
netkeibaのスクレイピングを解説します。
対象とするページは、レース一覧ページです。
このレース一覧ページから、race_idをスクレイピングで取得します。
つまり、今回の目的はrace_idリストを作成することになります。
本記事の内容
- ここまでの流れ【netkeibaのスクレイピング】
- レース一覧ページのスクレイピング仕様
- レース一覧ページからrace_idを抽出
それでは、上記に沿って解説していきます。
ここまでの流れ【netkeibaのスクレイピング】
netkeibaのスクレイピングに関して、段階を踏んで解説してきました。
今回で第3弾となります。
下記で過去の同シリーズを記載します。
第1弾

第2弾

第1弾の記事は、スクレイピングをする上では必読の内容となります。
その内容の理解は必須です。
ここの理解をしていないと、犯罪を犯すことになるかもしれません。
逆に、この内容さえ理解していれば、スクレイピングが違法でも何でもないとわかります。
自信を持ってスクレイピングをするためにも、一読をおススメします。
第2弾の記事は、競馬開催日リストの作成方法を解説しています。
開催日を特定できれば、レース一覧ページの特定が可能になります。
そして、今回は第3弾です。
この第3弾では、特定できるようになった開催一覧ページからrace_idを抽出します。
race_idリストを作成できるようになれば、レース結果詳細ページの特定が可能になります。
この一連の流れについては、第2弾の「netkeibaスクレイピングのロードマップ」で解説しています。
まだ、内容を見ていない方はそちらをご覧ください。
以下では、今回の舞台となるレース一覧ページのスクレイピング仕様について説明していきます。
レース一覧ページのスクレイピング仕様
スクレイピングをする上では、大きく2つのポイントがあります。
- 対象ページのURL作成
- 対象ページのhtmlタグ分析
この2点を意識すれば、スクレイピングがやりやすくなります。
この2点を今回の仕様に当てはめると以下のように考えることができます。
- レース一覧ページのURL作成
- レース一覧ページのhtmlタグ分析
そのままですが、具体化することでイメージがしやすくなります。
では、それぞれを下記で説明していきます。
レース一覧ページのURL作成
まず、前提として手元にはkaisai_dateリストがあります。
このkaisai_dateリストについて意味がわからない場合は、第2弾の記事を見直してください。
とりあえず、以下の9個があるとします。
['20180106', '20180107', '20180108', '20180113', '20180114', '20180120', '20180121', '20180127', '20180128']
そして、netkeibaにおけるレース一覧ページのURLは以下の形式でした。
https://race.netkeiba.com/top/race_list.html?kaisai_date=●
●にkaisai_dateを設定すると、レース一覧ページが表示されます。
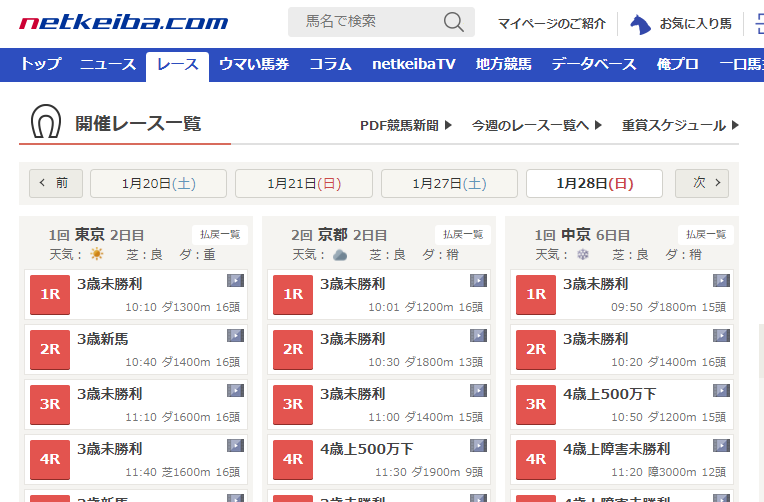
例えば、「20180128」を設定してみてください。
https://race.netkeiba.com/top/race_list.html?kaisai_date=20180128
上記URLにアクセスすると、以下の画面が表示されます。
では、今度はkaisai_dateリストにはない「20180129」を設定してみましょう。
https://race.netkeiba.com/top/race_list.html?kaisai_date=20180129
このページにアクセスすると、次の画面が表示されます。
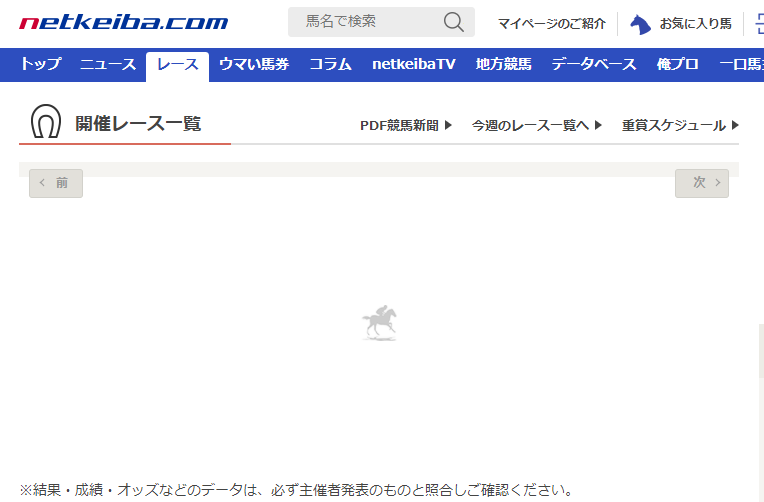
読み込み中を示すアイコンの馬が走り続けます。
これは、データがないことを示しています。
Ajaxでデータを読み込んでいるので、このような表示になるのでしょう。
念のために言っておくと、Ajaxであろうとスクレイピングは可能です。
Seleniumを使えば、基本的にはどんなページでもスクレイピングはできます。
レース一覧ページのhtmlタグ分析
目標となるrace_idは、次の要素ごとに存在しています。
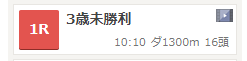
この要素にaタグが設定されているということです。
そして、そのaタグのhrefの値にrace_idが記載されています。
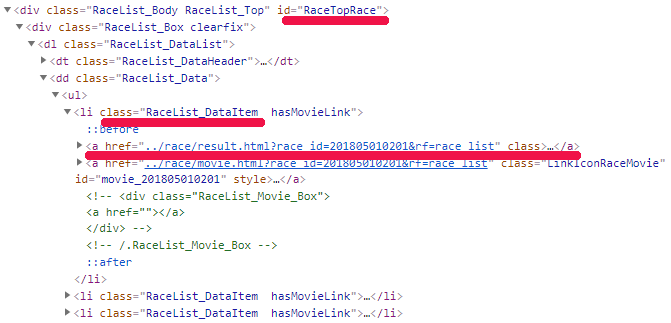
上記htmlソース上では、各レースはliタグで表示されています。
classに「RaceList_DataItem」を持つliタグです。
そのliタグの下にはaタグが二つ存在しています。
今回は、最初のaタグに注目しましょう。
(※二つ目のaタグでも問題はありません)
そのaタグのhrefにrace_idが記載されています。
これを抽出しようということです。
