
上場企業サイトのURL一覧は、探してみると案外ありません。
だからこそ、価値があるのでしょう。
「上場企業ホームページ一覧」
「上場企業WebサイトURL一覧提供サービス」
上記キーワードで検索すると、有料のサービスが出てきます。
それもそこそこな金額で販売されています。
需要があるから、供給があるということでしょう。
需要があるなら、この記事はきっと誰かの役に立つはずです。
この記事では、上場企業サイトのURL一覧を作成する方法を紹介します。
本記事の内容
- 上場企業サイトのURL一覧を作成するために必要なスキル・知識
- 上場企業サイトのURL一覧を作成する方法
- 株探をスクレイピングするための準備
- 株探をスクレイピングしてサイトURLを取得する
それでは、上記に沿って解説していきます。
上場企業サイトのURL一覧を作成するために必要なスキル・知識
プログラミングができることは、必須となります。
あとは、Pythonを触れることも条件となります。
Pythonに関しては、なんとなくわかる程度でも大丈夫です。
サンプルコード付きで説明するため、なんとかなります。
とりあえず、プログラミングできることが大前提です。
あとは、スクレイピングに対する正しい理解が必要になります。
次の記事の「【必須】Webスクレイピングに関する考え方」を確認してください。

スクレイピングを行うすべての人が理解しておくべき内容となります。
その内容を理解しておかないと、法律で裁かれることすらあり得ます。
以上、URL一覧を作成するために必要なスキルと知識についての説明でした。
次は、URL一覧を作成していくための方法を説明します。
上場企業サイトのURL一覧を作成する方法
株探(かぶたん)をスクレイピングします。
株探には、企業毎にページが用意されています。
例えば、キャノンの企業ページは以下のURLです。
https://kabutan.jp/stock/?code=7751
上記ページには、「会社情報」という項目があります。
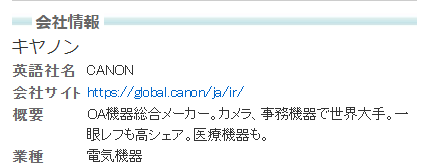
「会社サイト」には、サイトURLが記載されています。
これをスクレイピングするのです。
ここまでの処理をまとめます。
- 株探上の企業ページへアクセスする
- 企業ページからサイトURLを抽出する
上記の処理を企業数分だけ繰り返します。
その結果、全上場企業のサイトURLを集めることができます。
どうですか?
上場企業サイトのURL一覧を作成できそうですか?
実は、一つ重要なことが抜けています。
それは、株探上の企業ページのURLを用意することです。
https://kabutan.jp/stock/?code=7751
上記はキャノンのURLです。
このようなURLを企業分だけ用意する必要があります。
通常は、業種別企業一覧ページをスクレイピングすることになります。
しかし、株探は非常にシンプルな構成となっています。
https://kabutan.jp/stock/?code=●●●
「●●●」部分が、証券コードなのです。
したがって、証券コード一覧さえ手に入ればそれで解決します。
東証だけなら、以下ページから取得可能です。
https://www.jpx.co.jp/markets/statistics-equities/misc/01.html
地道に各取引所の証券コードを集めていくのも一つの手でしょう。
しかし、さすがに面倒です。
そのため、スクレイピングで集めます。
次の記事を参考にすれば、証券コード一覧が手に入ります。

なお、銘柄コードは証券コードと同じです。
以上、上場企業サイトのURL一覧を作成する方法を説明しました。
次は、株探をスクレイピングするための準備について確認します。
株探をスクレイピングするための準備
証券コード一覧を取得するために、すでに準備しているかもしれません。
念のため、ここでも説明しておきます。
利用する言語は、Pythonです。
そして、必要なライブラリは以下。
- Selenium
- BeautifulSoup4
- lxml
下記で説明します。
Selenium
正直、株探にはSeleniumは必要ないかもしれません。
でも、スクレイピングする際には必須だと考えてください。
Seleniumのインストールは、次の記事で解説しています。

