
AI技術の進化は止まらない。
最新の動画生成AIモデル「Stable Video Diffusion」が話題となっています。
この記事では、Stable Video Diffusionの導入方法をわかりやすく解説します。
動画生成の可能性を広げるこのモデルの魅力と、実際に手に取って使ってみる方法について詳しく見ていきましょう。
本記事の内容
- Stable Video Diffusionとは?
- Stable Video Diffusionのシステム要件
- Stable Video Diffusionのインストール
- Stable Video Diffusionの動作確認
それでは、上記に沿って解説していきます。
Stable Video Diffusionとは?
Stable Video Diffusionとは、動画生成のためのAIモデルです。
既存の画像モデル「Stable Diffusion」を基に開発されました。
このモデルは、単一の画像から複数の視点を持つ動画を生成するなど、多様なタスクに対応しています。
14フレームや25フレームの動画を生成でき、フレームレートも3~30フレーム/秒とカスタマイズ可能です。
現時点では、商用アプリケーションでの使用は意図されておらず、研究用途に限られています。
能書きはこれぐらいにして、実際にどんなことができるのかを説明します。
以下のような動画を簡単に生成できます。
この動画の作成には、1枚の画像を用意しただけです。
その画像は、以下の記事で説明した方法で生成した画像になります。

画像をアップロードして、ボタンをクリックしただけです。
2分程度待っただけで、上記のような動画が作成できました。
Stable Video Diffusionのシステム要件
現状、WindowsでStable Video Diffusionを動かすにはいろいろ制約があります。
おそらく、時間の経過とともにその制約も解消されていくとは思います。
とりあえず、現時点(2023年11月末)では以下をクリアすればOKと言えます。
- Python 3.10
- PyTorch 2.0.1
- Triton 2.0.0
Pythonのバージョンについては、Tritonが関係しています。
Tritonは、Windowsへのインストールが前提とされていません。
そのため、Windowsへのインストールはかなり難易度が高いです。
しかし、簡単にインストールできるようなパッケージを用意してくれている開発者がいます。
ただし、それはPython 3.10でのみ有効です。
そのパッケージをインストールするために、Pythonのバージョンが制約されています。
> python -V Python 3.10.4
また、torchdataやxformersのためにPyTorch 2.0.1である必要があります。
インストールには、以下のコマンドを用いています。
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
GPU版PTorchのインストールは、以下の記事で解説しています。

最後は、例のTritonです。
以下のコマンドを実行すれば、Triton 2.0.0がインストールされます。
pip install https://huggingface.co/r4ziel/xformers_pre_built/resolve/main/triton-2.0.0-cp310-cp310-win_amd64.whl
ここまでは、事前に準備しておきましょう。
なお、Python仮想環境の利用をオススメします。

Stable Video Diffusionのインストール
事前準備が終わっていれば、あとは簡単です。
まずは、プロジェクトをダウンロードします。
git clone https://github.com/Stability-AI/generative-models.git cd generative-models
そして、リポジトリルートへ移動しておきます。
「requirements」ディレクトリの下に次のファイルを確認できます。
pt2.txt
black==23.7.0 chardet==5.1.0 clip @ git+https://github.com/openai/CLIP.git einops>=0.6.1 fairscale>=0.4.13 fire>=0.5.0 fsspec>=2023.6.0 invisible-watermark>=0.2.0 kornia==0.6.9 matplotlib>=3.7.2 natsort>=8.4.0 ninja>=1.11.1 numpy>=1.24.4 omegaconf>=2.3.0 open-clip-torch>=2.20.0 opencv-python==4.6.0.66 pandas>=2.0.3 pillow>=9.5.0 pudb>=2022.1.3 pytorch-lightning==2.0.1 pyyaml>=6.0.1 scipy>=1.10.1 streamlit>=0.73.1 tensorboardx==2.6 timm>=0.9.2 tokenizers==0.12.1 torch>=2.0.1 torchaudio>=2.0.2 torchdata==0.6.1 torchmetrics>=1.0.1 torchvision>=0.15.2 tqdm>=4.65.0 transformers==4.19.1 triton==2.0.0 urllib3<1.27,>=1.25.4 wandb>=0.15.6 webdataset>=0.2.33 wheel>=0.41.0 xformers>=0.0.20
これを次のコマンドでインストールします。
pip install -r requirements/pt2.txt
事前準備に従っていれば、エラーなく終了するはずです。
問題なければ、以下のコマンドを実行します。
pip install .
