
「RVCの使い方がよくわからない・・・」
「質の高い学習データをどこで手に入れることができるの?」
このような場合には、この記事の内容が参考になります。
この記事では、RVCの使い方を解説しています。
本記事の内容
- RVCのインストール
- 学習データの用意
- モデルの作成
- 推論の実行
それでは、上記に沿って解説していきます。
RVCのインストール
前提として、RVCのインストールは済みとします。
インストールがまだの場合は、次の記事をご覧ください。

なお、現時点ではGUIツールが日本語化されています。
RVC起動時に、言語の設定が自動で行われていることを確認できます。

おそらく、OSの言語環境より判別していると思われます。
それでも、中国語が所々に残っています。
まあ、操作を行う上で支障がないレベルだと言えるでしょう。
つまり、十分に使えるレベルです。
以上、RVCのインストールを説明しました。
次は、学習データの用意を説明します。
学習データの用意
RVCの利用においては、学習データを用意することが最も難易度が高いです。
そもそも、学習に適した音声データがなかなか存在していません。
あったとしても、著作権の問題がつきまといます。
と言っても、AIによる学習が著作権違反になるかどうかはまだまだわかりません。
とりあえず、私的利用に留めておけば著作権の侵害にはならないでしょう。
このことを頭に入れて、学習データの用意を行います。
ここでは、説明のために次のサイトのデータを利用します。
ここの朗読データは、学習素材という点で質が高いです。
余計な効果音も背景音も含まれていません。

10分以上あれば、学習データとしては十分と言われています。
適当なデータを選んで、ダウンロードしましょう。

ダウンロードしたファイルは、そのままでも利用は可能です。
しかし、無音を除去した方が学習データとしての質はUPします。
無音を除去するには、ツールを使う方法があるようです。
私は、次のようなプログラムで自動的にやってしまいます。
今回、ダウンロードしたファイルはMP3でした。
そのままでは利用できないので、WAVに一旦変換しています。
その際、変換にはFFmpegを利用します。
ffmpeg -i rd1029.mp3 output.wav
FFmpegのインストールは、以下の記事で解説しています。


プログラムを利用して無音を除去すると、多くのファイルに分割されます。
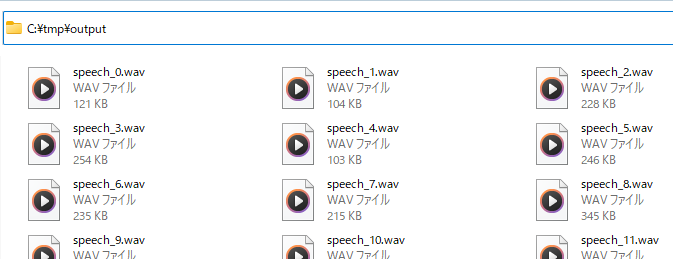
全部で、226個の音声ファイルがディレクトリ以下に保存されています。

ここまでやれば、学習データの用意はOKです。
以上、学習データの用意を説明しました。
次は、モデルの作成を説明します。
モデルの作成
RVCを起動して、「トレーニング」タブを開きます。

まず、次の2か所に入力を行います。
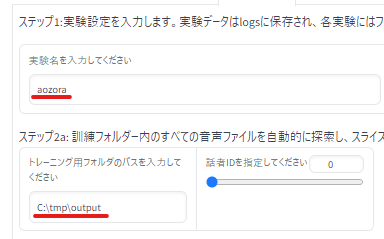
実験名は、モデル名です。
わかりやすい名称を入力します。
パスは、226個の音声ファイルが保存されているディレクトリのフルパスとなります。
CPUとかGPUの項目は、何も変更する必要はありません。
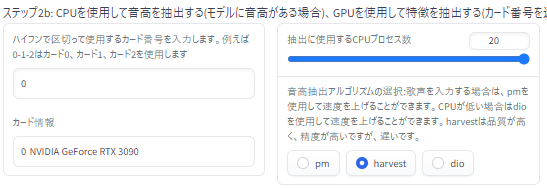
ここの値は、各自の利用環境から自動的に設定されているはずです。
ステップ3の項目は、モデルの精度を上げたい場合に変更しましょう。

デフォルトの設定でも、学習データ次第で十分です。
設定が完了したら、次のボタンをクリックします。

「出力情報」に状況ログが表示されます。
しかし、動いているかどうか不安になるレベルで画面上は動きがありません。
そのような場合は、GPUの利用状況を確認します。
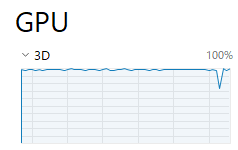
このように100%近くで稼働していれば、処理中だとわかります。
処理が完了すると、一気に0%(他でGPUが未利用の場合)になります。
また、「出力情報」も以下のように表示されます。

「全流程结束」は、「全プロセス終了」という意味です。
これでモデルの作成が完了となります。
ちなみに、学習に要した時間は9分です。
学習データは、次のファイルがベースになります。
これを226個のファイルに分割しています。
この時間は、あくまで参考程度に考えてください。
各自の環境によって、それぞれ時間は異なるでしょうから。
以上、モデルの作成を説明しました。
次は、推論の実行を説明します。
推論の実行
推論を実行する前に、音声変換したい音声ファイルを用意しましょう。
ここでも、青空朗読を利用します。

再生時間が短くて、女性の声の音声ファイルが動作確認としては最適です。
では、推論を実行していきます。
「モデル推論」タブを開きます。
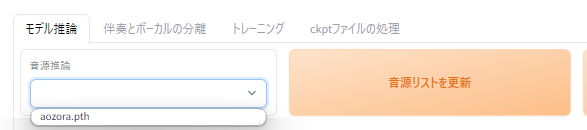
ここで、「音源リストを更新」ボタンをクリック。
そうすると、「音源推論(モデル)」に先ほど作成したモデルが候補に出てきます。
もちろん、作成したモデルを選択します。
そして、処理対象音声ファイルに、女性の声の朗読データを設定します。
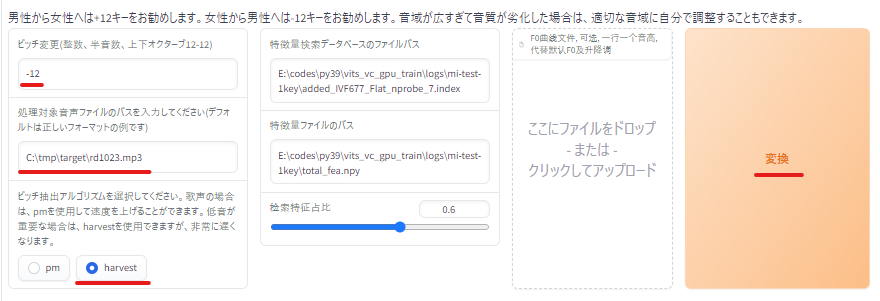
このとき、ピッチを「-12」に変更しておきます。
女性の声を男性の声へ変更するからです。
また、ピッチアルゴリズムも変更します。
「harvest」の方が、総じて精度が良くなります。
それ以外は、特に何も変更しなくてOK。
設定が完了したら、「変換」ボタンをクリック。
「出力情報」に「Success」と出れば、処理は成功です。
音声ファイルを再生して、その場で確認できます。
なお、この音声ファイルは公開しません。
本当は、公開したいほどに驚く精度です。
是非とも、私的利用の範囲でこの成果を確認してみてください。
以上、推論の実行を説明しました。

