
netkeibaをWebスクレイピングしていきます。
今回は、開催一覧ページのスクレイピングです。
開催一覧ページをスクレイピングすることにより、競馬開催日(kaisai_date)を抽出できます。
kaisai_dateのリストが用意できれば、レース一覧ページのURLを特定できます。
そうすれば、netkeibaスクレイピングの半分以上は終わったも同然です。
その意味でも、今回の作業は派手さはないが重要なフェーズとなります。
本記事の内容
- ここまでの流れ【netkeibaのスクレイピング】
- netkeibaスクレイピングのロードマップ
- 開催一覧ページからkaisai_dateをスクレイピングするための仕様
- 【サンプルコード】開催一覧ページからkaisai_dateをスクレイピングする
それでは、上記に沿って解説していきます。
ここまでの流れ【netkeibaのスクレイピング】
netkeibaのスクレイピングに関して、段階を踏んで解説してきています。
今回は、そのシリーズの第2弾となります。
下記で過去の同シリーズを記載します。
第1弾

第1弾の記事は、スクレイピングをする上では必読の内容となります。
その内容を理解していないと、法律違反になることがありえます。
最悪の場合は、犯罪者です。
また、スクレイピングを行う上での環境面の準備に関しても説明しています。
そのため、netkeibaのスクレイピングをするためには第1弾をご覧ください。
以上、ここまでの流れとなります。
では、次にnetkeibaスクレイピングのロードマップを説明します。
netkeibaスクレイピングのロードマップ
ロードマップとは、大げさかもしれません。
でも、ここでスクレイピングのための全体像をつかんでおきます。
そのために、まずは目的から確認しましょう。
目的は、レース結果ページからデータをスクレイピングすることです。
レース結果詳細ページ
https://race.netkeiba.com/race/result.html?race_id=202006010101
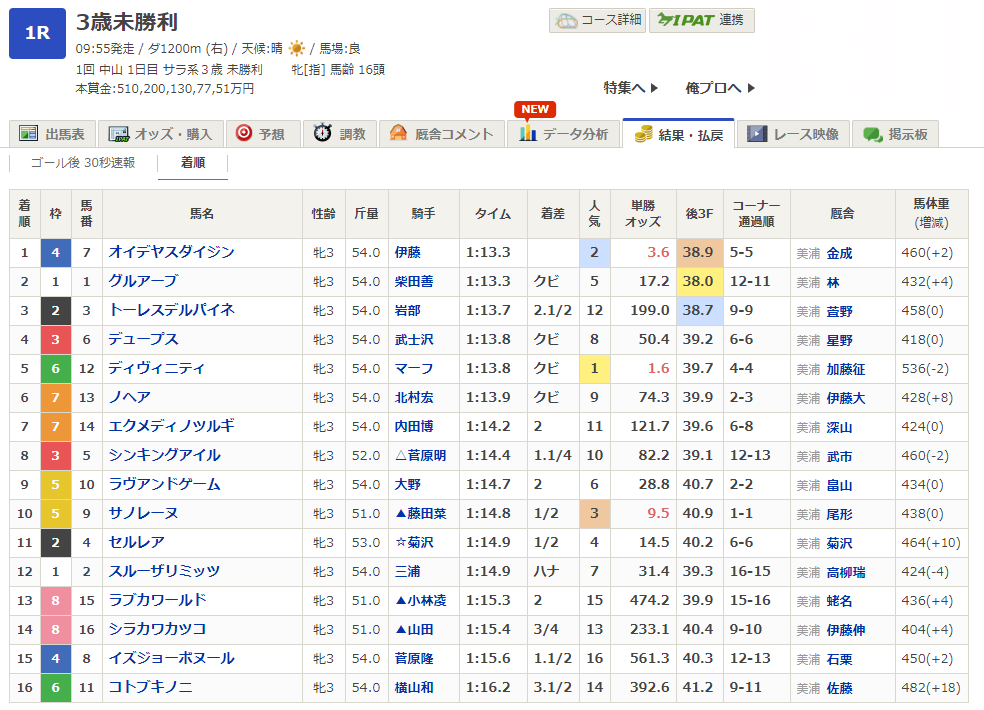
上記URLを見るとわかるように、「race_id」リストが必要となります。
そして、race_idのリストは次のレース一覧ページから集めることが可能です。
レース一覧ページ
https://race.netkeiba.com/top/race_list.html?kaisai_date=20200105
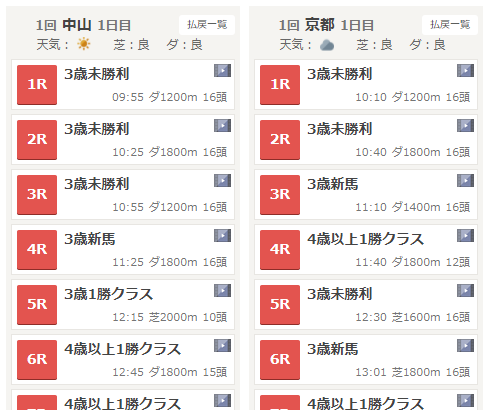
そうなると、次は「kaisai_date」リストが必要になることがわかります。
では、このkaisai_dateはどこで収集できるのでしょうか?
調査した結果、次の画面でkaisai_dateリストが作成できそうです。
とりあえず、次のURLにアクセスしてみてください。
開催一覧ページ
https://race.netkeiba.com/top/calendar.html?year=2020&month=1
そうすると、次の画面が表示されます。
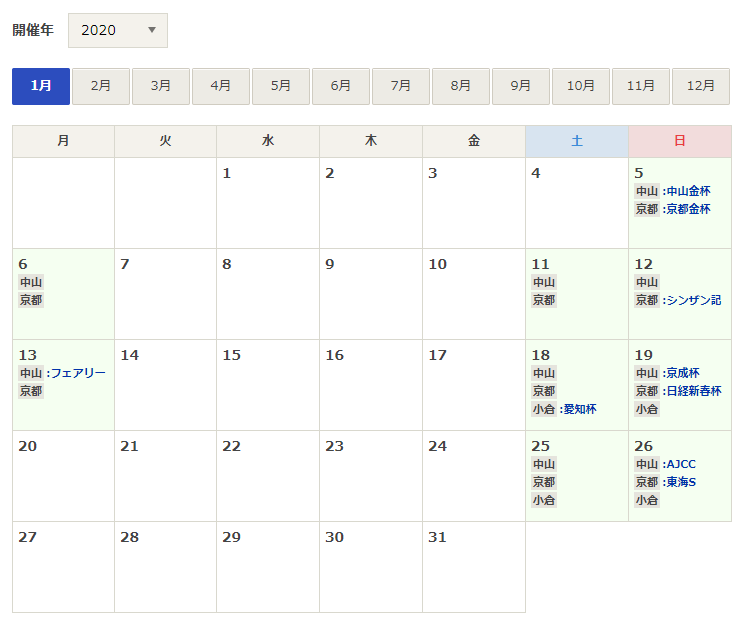
カレンダーに開催場所が記入されていることを確認できます。
重賞レースがある場合は、開催場所毎に重賞レースが記載されています。
そして、各セル(日)毎にリンクが設定されていることがわかります。