このコマンドにより、sgm(Stable Video Diffusion)が利用可能になります。
以下も実行しておきます。
pip install -e git+https://github.com/Stability-AI/datapipelines.git@main#egg=sdata
学習のためのデータと説明があります。
そんなに大きなサイズではないので、気にせずインストールします。
これでStable Video Diffusionのインストールは完了です。
Stable Video Diffusionの動作確認
公式ページでは、「scripts/demo/video_sampling.py」がデモとして提供されています。
しかし、Windowsではまともに動きません。
そこで、調べてみると次のようにハックしている人がいました。
ほぼ内容は変わりませんが、少し変更しています。
test_svd.py
import sys
sys.path.append("generative-models")
import os, math, torch, cv2
from omegaconf import OmegaConf
from glob import glob
from pathlib import Path
from typing import Optional
import numpy as np
from einops import rearrange, repeat
from PIL import Image
from torchvision.transforms import ToTensor
from torchvision.transforms import functional as TF
from sgm.util import instantiate_from_config
def load_model(config: str, device: str, num_frames: int, num_steps: int):
config = OmegaConf.load(config)
config.model.params.conditioner_config.params.emb_models[0].params.open_clip_embedding_config.params.init_device = device
config.model.params.sampler_config.params.num_steps = num_steps
config.model.params.sampler_config.params.guider_config.params.num_frames = (num_frames)
with torch.device(device):
model = instantiate_from_config(config.model).to(device).eval().requires_grad_(False)
return model
num_frames = 25
num_steps = 30
model_config = "generative-models/scripts/sampling/configs/svd_xt.yaml"
device = "cuda" if torch.cuda.is_available() else "cpu"
model = load_model(model_config, device, num_frames, num_steps)
model.conditioner.cpu()
model.first_stage_model.cpu()
model.model.to(dtype=torch.float16)
torch.cuda.empty_cache()
model = model.requires_grad_(False)
def get_unique_embedder_keys_from_conditioner(conditioner):
return list(set([x.input_key for x in conditioner.embedders]))
def get_batch(keys, value_dict, N, T, device, dtype=None):
batch = {}
batch_uc = {}
for key in keys:
if key == "fps_id":
batch[key] = (
torch.tensor([value_dict["fps_id"]])
.to(device, dtype=dtype)
.repeat(int(math.prod(N)))
)
elif key == "motion_bucket_id":
batch[key] = (
torch.tensor([value_dict["motion_bucket_id"]])
.to(device, dtype=dtype)
.repeat(int(math.prod(N)))
)
elif key == "cond_aug":
batch[key] = repeat(
torch.tensor([value_dict["cond_aug"]]).to(device, dtype=dtype),
"1 -> b",
b=math.prod(N),
)
elif key == "cond_frames":
batch[key] = repeat(value_dict["cond_frames"], "1 ... -> b ...", b=N[0])
elif key == "cond_frames_without_noise":
batch[key] = repeat(
value_dict["cond_frames_without_noise"], "1 ... -> b ...", b=N[0]
)
else:
batch[key] = value_dict[key]
if T is not None:
batch["num_video_frames"] = T
for key in batch.keys():
if key not in batch_uc and isinstance(batch[key], torch.Tensor):
batch_uc[key] = torch.clone(batch[key])
return batch, batch_uc
def sample(
input_path: str = "/content/test_image.png",
resize_image: bool = False,
num_frames: Optional[int] = None,
num_steps: Optional[int] = None,
fps_id: int = 6,
motion_bucket_id: int = 127,
cond_aug: float = 0.02,
seed: int = 23,
decoding_t: int = 14, # Number of frames decoded at a time! This eats most VRAM. Reduce if necessary.
device: str = "cuda",
output_folder: Optional[str] = "/content/outputs",
):
"""
Simple script to generate a single sample conditioned on an image `input_path` or multiple images, one for each
image file in folder `input_path`. If you run out of VRAM, try decreasing `decoding_t`.
