)の場合は次のURLです。
https://stocks.finance.yahoo.co.jp/stocks/history/?code=1301
ただ、上記URLは利用しません。
次の「データ表示条件の決定」でその理由がわかります。
結論は、「まとめ」で説明します。
データ表示条件の決定
表示条件とは、以下のことです。

デフォルトだと、デイリーで1ヵ月がデータ表示の条件となっています。
この条件で「表示」ボタンをクリックすると、次のURLページへ遷移します。
「https://info.finance.yahoo.co.jp/history/?code=1301.T&sy=2021&sm=1&sd=14&ey=2021&em=2&ed=13&tm=d」
上記URLは、以下の2点で注目ポイントがあります。
- ドメイン
- クエリパラメータ
下記で説明します。
ドメイン
「株価時系列データページのURL作成」で確認したURLは、以下。
https://stocks.finance.yahoo.co.jp/stocks/history/?code=1301
「表示」ボタンをクリックして遷移した先のURLは、以下。
https://info.finance.yahoo.co.jp/history/?code=1301.T&sy=2021&sm=1&sd=14&ey=2021&em=2&ed=13&tm=d
それぞれのドメインを抽出すると以下となります。
- stocks.finance.yahoo.co.jp
- info.finance.yahoo.co.jp
正直、これには自分の目を疑いました。
でも、この事実を受け入れていきましょう。
あと、何気にドメイン以降のパスも異なります。
- /stocks/history/
- /history/
せめて、ここは同じにしましょうよ・・・
まあ、スクレイピング対策になっていると言えば、なっていますけどね。
クエリパラメータ
クエリパラメータは、以下。
| パラメータ | 値 |
| sy | 2021 |
| sm | 1 |
| sd | 14 |
| ey | 2021 |
| em | 2 |
| ed | 13 |
| tm | d |
説明するまでもありませんね。
ただ、tmだけは確認しておきましょう。
tmには、以下の値が設定可能です。
| d | デイリー |
| w | 週刊 |
| m | 月間 |
わかりやすいですね。
その意味では、Yahooファイナンスはスクレイピングが容易と言えます。
改ページ対応
データ表示条件を2020年の1年間でデイリーとした場合、件数部分が次のように表示されます。

株価時系列データページでは、1ページに20件しか表示しません。
そのため、改ページへの対応が必要となります。
対応方法は、二つあります。
- クエリパラメータに「&p=●」を付ける
- 「次へ」リンクをクリックする
※●はページ数(1,2,3・・・)
Yahooファイナンスでは、両方の対応を取ることができます。
今回は、「次へ」リンクをクリックする対応を採用します。
クエリパラメータの方式は、対応できないサイトも存在します。
汎用性を考えたら、「次へ」リンクをクリックする方式がベターです。
それにSeleniumを利用している以上は、できる限り利用して身に付けていきましょう。
株価時系列データの抽出
各データ行のhtmlタグは、以下。
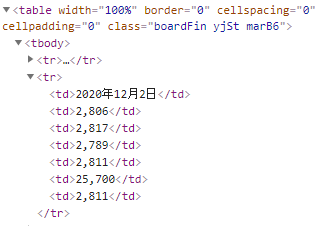
class名指定ではスクレイピングはできませんね。
各tr毎に存在するtd要素の順番により、データ項目を決定できそうです。
| 順番(0スタート) | データ項目 |
| 0 | 日付 |
| 1 | 始値 |
| 2 | 高値 |
| 3 | 安値 |
| 4 | 終値 |
| 5 | 出来高 |
| 6 | 調整後終値* |
念のため、「class=boardFin」のtable要素以下で対象となるtr・tdを絞り込みます。
まとめ
改ページ処理は、「次へ」リンクをクリックしていく形式を採用します。
そのため、スクレイピングする上でアクセスするURLは最初の一つだけです。
銘柄コード1301の2020年におけるデイリーの株価時系列データを得る場合のURLは、以下。
https://info.finance.yahoo.co.jp/history/?code=1301&sy=2021&sm=1&sd=14&ey=2021&em=2&ed=13&tm=d
上記URLにアクセスして、あとは「次へ」リンクをクリックしていくことになります。
もちろん、各ページ最大20件の株価時系列データを抽出しながらです。
以上より、スクレイピングの仕様が決まりました。
次は、実際に株価時系列データをスクレイピングしていきましょう。
時系列ページから株価時系列データを抽出
時系列ページから株価時系列データを抽出するコードは、以下。
現時点(2021年2月13日)では元気モリモリ動いています。
サンプルコード
import sys
import bs4
import traceback
import re
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
# ドライバーのフルパス
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 2
# 遷移間隔(秒)
INTERVAL_TIME = 3
# 開始年・月・日
SY = 2020
SM = 1
SD = 1
# 終了年・月・日
EY = 2020
EM = 12
ED = 31
# タイプ(d:デイリー、w:週刊、m:月間)
TM = "d"
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
page_source = driver.page_source
return page_source
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
# print(soup)
try:
info = []
