
Yahooファイナンスのスクレイピングを解説します。
今回は、信用残時系列データを取得します。
本記事の内容
- ここまでの流れ【Yahooファイナンスのスクレイピング】
- 時系列ページのスクレイピング仕様
- 時系列ページから信用残時系列データを抽出
それでは、上記に沿って解説していきます。
ここまでの流れ【Yahooファイナンスのスクレイピング】
Yahooファイナンスのスクレイピングに関して、段階を踏んで解説してきました。
今回で第5弾となります。
下記で過去の同シリーズを記載します。
第1弾

第2弾

第3弾

第4弾

第1弾の記事は、スクレイピングをする上では必読の内容となります。
その内容を理解していないと、法律違反になることがありえます。
それも、刑事罰を受ける可能性があります。
第2弾の記事は、銘柄コードリストの作成方法を解説しています。
全部で3849件の銘柄コードをスクレイピングで収集しました。
第3弾の記事は、企業情報のスクレイピングを解説しています。
第2弾の内容と合わせれば、上場企業の企業情報一覧を作成可能です。
第4弾の記事は、株価時系列データのスクレイピングを解説しています。
その時系列データをもとに、株価チャートなど作成することも可能になります。
今回の第5弾では、信用残時系列データのスクレイピングを解説していきます。
そして、今回の第5弾の記事で一連のシリーズは完結です。
なお、掲示板のスクレイピングに関しては次の記事を参考にしてください。

これは、今回のシリーズとは別枠で解説しています。
統合してもいいのですが、スクレイピングの技術的には全く別物となります。
難易度は、掲示板データをスクレイピングする方が 圧倒的に高いです。
以上、ここまでの流れとなります。
では、スクレイピングの仕様を以下で解説していきます。
時系列ページのスクレイピング仕様
時系列ページには、次の二つのデータが存在しています。
- 株価時系列データ
- 信用残時系列データ
前回の第4弾では、株価時系列データをスクレイピングしました、
今回は、信用残時系列データを対象とします。
この場合に考慮すべきポイントは、以下。
- 信用残時系列データページのURL作成
- データ表示条件の決定
- 改ページ対応
- 信用残時系列データの抽出
それぞれを下記で説明します。
信用残時系列データページのURL作成
信用残時系列データページのURLについて説明しておきます。
銘柄コードのリストから、自動的に各銘柄ごとの信用残時系列データページのURLを作成します。
そのときの形式は、以下となります。
「https://info.finance.yahoo.co.jp/history/margin/?code=●」
●は、銘柄コードです。
上記形式のURLで信用残時系列データページにアクセス可能となります。
例えば、株式会社 極洋(1301)の場合は次のURLです。
https://info.finance.yahoo.co.jp/history/margin/?code=1301
このURLをベースにスクレイピングを行っていきます。
データ表示条件の決定
データ表示条件とは、以下のことです。

デフォルトだと、直近3ヵ月がデータ表示の条件となっています。
この条件で「表示」ボタンをクリックすると、次のURLページへ遷移します。
「https://info.finance.yahoo.co.jp/history/margin/?code=1301.T&sy=2020&sm=11&sd=16&ey=2021&em=2&ed=14」
上記URLで注目すべきは、クエリパラメータになります。
| パラメータ | 値 |
| sy | 2020 |
| sm | 11 |
| sd | 16 |
| ey | 2021 |
| em | 2 |
| ed | 14 |
設定した表示条件が、クエリパラメータとなっているということです。
この値を適当に変更すれば、自由に表示条件を設定できますね。
改ページ対応
データ表示条件を2020年の1年間と設定した場合、件数部分が次のように表示されます。
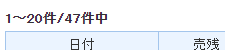
信用残系列データページでは、1ページに最大20件までの表示となります。
そのため、改ページへの対応が必要となります。