"""
torch.manual_seed(seed)
path = Path(input_path)
all_img_paths = []
if path.is_file():
if any([input_path.endswith(x) for x in ["jpg", "jpeg", "png"]]):
all_img_paths = [input_path]
else:
raise ValueError("Path is not valid image file.")
elif path.is_dir():
all_img_paths = sorted(
[
f
for f in path.iterdir()
if f.is_file() and f.suffix.lower() in [".jpg", ".jpeg", ".png"]
]
)
if len(all_img_paths) == 0:
raise ValueError("Folder does not contain any images.")
else:
raise ValueError
all_out_paths = []
for input_img_path in all_img_paths:
with Image.open(input_img_path) as image:
if image.mode == "RGBA":
image = image.convert("RGB")
if resize_image and image.size != (1024, 576):
print(f"Resizing {image.size} to (1024, 576)")
image = TF.resize(TF.resize(image, 1024), (576, 1024))
w, h = image.size
if h % 64 != 0 or w % 64 != 0:
width, height = map(lambda x: x - x % 64, (w, h))
image = image.resize((width, height))
print(
f"WARNING: Your image is of size {h}x{w} which is not divisible by 64. We are resizing to {height}x{width}!"
)
image = ToTensor()(image)
image = image * 2.0 - 1.0
image = image.unsqueeze(0).to(device)
H, W = image.shape[2:]
assert image.shape[1] == 3
F = 8
C = 4
shape = (num_frames, C, H // F, W // F)
if (H, W) != (576, 1024):
print(
"WARNING: The conditioning frame you provided is not 576x1024. This leads to suboptimal performance as model was only trained on 576x1024. Consider increasing `cond_aug`."
)
if motion_bucket_id > 255:
print(
"WARNING: High motion bucket! This may lead to suboptimal performance."
)
if fps_id < 5:
print("WARNING: Small fps value! This may lead to suboptimal performance.")
if fps_id > 30:
print("WARNING: Large fps value! This may lead to suboptimal performance.")
value_dict = {}
value_dict["motion_bucket_id"] = motion_bucket_id
value_dict["fps_id"] = fps_id
value_dict["cond_aug"] = cond_aug
value_dict["cond_frames_without_noise"] = image
value_dict["cond_frames"] = image + cond_aug * torch.randn_like(image)
value_dict["cond_aug"] = cond_aug
# low vram mode
model.conditioner.cpu()
model.first_stage_model.cpu()
torch.cuda.empty_cache()
model.sampler.verbose = True
with torch.no_grad():
with torch.autocast(device):
model.conditioner.to(device)
batch, batch_uc = get_batch(
get_unique_embedder_keys_from_conditioner(model.conditioner),
value_dict,
[1, num_frames],
T=num_frames,
device=device,
)
c, uc = model.conditioner.get_unconditional_conditioning(
batch,
batch_uc=batch_uc,
force_uc_zero_embeddings=[
"cond_frames",
"cond_frames_without_noise",
],
)
model.conditioner.cpu()
torch.cuda.empty_cache()
# from here, dtype is fp16
for k in ["crossattn", "concat"]:
uc[k] = repeat(uc[k], "b ... -> b t ...", t=num_frames)
uc[k] = rearrange(uc[k], "b t ... -> (b t) ...", t=num_frames)
c[k] = repeat(c[k], "b ... -> b t ...", t=num_frames)
c[k] = rearrange(c[k], "b t ... -> (b t) ...", t=num_frames)
for k in uc.keys():
uc[k] = uc[k].to(dtype=torch.float16)
c[k] = c[k].to(dtype=torch.float16)
randn = torch.randn(shape, device=device, dtype=torch.float16)
additional_model_inputs = {}
additional_model_inputs["image_only_indicator"] = torch.zeros(2, num_frames).to(device)
additional_model_inputs["num_video_frames"] = batch["num_video_frames"]
for k in additional_model_inputs:
if isinstance(additional_model_inputs[k], torch.Tensor):
additional_model_inputs[k] = additional_model_inputs[k].to(dtype=torch.float16)
def denoiser(input, sigma, c):
return model.denoiser(model.model, input, sigma, c, **additional_model_inputs)
samples_z = model.sampler(denoiser, randn, cond=c, uc=uc)
samples_z.to(dtype=model.first_stage_model.dtype)
model.en_and_decode_n_samples_a_time = decoding_t
model.first_stage_model.to(device)
samples_x = model.decode_first_stage(samples_z)
samples = torch.clamp((samples_x + 1.0) / 2.0, min=0.0, max=1.0)
model.first_stage_model.cpu()
torch.cuda.empty_cache()
os.makedirs(output_folder, exist_ok=True)
base_count = len(glob(os.path.join(output_folder, "*.mp4")))
video_path = os.path.join(output_folder, f"{base_count:06d}.mp4")
writer = cv2.VideoWriter(
video_path,
cv2.VideoWriter_fourcc(*"MP4V"),
fps_id + 1,
(samples.shape[-1], samples.shape[-2]),
)
vid = (
(rearrange(samples, "t c h w -> t h w c") * 255)
.cpu()
.numpy()
.astype(np.uint8)
)
for frame in vid:
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
writer.write(frame)
writer.release()
all_out_paths.append(video_path)
return all_out_paths
import gradio as gr
import random
def infer(input_path: str, resize_image: bool, n_frames: int, n_steps: int, seed: str, decoding_t: int) -> str:
if seed == "random":
seed = random.randint(0, 2**32)
seed = int(seed)
output_paths = sample(
input_path=input_path,
resize_image=resize_image,
num_frames=n_frames,
num_steps=n_steps,
fps_id=6,
motion_bucket_id=127,
cond_aug=0.02,
seed=seed,
decoding_t=decoding_t, # Number of frames decoded at a time! This eats most VRAM. Reduce if necessary.