上記の競馬開催日であれば、次のURLが設定されています。
https://race.netkeiba.com/top/race_list.html?kaisai_date=20200105
このURLは、上記の「レース一覧ページ」のURLと同じです。
これで目的となるrace_idを取得できるまでの道筋が見えました。
以上が、netkeibaスクレイピングのロードマップでした。
では、今回はkaisai_dateのリストを作成していきましょう。
以下では、そのための仕様(考え方)を確認します。
開催一覧ページからkaisai_dateをスクレイピングするための仕様
開催一覧ページとは、カレンダーの画面でした。
この画面からkaisai_dateをスクレイピングすることが目的です。
その際の仕様を次の2点に分けて説明します。
- 開催一覧ページのURL作成
- kaisai_dateの抽出
それぞれを下記で説明します。
開催一覧ページのURL作成
開催一覧ページをURLで表示すると、以下。
https://race.netkeiba.com/top/calendar.html?year=2020&month=1
この画面でkaisai_dateをスクレイピングで抽出していきます。
ただし、kaisai_dateをクエリに利用しているのは2008年1月以降となります。
それより前は、kaisai_dateを利用していません。
全く別のサイトであると言えるレベルで異なります。
データ構成、ページレイアウト、ページURLなどが全く違います。
よって、2007年12月以前のデータをスクレイピングする場合は別の方法にする必要があります。
今回は、2008年1月以降をスクレイピングの対象とします。
よって、各クエリパラメータの設定できる範囲は以下となります。
https://race.netkeiba.com/top/calendar.html?year=●&month=■
| 項目 | 最小 | 最大 |
| year(●) | 2008 | 2022 |
| month(■) | 1 | 12 |
別に上記対象期間をすべて処理する必要はありません。
必要な期間だけに条件を絞ればいいだけです。
以上より、yearとmonthの組み合わせで開催一覧ページのURL作成が可能です。
kaisai_dateの抽出
開催日のリンクに設定してあるURLからkaisai_dateを抽出していきます。