Selenium(詳細は第1弾の記事にて説明)を使って、スクレイピングをしています。
そのため、Seleniumを利用してスクレイピングを行いましょう。
具体的には、「次へ」リンクをクリックして改ページ対応を行います。
関数化しているので、あまり意識する必要はありませんけどね。
信用残時系列データの抽出
各データ行のhtmlタグは、以下。
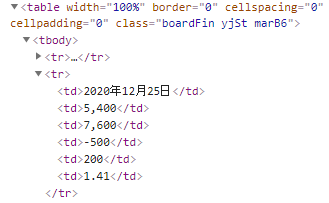
第4弾の株価時系列データと同じhtml構成です。
同じようにスクレイピングしましょう。
ただし、データ項目(順番)は異なります。
| 順番(0スタート) | データ項目 |
| 0 | 日付 |
| 1 | 売残 |
| 2 | 買残 |
| 3 | 売残増減 |
| 4 | 買残増減 |
| 5 | 信用倍率 |
あと、信用倍率が小数点表示ということも注意です。
まとめ
第4弾の仕様とは、若干異なる程度です。
もし、不明点があれば、第4弾の記事も併せて確認してください。
では、実際に信用残時系列データをスクレイピングしていきましょう。
時系列ページから信用残時系列データを抽出
時系列ページから信用残時系列データを抽出するコードは、以下。
現時点(2021年2月14日)では元気バリバリ動いています。
サンプルコード
import sys
import bs4
import traceback
import re
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
# ドライバーのフルパス
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 2
# 遷移間隔(秒)
INTERVAL_TIME = 3
# 開始年・月・日
SY = 2020
SM = 1
SD = 1
# 終了年・月・日
EY = 2020
EM = 12
ED = 31
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
page_source = driver.page_source
return page_source
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
# print(soup)
try:
info = []
table = soup.find("table", class_="boardFin")
if table:
elems = table.find_all("tr")
for elem in elems:
td_tags = elem.find_all("td")
if len(td_tags) > 0:
row_info = []
tmp_counter = 0
for td_tag in td_tags:
tmp_text = td_tag.text
if tmp_counter == 0:
# 年月日
tmp_text = tmp_text
else:
tmp_text = extract_num(tmp_text)
row_info.append(tmp_text)
tmp_counter = tmp_counter + 1
info.append(row_info)
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# 次のページへ遷移
def next_btn_click(driver):
try:
# 次へボタン
elem_btn = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.LINK_TEXT, '次へ'))
)
# クリック処理
actions = ActionChains(driver)
actions.move_to_element(elem_btn)
actions.click(elem_btn)
actions.perform()
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
return True
except Exception as e:
print("Exception\n" + traceback.format_exc())
return False
# 数値だけ抽出
def extract_num(val):
num = None
if val:
match = re.findall("\d+\.\d+", val)
if len(match) > 0:
num = match[0]
else:
num = re.sub("\\D", "", val)
if not num:
num = 0
return num
if __name__ == "__main__":
# 引数
args = sys.argv
# 銘柄コード
code = "1301"
if len(args) == 2:
# 引数があれば、それを使う
code = args[1]
# 対象ページURL
page = "https://info.finance.yahoo.co.jp/history/margin/?code=" + code
page = page + "&sy=" + str(SY) + "&sm=" + str(SM) + "&sd=" + str(SD)
page = page + "&ey=" + str(EY) + "&em=" + str(EM) + "&ed=" + str(ED)
# ブラウザのdriver取得
driver = get_driver()
# ページのソース取得
source = get_source_from_page(driver, page)
result_flg = True
# ページカウンター制御
page_counter = 0
while result_flg:
page_counter = page_counter + 1
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存
print(data)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 改ページ処理
result_flg = next_btn_click(driver)
source = driver.page_source
# 閉じる
driver.quit()
プログラム詳細は、「時系列ページのスクレイピング仕様」とコード上のコメントをご覧ください。