table = soup.find("table", class_="boardFin")
if table:
elems = table.find_all("tr")
for elem in elems:
td_tags = elem.find_all("td")
if len(td_tags) > 0:
row_info = []
tmp_counter = 0
for td_tag in td_tags:
tmp_text = td_tag.text
if tmp_counter == 0:
# 年月日
tmp_text = tmp_text
else:
tmp_text = extract_num(tmp_text)
row_info.append(tmp_text)
tmp_counter = tmp_counter + 1
info.append(row_info)
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# 次のページへ遷移
def next_btn_click(driver):
try:
# 次へボタン
elem_btn = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.LINK_TEXT, '次へ'))
)
# クリック処理
actions = ActionChains(driver)
actions.move_to_element(elem_btn)
actions.click(elem_btn)
actions.perform()
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
return True
except Exception as e:
print("Exception\n" + traceback.format_exc())
return False
# 数値だけ抽出
def extract_num(val):
num = None
if val:
match = re.findall("\d+\.\d+", val)
if len(match) > 0:
num = match[0]
else:
num = re.sub("\\D", "", val)
if not num:
num = 0
return num
if __name__ == "__main__":
# 引数
args = sys.argv
# 銘柄コード
code = "1301"
if len(args) == 2:
# 引数があれば、それを使う
code = args[1]
# 対象ページURL
page = "https://info.finance.yahoo.co.jp/history/?code=" + code
page = page + "&sy=" + str(SY) + "&sm=" + str(SM) + "&sd=" + str(SD)
page = page + "&ey=" + str(EY) + "&em=" + str(EM) + "&ed=" + str(ED)
page = page + "&tm=" + TM
# ブラウザのdriver取得
driver = get_driver()
# ページのソース取得
source = get_source_from_page(driver, page)
result_flg = True
# ページカウンター制御
page_counter = 0
while result_flg:
page_counter = page_counter + 1
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存
print(data)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 改ページ処理
result_flg = next_btn_click(driver)
source = driver.page_source
# 閉じる
driver.quit()
プログラム詳細は、「時系列ページのスクレイピング仕様」とコード上のコメントをご覧ください。
不明な点がある場合は、同シリーズの過去記事を確認してください。
ただ、次の「対象ページURL」に関しては説明しておきます。
page = "https://info.finance.yahoo.co.jp/history/?code=" + code
page = page + "&sy=" + str(SY) + "&sm=" + str(SM) + "&sd=" + str(SD)
page = page + "&ey=" + str(EY) + "&em=" + str(EM) + "&ed=" + str(ED)
page = page + "&tm=" + TM
クエリパラメータを指定したURLを作成しています。
そして、ここで用いられる定数は以下の部分です。
# 開始年・月・日 SY = 2020 SM = 1 SD = 1 # 終了年・月・日 EY = 2020 EM = 12 ED = 31 # タイプ(d:デイリー、w:週刊、m:月間) TM = "d"
特に問題はありませんね。
ここの値を変更すれば、取得したい条件でスクレイピングが可能です。
実行結果
サンプルコードを実行した結果は、以下。