上の表示のタグは以下。
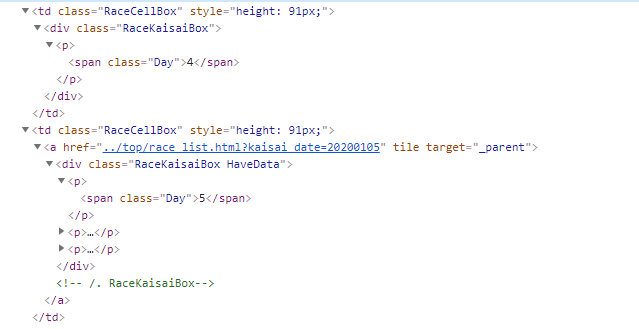
昔ながらのtableタグでカレンダーを表示しています。
そして、日はtdタグで表現していることがわかります。
競馬の開催日には、tdタグの直下にaタグが設定されています。
このaタグのhrefの値から、kaisai_dateを抜き出すことになります。
やることを箇条書きにすると以下です。
- classに「RaceCellBox」と設定されたtdを抽出
- そのtdタグの下にあるaタグを抽出
- そのaタグからhrefを抽出
- そのhrefからkaisai_dateを抽出
ここまで仕様を考えることができれば、あとは実際にプログラミングするだけです。
【サンプルコード】開催一覧ページからkaisai_dateをスクレイピングする
開催一覧ページからkaisai_dateを抽出するコードは、以下。
現時点(2021年2月22日)では元気に動いています。
サンプルコード
import bs4
import traceback
import re
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# ドライバーのフルパス
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 2
# 遷移間隔(秒)
INTERVAL_TIME = 3
# 対象年度
YEAR = [2018, 2019, 2020]
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
page_source = driver.page_source
return page_source
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
try:
info = []
table = soup.find(class_="Calendar_Table")
if table:
elems = table.find_all("td", class_="RaceCellBox")
for elem in elems:
a_tag = elem.find("a")
if a_tag:
href = a_tag.attrs['href']
match = re.findall("\/top\/race_list.html\?kaisai_date=(.*)$", href)
if len(match) > 0:
item_id = match[0]
info.append(item_id)
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
if __name__ == "__main__":
# ブラウザのdriver取得
driver = get_driver()
# ページカウンター制御
page_counter = 0
for year in YEAR:
for month in range(1, 13):
page_counter = page_counter + 1
# 対象ページURL
page = "https://race.netkeiba.com/top/calendar.html?year=" + str(year) + "&month=" + str(month)
# ページのソース取得
source = get_source_from_page(driver, page)
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存
print(data)
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 閉じる
driver.quit()
プログラムの内容は、上記の仕様とコード内のコメントを見てください。
Pythonが理解できれば、スクレイピング初心者でもなんとなくわかるはずです。
Selenium特有の部分は、特に意識しなくてもいいようにコーディングしています。
あとは、以下の定数だけ説明しておきます。
# ドライバーのフルパス CHROMEDRIVER = chromedriver.exeのパス" # 改ページ(最大) PAGE_MAX = 2 # 遷移間隔(秒) INTERVAL_TIME = 3 # 対象年度 YEAR = [2018, 2019, 2020]
CHROMEDRIVERについては、次の記事で詳しく説明しています。

PAGE_MAXとINTERVAL_TIMEは、次の記事内で説明しています。
「商品一覧ページから商品IDを抽出する」の箇所です。
全く同じ使い方をしているので、参考にしてください。
YEARは、どの年度を対象にするかを決める値です。
リスト形式で設定する形となります。
実行結果
サンプルコードを実行した結果は、以下。
['20180106', '20180107', '20180108', '20180113', '20180114', '20180120', '20180121', '20180127', '20180128'] ['20180203', '20180204', '20180210', '20180211', '20180212', '20180213', '20180217', '20180218', '20180224', '20180225']
2018年1月と2018年2月のkaisai_dateが表示されています。
PAGE_MAXを2に設定しているため、2ページのみをスクレイピングの限度としています。
まとめ
実行結果の表示部分となる次のコードに関して、補足しておきます。
# データ保存
print(data)
ここは、各自で適当に関数などを自作するなどして対応してください。
例えば、以下の関数です。
- 受け取ったdataをファイルに追記する関数
- 受け取ったdataをデータベースに登録する関数
上記の関数を用意すれば、kaisai_dateリストを作成することが可能になります。
個人的には、MongoDBに登録する形式を採用しています。
WindowsでMongoDBをインストールする場合には、次の記事をご覧ください。

PythonからMongoDBを操作するコードに関しては、ググればすぐに出てきます。
それにとてもシンプルで簡単です。
追記 2021年2月25日
続きは以下


