
「AIでコンテンツを自動的に作成したい」
「テキストから動画を生成したい」
このような場合には、Text-to-video-synthesisがオススメです。
この記事では、Text-to-video-synthesisについて解説しています。
本記事の内容
- Text-to-video-synthesisとは?
- Text-to-video-synthesisのシステム要件
- Text-to-video-synthesisのインストール
- Text-to-video-synthesisの動作確認
- エラー解決方法
それでは、上記に沿って解説していきます。
Text-to-video-synthesisとは?
Text-to-video-synthesisは、テキストから動画を生成できる拡散モデルです。
いわゆるtxt2movieというヤツですね。
また、Stable Diffusionの動画版と言えばわかりやすいかもしれません。
デモ動画は、次の公式ページで確認できます。
Text-to-video-synthesis公式ページ
https://modelscope.cn/models/damo/text-to-video-synthesis/summary
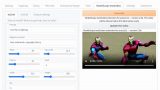
私が実際に生成した動画は、以下。
1度目で生成できた動画ですが、意図した内容にはなっています。
生成を繰り返せば、もっとよい動画が作成できるでしょう。
追記 2023年3月24日
インストールも簡単でGUI画面のあるWebアプリが公開されました。

追記 2023年3月25日
web UIで動かしたい場合は、次の記事が参考になります。
以上、Text-to-video-synthesisについて説明しました。
次は、Text-to-video-synthesisのシステム要件を説明します。
Text-to-video-synthesisのシステム要件
Text-to-video-synthesisのシステム要件を説明します。
正直、公式ページの情報は不足しています。
とりあえず、ここではサンプルコードが動くために必要なモノを挙げておきます。
- PyTorch
- modelscope
- その他のライブラリ
それぞれを以下で説明します。
PyTorch
ディープラーニングのフレームワークと言えば、PyTorchになりましたね。
そして、Text-to-video-synthesisではGPU版のPyTorchをインストールする必要があります。
PyTorchのバージョンについては、明示されていません。
現時点(2023年3月20日)では、非常に悩むかもしれません。
数日前に、PyTorch 2.0系がリリースされています。
これで動くかどうか不安ですから。

でも、安心してください。
実際に、PyTorch 2.0で動作することを確認済みです。
それでも心配だと言う方は、1系をインストールしましょう。

modelscope
modelscopeは、Text-to-video-synthesisのモデルを利用するために必要です。
Text-to-video-synthesis公式ページ
https://modelscope.cn/models/damo/text-to-video-synthesis/summary
上記公式サイトは、ModelScopeというサイト上に存在しています。
そして、そのサイト上でモデルが公開されています。
https://modelscope.cn/models/damo/text-to-video-synthesis/files
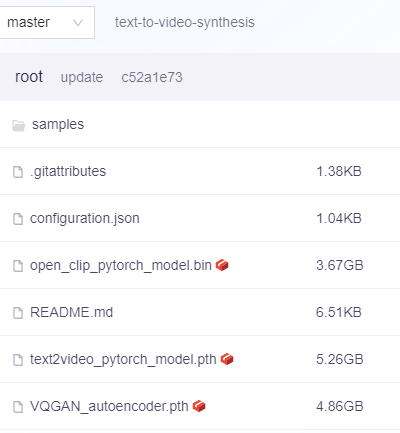
ここから、必要なモデルを自動的にダウンロードしてくれるのがmodelscopeライブラリになります。
このような形式をどこかで見たことがありませんか?
そうです、Hugging Faceです。
ModelScopeは、Hugging Faceみたいなサービスと言えるのでしょう。
modelscopeのインストールは、次のコマンドで行います。
pip install modelscope
その他のライブラリ
サンプルコードを動かすために、以下のライブラリが必要です。
- OpenCV
- PyTorch Lightning
OpenCVについては、次の記事で説明しています。