上の記事では、Windowsへのインストールに関してです。
Linux(Ubuntu)へのインストールは、次の記事でまとめています。

BeautifulSoup4
BeautifulSoup4は、HTMLから情報を抽出するために利用しています。
BeautifulSoup4のインストールは、次の記事で解説しています。

lxml
HTMLを解析する際に利用するパーサーです。
BeautifulSoup4で利用します。
lxmlは標準パーサーよりも処理が高速です。
そのため、標準のパーサーを使わずにlxmlを使います。
インストールは、以下のコマンドで簡単に入ります。
pip install lxml
まとめ
Seleniumだけでも抽出は可能です。
しかし、BeautifulSoup4を使った方がコーディングが綺麗にできます。
「餅は餅屋」ということです。
Webページへのアクセスは、Seleniumに任せます。
そして、Seleniumが取得したHTMLをBeautifulSoup4が処理します。
さらには、BeautifulSoup4ではlxmlをパーサーとして利用します。
そのことにより、HTML解析が標準パーサーよりも高速になります。
以上、株探をスクレイピングするための準備について説明しました。
最後は、株探をスクレイピングしてサイトURLを取得します。
株探をスクレイピングしてサイトURLを取得する
コピペで動くサンプルコードです。
これをベースにして、各自で使いやすいようにカスタマイズしてください。
import bs4
import traceback
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 3
# 遷移間隔(秒)
INTERVAL_TIME = 2
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
page_source = driver.page_source
return page_source
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
try:
info = None
base_elem = soup.find("div", class_="company_block")
if base_elem:
company_name = None
company_url = None
h3_elem = base_elem.find("h3")
if h3_elem:
company_name = h3_elem.text
tr_elems = base_elem.find_all("tr")
for elem in tr_elems:
th_tag = elem.find("th")
if th_tag:
th_text = th_tag.text
if th_text == "会社サイト":
a_tag = elem.find("a")
if a_tag:
company_url = a_tag.attrs['href']
info = {"name": company_name,
"url": company_url}
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# 証券コード一覧取得
def get_code_list():
# MongoDBなどに保存したデータを取得するの形が理想
result = ['1375', '1376', '1377', '1379', '1380', '1381', '1382', '1383', '1384']
return result
if __name__ == "__main__":
# 証券コード一覧
code_list = get_code_list()
base_url = "https://kabutan.jp/stock/?code="
# ブラウザのdriver取得
driver = get_driver()
# ページカウンター制御
page_counter = 0
for code in code_list:
page_counter = page_counter + 1
target_url = base_url + str(code)
# ページのソース取得
source = get_source_from_page(driver, target_url)
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存(MongoDBなどへの保存が理想)
print(data)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
# 閉じる
driver.quit()
上記を実行すると、以下の表示となります。
{'name': '雪国まいたけ', 'url': 'https://www.maitake.co.jp/'}
{'name': 'カネコ種苗', 'url': 'http://www.kanekoseeds.jp/'}
{'name': 'サカタのタネ', 'url': 'https://www.sakataseed.co.jp/'}
以下で最大3社分までしかスクレイピングしないように制御しています。
# 改ページ(最大) PAGE_MAX = 3 # 遷移間隔(秒) INTERVAL_TIME = 2
全上場企業の証券コードさえ用意できれば、上場企業サイトURL一覧を作成できます。
あと、その際はPAGE_MAXを適当に10000などの大きな数字に変更します。
また、ページへアクセスする間隔は2秒です。
最低でも1秒は間隔を取るようにしましょう。
なお、株探が利用しているサーバーは「AMAZON-02, US」です。
AWSを使っていると推測されます。
そのため、かなり強いサーバーと言えます。
だからと言って、時間間隔を設けないページアクセスはNGです。
以上、株探のスクレイピングについてサンプルコードを元に説明しました。

