「RAGシステムを作ってください」
この依頼を受けたとき、あなたはどんなシステムを想像しますか?
おそらく、文書を検索して関連情報を返すシンプルなシステムでしょう。
しかし、これが大きな落とし穴なのです。
最近、Redditで話題になった投稿があります。
複数の本番環境向けRAGシステムを構築したエンジニアが、ある重要な気づきを共有していました。
「誰も単純なRAGなんて求めていない」と。
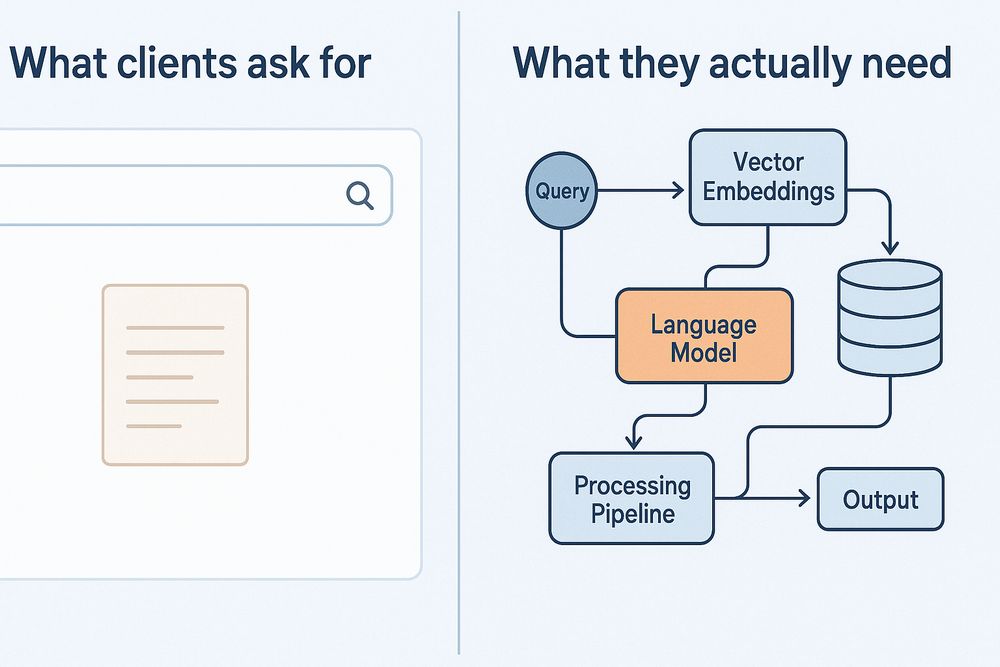
ユーザーが本当に欲しいもの
企業がRAGシステムに求めるものは、想像以上に複雑です。
彼らが欲しいのは、ChatGPTのような使い心地でありながら、社内データに基づいた正確な回答を返すシステムです。
ある開発者のコメントが印象的でした。
会社のドキュメントをRAG化してくれと頼まれた。 でも要求はそれだけじゃない。 コード分析も必要だし、類似文書の生成も必要だ。 そして、完全にオフラインで動作する必要がある。 週を追うごとに要求は増えていく
これが現実です。
単純な文書検索システムを期待していた開発者は、次々と追加される要求に圧倒されることになります。
Agentic RAGという解決策
この問題に対する答えが「Agentic RAG」というアプローチです。
従来のRAGとは何が違うのでしょうか。
最大の違いは、システムが意図を理解し、クエリを再構成する能力にあります。
例を見てみましょう。
ユーザーが「私は東京在住のフリーランスエンジニアです。確定申告の要件を教えてください」と質問したとします。
単純なRAGは「確定申告」「要件」といったキーワードで検索します。
その結果、一般的な確定申告の情報を返すでしょう。
しかし、これでは不十分です。
Agentic RAGは違います。
まず質問を分析します。
そして、以下のように理解するのです:
- ユーザーは東京在住である
- フリーランスエンジニアである
- 確定申告の要件、特に自分の状況に特化した情報が必要
その上で、複数のクエリに分解して検索を実行します。
たとえば「フリーランス 確定申告」「個人事業主 経費計上」「東京都 税務署」など、文脈に応じた検索を行うのです。
本番環境での技術的課題
理想と現実のギャップは大きいものです。
本番環境でRAGシステムを運用するには、多くの技術的課題を解決する必要があります。
ある開発者は、Graph RAGとベクトル検索を組み合わせたシステムを構築したと共有していました。
ベクトル検索がうまく機能しない場合のフォールバックとして、通常の検索を用意しています。
さらに、PostgreSQLでメタデータによる検索精度の向上を図っているそうです。
別の開発者は、多言語対応の課題について詳しく説明していました。
メールメッセージのRAGシステムを構築する際、以下のような処理フローを実装したといいます。
まず、ユーザーのクエリから会話的な要素を除去します。
そして、核心的な質問を抽出するのです。
次に、その質問がRAGに適しているかチェックします。
不適切な場合は、ユーザーに別の方法を提案します。
適切な場合は、データの5%以上を占める言語すべてにクエリを翻訳します。
そして、各言語で仮想的なメール文書を生成するのです。
その後、ハイブリッド検索を実行します。
BM25による従来型の検索と、ベクトル検索を組み合わせ、結果を統合します。