不明な点がある場合は、同シリーズの過去記事を確認してください。
特に第4弾で紹介したサンプルコードとは、ほとんど変わりません。
実行結果
サンプルコードを実行した結果は、以下。
[['2020年12月25日', '5400', '7600', '500', '200', '1.41'], ['2020年12月18日', '5900', '7400', '500', '700', '1.25'], ['2020年12月11日', '5400', '8100', '900', '100', '1.50'], ['2020年12月4日', '4500', '8000', '1500', '1200', '1.78'], ['2020年11月27日', '6000', '6800', '800', '200', '1.13'], ['2020年11月20日', '6800', '6600', '900', '3300', '0.97'], ['2020年11月13日', '7700', '9900', '800', '300', '1.29'], ['2020年11月6日', '8500', '9600', '400', '1000', '1.13'], ['2020年10月30日', '8100', '10600', '100', '1000', '1.31'], ['2020年10月23日', '8000', '11600', '0', '1300', '1.45'], ['2020年10月16日', '8000', '10300', '200', '1800', '1.29'], ['2020年10月9日', '8200', '8500', '400', '100', '1.04'], ['2020年10月2日', '7800', '8600', '100', '1300', '1.10'], ['2020年9月25日', '7900', '9900', '500', '3100', '1.25'], ['2020年9月18日', '7400', '13000', '400', '1100', '1.76'], ['2020年9月11日', '7800', '11900', '3700', '1000', '1.53'], ['2020年9月4日', '11500', '10900', '100', '1500', '0.95'], ['2020年8月28日', '11600', '9400', '100', '100', '0.81'], ['2020年8月21日', '11500', '9300', '1800', '300', '0.81'], ['2020年8月14日', '13300', '9600', '100', '2300', '0.72']] [['2020年8月7日', '13400', '11900', '600', '2100', '0.89'], ['2020年7月31日', '12800', '9800', '0', '500', '0.77'], ['2020年7月24日', '12800', '9300', '300', '1200', '0.73'], ['2020年7月17日', '13100', '10500', '1200', '100', '0.80'], ['2020年7月10日', '11900', '10600', '1700', '800', '0.89'], ['2020年7月3日', '13600', '9800', '1100', '100', '0.72'], ['2020年6月26日', '12500', '9900', '1300', '500', '0.79'], ['2020年6月19日', '13800', '10400', '2700', '300', '0.75'], ['2020年6月12日', '16500', '10100', '900', '500', '0.61'], ['2020年6月5日', '15600', '10600', '1700', '2300', '0.68'], ['2020年5月29日', '17300', '8300', '1700', '300', '0.48'], ['2020年5月22日', '19000', '8000', '200', '900', '0.42'], ['2020年5月15日', '19200', '8900', '1500', '1100', '0.46'], ['2020年5月1日', '17700', '10000', '4200', '200', '0.56'], ['2020年4月24日', '21900', '10200', '200', '2300', '0.47'], ['2020年4月17日', '22100', '12500', '800', '1800', '0.57'], ['2020年4月10日', '22900', '10700', '3900', '700', '0.47'], ['2020年4月3日', '26800', '10000', '90100', '300', '0.37'], ['2020年3月27日', '116900', '9700', '59100', '5300', '0.08'], ['2020年3月20日', '57800', '15000', '700', '10800', '0.26']]
最初の2ページだけをスクレイピングしています。
よって、合計40件の信用残データとなります。
もし、全部のページをスクレイピングしたいなら、次の値を変更します。
# 改ページ(最大) PAGE_MAX = 2
適当に99999に変更すれば、全部のページをスクレイピングします。
まとめ
この記事だけを見ているなら、理解できない箇所があるかもしれません。
例えば、次の箇所。
# ドライバーのフルパス CHROMEDRIVER = "chromedriver.exeのパス" # 改ページ(最大) PAGE_MAX = 2 # 遷移間隔(秒) INTERVAL_TIME = 3
第4弾でも触れていますが、これらの定数は本ブログではあたり前のように用いています。
詳細を知りたい場合は、以下のメルカリのスクレイピングシリーズをご覧ください。
メルカリのスクレイピング第1弾

メルカリのスクレイピング第2弾

メルカリのスクレイピング第3弾
上記記事を一通り読めば、ある程度は理解できるはずです。
あとは、本ブログではスクレイピングに関して多くの記事を載せています。



他にもまだまだあります。
スクレイピングに興味がある方は、「スクレイピング」で本ブログをサイト内検索してみてください。