device=device,
)
return output_paths[0]
with gr.Blocks() as demo:
with gr.Column():
image = gr.Image(label="input image", type="filepath")
resize_image = gr.Checkbox(label="resize to optimal size", value=True)
btn = gr.Button("Run")
with gr.Accordion(label="Advanced options", open=False):
n_frames = gr.Number(precision=0, label="number of frames", value=num_frames)
n_steps = gr.Number(precision=0, label="number of steps", value=num_steps)
seed = gr.Text(value="random", label="seed (integer or 'random')",)
decoding_t = gr.Number(precision=0, label="number of frames decoded at a time", value=2)
with gr.Column():
video_out = gr.Video(label="generated video")
examples = [["https://user-images.githubusercontent.com/33302880/284758167-367a25d8-8d7b-42d3-8391-6d82813c7b0f.png"]]
inputs = [image, resize_image, n_frames, n_steps, seed, decoding_t]
outputs = [video_out]
btn.click(infer, inputs=inputs, outputs=outputs)
gr.Examples(examples=examples, inputs=inputs, outputs=outputs, fn=infer)
demo.queue().launch(debug=True, share=True, inline=False, show_error=True)
このスクリプトは、gitでcloneした「generative-models」ディレクトリと同じ階層に設置することになります。
そして、同じ階層に以下の2つのディレクトリを作成します。
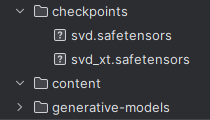
「checkpoints」には、以下のURLよりダウンロードしたファイルを保存しています。
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
ファイルの違いは、次のようになります。
| svd | 14フレーム |
| svd_xt | 25フレーム |
解像度は、576×1024となります。
モデルの指定は、以下の部分になります。
model_config = "generative-models/scripts/sampling/configs/svd_xt.yaml"
あと、リポジトリルートにある「scripts」ディレクトリをコピーしています。
したがって、コンテンツルートは次のような構成になります。
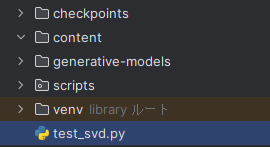
この状況において、以下のコマンドでデモを起動できます。
python test_svd.py
起動に成功すれば、次のように表示されます。
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://文字列.gradio.live
ブラウザで「http://127.0.0.1:7860」にアクセス。
次のような画面が表示されます。
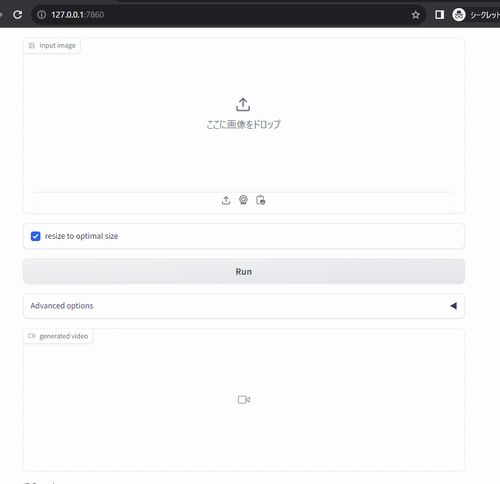
あとは、画像をアップロードして「Run」ボタンをクリックするだけです。
数分待てば、動画が生成されます。

