
いや~、参りました。
データ量を9倍にしても、これぐらいの改善しかないのですね。。。
苦労してデータを集めたのに、悲し過ぎます。
機械学習をやろうとする方に、是非ともこの記事を読んで欲しいです。
「データ量が増えれば、分析結果もよくなる」
この記事を読めば、上記を過度に期待してはいけない現実を知ることができます。
本記事の内容
- 実施した機械学習の概要【感情分析】
- データを9倍にした方法
- 作成したモデルで検証したらスゴイことを学べた!!
それでは、上記に沿って解説していきます。
実施した機械学習の概要【感情分析】
タイトルにも含めているように、感情分析を行いました。
分析の詳細は、次の記事で説明しています。

上記記事内で行った分析を「前回」と呼びます。
そして、データを9倍(正確には9.4倍)にして行った分析を「今回」と呼ぶことにします。
| 分析 | データ件数 | 結果(正解率) |
| 前回 | 23,260件 | 0.87964 |
| 今回 | 218,494件 | 0.88994 |
結果は、上記の通りです。
データ量は、9倍に増えています。
それなのに、結果は0.01(1%)のみの改善です。
苦労に見合わない・・・
私は、機械学習のプロではありません。
だから、この結果の本当のところはわかりません。
もしかしたら、プロから見たら「1%の改善はスゲー!!」なのかもしれません。
いや、多分ないでしょうけど。
ただ、たった1%程度の誤差なら全然許容できます。
感情分析という、そもそもが曖昧なモノに判断を下す分析です。
その分析であれば、1%の誤差なんて全く気にしません。
でも、ここで愚痴を言っても何も始まりません。
みなさんに役立つ情報を提供するのが、本ブログの役目です。
以下では、どうやってデータを9倍にしたのかを説明していきましょう。
つまり、1%のために苦労したことの説明でもあります。
データを9倍にした方法
まずは、Amazonのレビューデータを350万件集めました。
もちろん、スクレイピングです。
Amazonのスクレイピングに関しては、次の記事をご覧ください。

次に、そこからデータを選別しました。
嘘のレビューを除外したと言うことです。
「星5」のレビューは、サクラが多いです。
そのため、「星5」のレビューには、怪しい日本語や大袈裟な内容が多いです。
サクラかどうかを選別するのは、システム的にはかなり困難です。
できていたら、Amazonがすでに除外しているでしょう。
よって、今回は「星5」をまとめて対象から除外しました。
| 合計 | 3,500,704件 |
| 星5 | 2,663,203件 |
| それ以外 | 837,501件 |
ここで、837,501件のデータをクレンジングしました。
データを綺麗に整理したということですね。
その詳細は、次の記事で解説しています。

その結果、830,126件のレビューとなりました。
そして、このレビューのうち25万件(ランダムに選択)を感情分析しました。
どういうことかと言うと、Googleの機械学習用のAPIを利用しました。
GoogleのAPIを利用して、ラベリングされたテキスト(レビューを文章毎に分解)を得ました。
このあたりについては、次の記事で詳細を解説しています。

GoogleのAPIを利用した結果、25万件のレビューから、438,882件のテキストと感情分析結果のセットを得ることができました。
以下のような行が、438,882件あるということです。
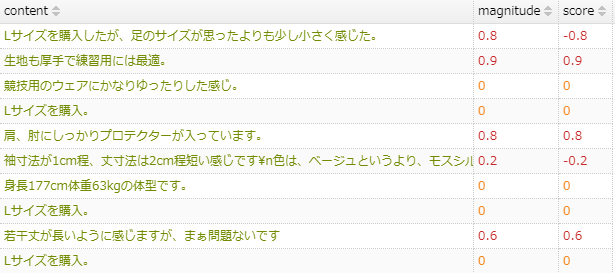
なお、25万件にしたのは、APIには利用料金がかかるからです。
無料枠で3万円ちょっと利用できるサービスがありました。
その無料枠内で収まるようにしたということです。
438,882件の内訳は以下。
| score | データ件数 |
| score > 0(ポジティブ) | 109,247件 |
| score = 0 | 42,420件 |
| score < 0(ネガティブ) | 287,215件 |
特に意味のないデータは0として判断されているようです。
絵文字なども「score」が0とされていました。
0は除いて、ポジティブとネガティブが同数になるようにします。
その結果、109,247+109,247=218,494件となります。
この218,494件が、前回の9倍のデータ量ということです。
お金に余裕さえあれば、さらにデータ量を増やすことは可能。
まあ、あまり意味はないでしょうけどね。
作成したモデルで検証したらスゴイことを学べた!!
作成したモデルを検証しておきましょう。
モデルは、scoreのように数値を出すものではありません。
つまり、回帰ではなく分類ということです。
正直、感情というモノは大雑把でいいと思います。
だからこそ、1%の誤差なら許容範囲だと考えています。
ただ、分類と言えどもその確率を表示することは可能です。
ネガティブ(NG)よりなのか、ポジティブ(PO)よりなのかは数値で判定可能です。
それでは、結果の確認をしていきます。
10個ピックアップしました。
| No | テキスト | score | 結果 | ネガティブ | ポジティブ |
| 1 | この期間中にステータスを3回要求しましたが、まったく応答がありません。 | -0.9 | NG | 0.996536 | 0.00346427 |
| 2 | 誠意がありません。 | -0.9 | NG | 0.844353 | 0.155646 |
| 3 | このショップをブラックリストに登録してください。 | -0.1 | NG | 0.898369 | 0.101631 |
| 4 | 商品受け取り、確認しましたが商品に間違いは無いです。 | 0.4 | PO | 0.0326949 | 0.967305 |
| 5 | 儲けにならない品物を売りたくなかったら、最初から出品しなければ良い。 | -0.6 | NG | 0.973939 | 0.0260612 |
| 6 | 在庫有りなんて書くな | 0.2 | NG | 0.899617 | 0.100383 |
| 7 | 特に問題はありません。 | 0.5 | PO | 0.015765 | 0.984235 |
| 8 | 説明通り、互換性があり、すぐに使えました。 | 0.9 | PO | 0.00226282 | 0.997737 |
| 9 | メガネが曇らないのもグッドでした。 | -0.3 | PO | 0.047539 | 0.952461 |
| 10 | さすがに1/4の価格なので期待しませんでしたが、問題ありませんでした。 | 0.3 | PO | 0.0126379 | 0.987362 |
scoreはGoogleのAPIが下した判定です。
結果、ネガティブ、ポジティブは新たに作成したモデルによる判定結果となります。
おおむね、GoogleのAPIと同じ結果です。
ラベルは、GoogleのAPIの結果を利用しているから、当然と言えば当然ですね。
しかし、No.6とNo.9は興味深い結果となっています。
No.6は、私の主観ではネガティブなコメントだと思います。
No.9は、私の主観ではポジティブなコメントだと思います。
みなさんは、どう思いますか?
なんと、私の主観とモデルの結果が一致しています。
何が言いたいのかというと、GoogleのAPIより優れた判定を下していると言いたいのです。
今回作成したモデルは、Amazonレビューに特化した感情分析をするようになっています。
そのため、Amazonレビューの感情分析においては、汎用的な分析を行うGoogleのAPIに作成したモデルが勝ったのではないでしょうか?
これは、なるほどです。
優れた汎用的な分析用APIを利用して、専門的な分析モデルを作成できるということです。
頭ではわかっていましたが、実際にできることが確認できました。
それであれば、GoogleのAPIにお金を払うことは何も惜しくはありませんね。
コストではなく、投資になるということですから。

