
「コンテンツ生成を効率化したい」
「AIを使ってテキストから動画を生成したい」
このような場合には、Tune-A-Videoがオススメです。
この記事では、Tune-A-Videoのインストールについて解説しています。
本記事の内容
- Tune-A-Videoとは?
- Tune-A-Videoのシステム要件
- Tune-A-Videoのインストール
- Tune-A-Videoの動作確認
それでは、上記に沿って解説していきます。
Tune-A-Videoとは?
Tune-A-Videoとは、テキストからビデオへの変換が可能なモデルのことです。
「テキストからビデオへの変換」について、まずは説明します。
例えば、次のようなテキストを用意します。
Keanu Reeves is surfing in the city
これをTune-A-Videoで動画に変換すると、次のような動画が生成されます。
動画と言っても、GIFアニメですけどね。

このようなことが、Tune-A-Videoを使うと簡単にできるようになります。
簡単にと言っても、動きの部分については学習済みモデルの存在が必要です。
上記で言うと、「is surfing」用の学習済みモデルが必要と言えます。
「is dancing」の動画を作成したいなら、「is dancing」用の学習済みモデルが必要ということです。

学習済みモデルを作成するには、Tune-A-Videoでは動画を用いています。
動画と言っても、たった1つの動画でOKです。
それも3秒程度の再生時間でも問題はありません。
もちろん、品質を求めるなら長い動画の方が良いでしょうけどね。
以上、Tune-A-Videoについて説明しました。
次は、Tune-A-Videoのシステム要件を説明します。
Tune-A-Videoのシステム要件
Tune-A-Videoは、バージョン管理が実施されていません。
2023年1月29日に、Githubでソースが公開されただけの状態です。
showlab/Tune-A-Video: Tune-A-Video
https://github.com/showlab/Tune-A-Video
システム要件としては、特に明記はされていません。
ただ、Windowsで動くことは確認済です。
Windowsで動けば、Linuxは問題なく動くでしょう。
macOSも問題ないとは思います。
Pythonのバージョンに関しては、Python公式開発サイクルに従っておきましょう。
| バージョン | リリース日 | サポート期限 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
| 3.11 | 2022年10月25日 | 2027年10月 |
あと、PyTorchは事前にインストールしておきましょう。
GPU版PyTorchでないと、おそらくまともには動かないはずです。
そのため、GPU版PyTorchをインストールします。

現時点では、1.13.1が最新バージョンとなります。
PyTorchは、なるべく最新版を利用することをオススメします。
また、xFormersのインストールが推奨されています。
xFormersは必須ではなく、オプションとなります。
Windowsへのインストールについては、次の記事で説明しています。

以上、Tune-A-Videoのシステム要件を説明しました。
次は、Tune-A-Videoのインストールを説明します。
Tune-A-Videoのインストール
Tune-A-Videoのインストールは、Python仮想環境の利用をオススメします。
Python仮想環境は、次の記事で解説しています。

検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
そして、システム要件であるGPU版PyTorchをインストール済という状況です。
このような状況において、次の手順でTune-A-Videoのインストールを進めます。
- Tune-A-Videoの取得(GitHubから)
- requirements.txtを使った一括インストール
それぞれを下記で説明します。
Tune-A-Videoの取得(GitHubから)
次のコマンドでGitHUbからリポジトリを取得します。
git clone https://github.com/showlab/Tune-A-Video.git
リポジトリをダウンロードできたら、リポジトリルートへ移動しておきます。
cd Tune-A-Video
基本的には、このリポジトリルートで作業を行います。
requirements.txtを使った一括インストール
リポジトリルートにおいて、以下のファイルを確認できます。
requirements.txt
torch==1.12.1 torchvision==0.13.1 diffusers[torch]==0.11.1 transformers>=4.25.1 bitsandbytes==0.35.4 decord==0.6.0 accelerate tensorboard modelcards omegaconf einops imageio ftfy
事前にPyTorchはインストール済みです。
そのため、PyTorch関連はコメントにします。
#torch==1.12.1 #torchvision==0.13.1
ファイルを変更できたら、次のコマンドで一気にインストールしましょう。
pip install -r requirements.txt
インストールには、そこまで時間がかからないはずです。
以上、Tune-A-Videoのインストールを説明しました。
次は、Tune-A-Videoの動作確認を説明します。
Tune-A-Videoの動作確認
Tune-A-Videoの動作確認とは、以下の処理を指します。
- 学習(Training)
- 推論(Inference)
それぞれを以下で説明します。
学習(Training)
「is surfing」の動画生成には、「is surfing」用の学習済みモデルが必要と述べました。
その学習済みモデルを作成することから、自分で行う必要があります。
学習用の動画や設定ファイルは用意されているので、安心してください。
まずは、学習に必要なStable Diffusionモデルを用意します。
そのモデルを設置するディレクトリをリポジトリルートで作成しましょう。
mkdir checkpoints
作成したディレクトリへ移動。
cd checkpoints
移動先で次のコマンドを実行。
このコマンドでStable Diffusionモデルをダウンロードできます。
git lfs install git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
ここでは、しばらく時間がかかります。
ダウンロードできたら、次のような構成になります。
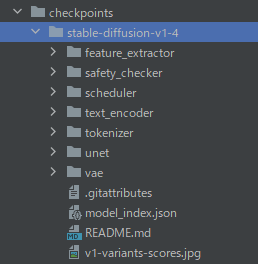
ところで、「なぜ、stable-diffusion-v1-4なんだ?」という疑問はあるでしょう。
疑問はあっても、初めは公式の手順通りに進めましょう。
そうしないと、何かトラブルがあったときに原因究明に時間がかかります。
では、一旦リポジトリルートに戻りましょう。
cd ..
リポジトリルートにおいて、次のコマンドによって学習を行います。
accelerate launch train_tuneavideo.py --config="configs/man-surfing.yaml"
「accelerate launch」が機能しない場合は、次の記事で確認してみてください。