[['2020年12月30日', '2947', '2960', '2923', '2951', '11100', '2951'], ['2020年12月29日', '2948', '2963', '2945', '2961', '15100', '2961'], ['2020年12月28日', '2929', '2950', '2910', '2950', '22900', '2950'], ['2020年12月25日', '2903', '2930', '2903', '2916', '8300', '2916'], ['2020年12月24日', '2913', '2937', '2909', '2917', '13900', '2917'], ['2020年12月23日', '2913', '2920', '2906', '2913', '6300', '2913'], ['2020年12月22日', '2947', '2947', '2907', '2913', '18000', '2913'], ['2020年12月21日', '2939', '2947', '2912', '2947', '11300', '2947'], ['2020年12月18日', '2935', '2938', '2907', '2937', '15800', '2937'], ['2020年12月17日', '2872', '2920', '2870', '2920', '18900', '2920'], ['2020年12月16日', '2882', '2882', '2871', '2871', '8900', '2871'], ['2020年12月15日', '2880', '2897', '2874', '2881', '12900', '2881'], ['2020年12月14日', '2830', '2888', '2830', '2888', '31200', '2888'], ['2020年12月11日', '2810', '2846', '2810', '2841', '18400', '2841'], ['2020年12月10日', '2812', '2828', '2806', '2815', '14900', '2815'], ['2020年12月9日', '2816', '2827', '2807', '2820', '6600', '2820'], ['2020年12月8日', '2807', '2824', '2805', '2816', '10400', '2816'], ['2020年12月7日', '2820', '2830', '2806', '2811', '12900', '2811'], ['2020年12月4日', '2819', '2819', '2800', '2811', '9200', '2811'], ['2020年12月3日', '2810', '2816', '2796', '2807', '9400', '2807']][['2020年12月2日', '2806', '2817', '2789', '2811', '25700', '2811'], ['2020年12月1日', '2824', '2824', '2780', '2787', '17900', '2787'], ['2020年11月30日', '2816', '2825', '2795', '2795', '18900', '2795'], ['2020年11月27日', '2807', '2825', '2803', '2819', '22000', '2819'], ['2020年11月26日', '2820', '2826', '2801', '2809', '8700', '2809'], ['2020年11月25日', '2839', '2846', '2795', '2831', '27800', '2831'], ['2020年11月24日', '2850', '2860', '2806', '2807', '20100', '2807'], ['2020年11月20日', '2848', '2848', '2820', '2832', '10200', '2832'], ['2020年11月19日', '2834', '2846', '2812', '2838', '11600', '2838'], ['2020年11月18日', '2813', '2838', '2790', '2838', '14400', '2838'], ['2020年11月17日', '2800', '2813', '2785', '2813', '13100', '2813'], ['2020年11月16日', '2820', '2820', '2788', '2804', '15800', '2804'], ['2020年11月13日', '2821', '2821', '2771', '2784', '10500', '2784'], ['2020年11月12日', '2807', '2839', '2805', '2814', '13900', '2814'], ['2020年11月11日', '2810', '2850', '2796', '2850', '27300', '2850'], ['2020年11月10日', '2795', '2819', '2772', '2793', '27000', '2793'], ['2020年11月9日', '2800', '2800', '2757', '2795', '15800', '2795'], ['2020年11月6日', '2771', '2786', '2671', '2782', '30900', '2782'], ['2020年11月5日', '2745', '2790', '2671', '2671', '31400', '2671'], ['2020年11月4日', '2763', '2768', '2744', '2746', '12000', '2746']]
最初の2ページ分の40件だけです。
それは、以下のように「2」と設定しているからです。
# 改ページ(最大) PAGE_MAX = 2
適当にここを「99999」などにすれば、全ページ分をスクレイピングします。
もしくは、PAGE_MAXの制御を無効にするかです。
まとめ
以下は、本ブログにおけるスクレイピングでは当たり前の定数です。
# ドライバーのフルパス CHROMEDRIVER = "chromedriver.exeのパス" # 改ページ(最大) PAGE_MAX = 2 # 遷移間隔(秒) INTERVAL_TIME = 3
この定数に関して、わからないところがある場合は過去記事をご覧ください。
メルカリのスクレイピングシリーズが、特に参考になります。
メルカリのスクレイピング第1弾

メルカリのスクレイピング第2弾

メルカリのスクレイピング第3弾