最後にリランキングを行い、スコアの低い結果をフィルタリングしてからLLMに渡すのです。
このような複雑な処理が必要になる理由は明確です。
現実のデータは整理されていません。
複数の言語が混在し、文脈が複雑で、ノイズも多いのです。
単純な検索では、ユーザーが求める情報にたどり着けません。
なぜ既存ソリューションを使わないのか
「なぜ車輪の再発明をするのか」という疑問も出てきます。
確かに、RAGサービスを提供する企業は増えています。
しかし、企業には独自の要求があります。
完全にオフラインで動作する必要がある。
特定のデータ形式に対応する必要がある。
既存システムとの統合が必須である。
これらの要求を満たすには、カスタム開発が避けられないケースが多いのです。
ただし、すべてを自前で作る必要はありません。
オープンソースのフレームワークやツールを活用しながら、自社の要件に合わせてカスタマイズする。
そんなハイブリッドなアプローチが現実的でしょう。
ユーザー期待値の管理
技術的な課題と同じくらい重要なのが、ユーザーの期待値管理です。
あるコメントが的を射ていました。
ユーザーは自分たちのドキュメントについて何でも知っているAIがいると思っている。 そして、複雑な推論が必要な質問を投げかける。 しかし、システムがどこまで対応できるか、開発者でさえ正確には分からない
この問題に対処するには、システムの限界を明確に伝えることが重要です。
RAGシステムは魔法ではありません。
統計的な手法に基づいています。
そして、必ずしも完璧な答えを返せるわけではないのです。
実装のベストプラクティス
実際の開発現場から得られた知見をまとめると、以下のようなアプローチが効果的だとわかります。
クエリの前処理を徹底する
ユーザーの質問をそのまま使うのではありません。
意図を分析し、適切に再構成します。
複数の検索手法を組み合わせる
キーワード検索、ベクトル検索、グラフ検索など、それぞれの強みを活かします。
フォールバック機構を用意する
一つの手法が失敗しても、別の手法で補完できるようにします。
コンテキストの管理を工夫する
単なるチャンクではありません。
周辺の文脈も含めてLLMに渡します。
継続的な改善サイクルを回す
ユーザーのフィードバックを収集します。
そして、システムを改良し続けます。
まとめ
RAGシステムの本番環境での構築は、想像以上に複雑な作業です。
単純な文書検索を超えて、ユーザーの意図を理解し、適切な情報を提供するシステムを作る必要があります。
技術的には、Agentic RAGのようなアプローチが有効です。
クエリの再構成、複数の検索手法の組み合わせ、適切な前処理と後処理。
これらを適切に実装することで、ユーザーが求める体験に近づけます。
しかし同時に、システムの限界を認識することも重要です。
そして、ユーザーの期待値を適切に管理する必要があります。
RAGシステムは強力なツールです。
しかし、万能ではありません。
最後に、ある開発者の言葉を紹介します。
RAGシステムの構築は、たくさんのコツと工夫の積み重ね。 こういった経験を共有し、議論することが最も楽しく、価値があることだ
この記事が、RAGシステムを構築する皆さんの参考になれば幸いです。
現実は厳しいかもしれません。
しかし、適切なアプローチと継続的な改善により、価値あるシステムを作ることは可能なのです。