次のように学習が開始されれば、あとは待つだけです。
Steps: 5%|███
マシンスペックによると思いますが、私の環境では10分ほどかかりました。
なお、GPU環境は以下となります。
> python -m xformers.info WARNING:root:A matching Triton is not available, some optimizations will not be enabled. Error caught was: No module named 'triton' xFormers 0.0.14.dev memory_efficient_attention.flshatt: available - requires GPU with compute capability 7.5+ memory_efficient_attention.cutlass: available memory_efficient_attention.small_k: available is_triton_available: False is_functorch_available: False pytorch.version: 1.13.1+cu116 pytorch.cuda: available gpu.compute_capability: 8.6 gpu.name: NVIDIA GeForce RTX 3090
学習が完了すると、「output」ディレクトリ以下は次のようになっているはずです。
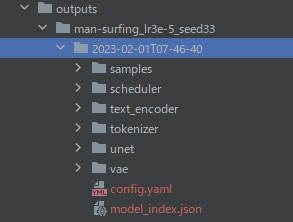
「2023-02-01T07-46-40」が、学習済みモデルとなります。
保存場所は、「man-surfing.yaml」に記載されています。

推論(Inference)
学習済みモデルが準備できたら、推論が可能になります。
公式で公開されているコードを少し変更しています。
from tuneavideo.pipelines.pipeline_tuneavideo import TuneAVideoPipeline
from tuneavideo.models.unet import UNet3DConditionModel
from tuneavideo.util import save_videos_grid
import torch
save_dir = "./gif/"
model_id = "path-to-your-trained-model"
unet = UNet3DConditionModel.from_pretrained(model_id, subfolder='unet', torch_dtype=torch.float16).to('cuda')
pipe = TuneAVideoPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", unet=unet, torch_dtype=torch.float16).to("cuda")
prompt = "a panda is surfing"
video = pipe(prompt, video_length=8, height=512, width=512, num_inference_steps=50, guidance_scale=7.5).videos
save_videos_grid(video, save_dir + f"{prompt}.gif")
このコードは、基本的にはリポジトリルートで実行することが想定されています。
そのため、「test_Inference.py」としてリポジトリルートに保存します。
以下は、先ほど作成した学習済みモデルのパスに変更しましょう。
model_id = "path-to-your-trained-model"
↓
model_id = "./outputs/man-surfing_lr3e-5_seed33/2023-02-01T07-46-40"
そして、実行前に「gif」ディレクトリをリポジトリルートに作成しておきます。
ここに生成された動画が保存されることになります。
また、「”CompVis/stable-diffusion-v1-4″」が気になるかもしれません。
ここも、まずは公式の通りに行きましょう。
コードを実行すると、「”CompVis/stable-diffusion-v1-4″」のダウンロードが始まります。
これは、初回時(キャッシュに存在しない場合)のお約束です。
動画生成の処理自体は、30秒程度で終わっています。
これもマシンスペックに依存します。
処理が完了すると、「gif」の下にファイルが保存されていることを確認できます。
指定したプロンプトが、ファイル名になる仕様です。
実行日時をファイル名に足してもよいかもしれません。
生成されたGIFアニメは、以下。

これは、そこそこいい感じで生成できましたね。
以上、Tune-A-Videoの動作確認を説明しました。