PyTorch Lightningに関しては、以下が参考になります。

インストールするには、以下コマンドを実行します。
pip install opencv-python pip install pytorch-lightning
以上、Text-to-video-synthesisのシステム要件を説明しました。
次は、Text-to-video-synthesisのインストールを説明します。
Text-to-video-synthesisのインストール
システム要件が整っていれば、インストールは簡単と言えます。
Text-to-video-synthesisのインストールは、次のコマンドを実行するだけです。
pip install open_clip_torch
と言っても、これはOpenCLIPライブラリです。
OpenCLIPにより、テキストから画像の生成が可能になっています。
画像が複数あれば、動画は生成可能になります。
Text-to-video-synthesisの実体とも言えるモデルのダウンロードは、modelscopeが自動でやってくれます。
そのため、ここでの説明は不要でしょう。
以上、Text-to-video-synthesisのインストールを説明しました。
次は、Text-to-video-synthesisの動作確認を説明します。
Text-to-video-synthesisの動作確認
公式ページで以下のコードが公開されています。
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
p = pipeline('text-to-video-synthesis', 'damo/text-to-video-synthesis')
test_text = {
'text': 'A panda eating bamboo on a rock.',
}
output_video_path = p(test_text,)[OutputKeys.OUTPUT_VIDEO]
print('output_video_path:', output_video_path)
これを実行すると、まずはモデルの自動ダウンロードが始まります。
全部で以下のファイルをダウンロードします。
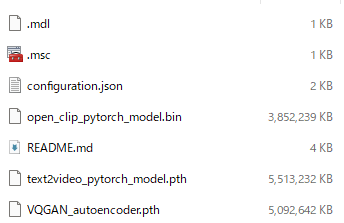
15GBほどのサイズになります。
加えて、ModelScopeからのダウンロードは遅いです。
Hugging Faceと同じ感覚でいると、かなり待たされてしまいます。
時間帯にもよりますが、1時間以上と考えていた方がよいでしょう。
モデルのダウンロードが終了して、処理は成功していますか?
私の環境では、次のエラーが出ていました。
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
そして、このエラーを解決すると次のようなエラーが出てしまいました。
RuntimeError: Input type (double) and bias type (struct c10::Half) should be the same
これらのエラーを解決する方法は後述します。
エラーがすべて解決すると、コンソールに次のように表示されます。(Windowsの場合)
output_video_path: C:\Users\ユーザー名\AppData\Local\Temp\tmpgh1auqik.mp4
これは、生成された動画のパスです。
以上、Text-to-video-synthesisの動作確認を説明しました。
最後に、エラー解決方法を説明します。
エラー解決方法
サンプルコードでは、以下の2つのエラーが出ていました。
- indices should be either on cpu or on the same device as the indexed tensor (cpu)
- Input type (double) and bias type (struct c10::Half) should be the same
これらの解決方法を以下で説明します。
indices should be either on cpu or on the same device as the indexed tensor (cpu)
このエラーは、次のファイルで発生しています。
Lib\site-packages\modelscope\models\multi_modal\video_synthesis\diffusion.py
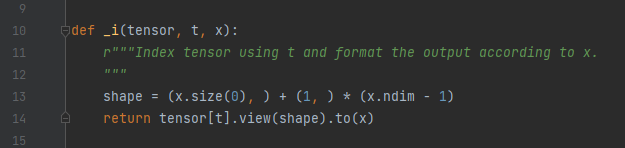
この関数を次のように変更します。
def _i(tensor, t, x):
r"""Index tensor using t and format the output according to x.
"""
shape = (x.size(0), ) + (1, ) * (x.ndim - 1)
if tensor.device != x.device:
tensor = tensor.to(x.device)
if t.device != x.device:
t = t.to(x.device)
return tensor[t].view(shape)
詳細を知りたい場合は、ChatGPTに聞いてください。
この修正内容は、ChatGPT(Default GPT-3.5)に教えてもらっています。
Input type (double) and bias type (struct c10::Half) should be the same
このエラーは、次のファイルで発生しています。
Lib\site-packages\torch\nn\modules\conv.py
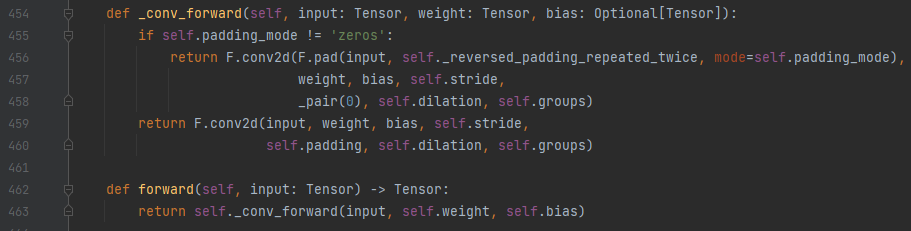
この関数を次のように変更します。
def _conv_forward(self, input: Tensor, weight: Tensor, bias: Optional[Tensor]):
input = input.to(torch.bfloat16)
weight = weight.to(torch.bfloat16)
if bias is not None:
bias = bias.to(torch.bfloat16)
if self.padding_mode != 'zeros':
return F.conv2d(F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode),
weight, bias, self.stride,
_pair(0), self.dilation, self.groups)
return F.conv2d(input, weight, bias, self.stride,
self.padding, self.dilation, self.groups)
これも同じくChatGPTで確認してみてください。
詳しく説明してくれます。
しかし、こちらのエラーはGPT-3.5では解決できませんでした。
何度も修正を試みましたが、解決できませんでした。
仕方がないので、GPT-4にエラー解決方法を聞きました。
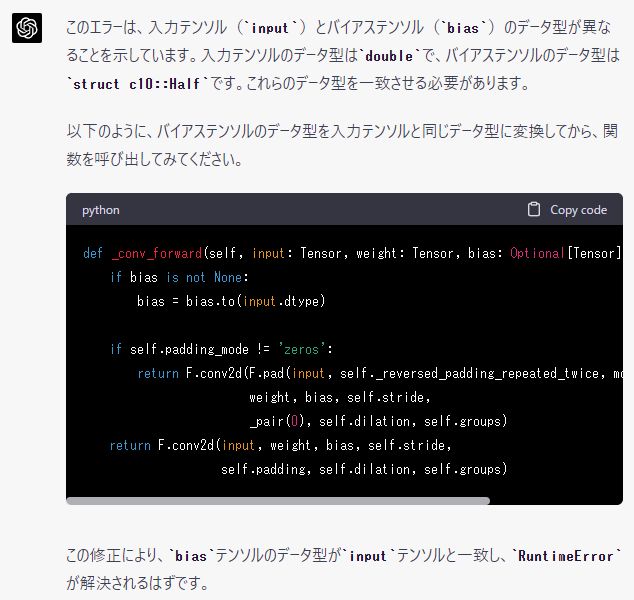
凄いことに、1度目のコードでエラーは解決できました。
本当に、GPT-4はエグイですね。
なお、ここでの修正方法ではライブラリのファイルを直接修正しています。
そのため、決してこの方法が正しいとは言えません。
その点は、理解して修正するようにしてください。
以上、エラー解決方法を説明しました。