なお、「id=”RaceTopRace”」はデータがあるときの判断基準として利用します。
「id=”RaceTopRace”」がhtmlソース上に存在すれば、レース一覧があるということです。
この辺も考慮してスクレイピングを行っていきます。
レース一覧ページからrace_idを抽出
レース一覧ページからrace_idを抽出するコードは、以下。
現時点(2021年2月23日)ではバリバリと動いています。
netkeiba側がタグ構成を変更しない限りは、元気に動くはずです。
逆に、デザイン変更されると動かなくなると言えます。
サンプルコード
import bs4
import traceback
import re
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# ドライバーのフルパス
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 2
# 遷移間隔(秒)
INTERVAL_TIME = 3
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
# id="RaceTopRace"の要素が見つかるまで10秒は待つ
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, 'RaceTopRace')))
page_source = driver.page_source
return page_source
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
try:
info = []
elem_base = soup.find(id="RaceTopRace")
if elem_base:
elems = elem_base.find_all("li", class_="RaceList_DataItem")
for elem in elems:
# 最初のaタグ
a_tag = elem.find("a")
if a_tag:
href = a_tag.attrs['href']
match = re.findall("\/race\/result.html\?race_id=(.*)&rf=race_list", href)
if len(match) > 0:
item_id = match[0]
info.append(item_id)
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# kaisai_dateリストを取得する
def get_list_id():
return ['20180106', '20180107', '20180108', '20180113', '20180114', '20180120', '20180121', '20180127', '20180128']
if __name__ == "__main__":
# kaisai_dateリスト取得
list_id = get_list_id()
# ブラウザのdriver取得
driver = get_driver()
# ページカウンター制御
page_counter = 0
for kaisai_date in list_id:
page_counter = page_counter + 1
# 対象ページURL
page = "https://race.netkeiba.com/top/race_list.html?kaisai_date=" + str(kaisai_date)
# ページのソース取得
source = get_source_from_page(driver, page)
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存
print(data)
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 閉じる
driver.quit()
プログラムの内容は、上記の仕様とコード内のコメントを見てください。
Pythonが理解できれば、スクレイピング初心者でも大丈夫なはずです。
あとは、第2弾の記事のサンプルコードを見てください。
それの内容とほとんど変わりのないコードです。
ただ、次の2点は説明が必要でしょう。
該当データがあるかどうかの確認
存在するkaisai_dateの場合のみ処理を進めるプログラムにしています。
その部分を表すのは、以下のコードです。
# id="RaceTopRace"の要素が見つかるまで10秒は待つ
target_elem = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, "RaceTopRace"))
)
if target_elem:
page_source = driver.page_source
return page_source
else:
return None
正直、毎回ここまでエラー処理を丁寧にしません。
ただ、今回は気が付いたのでやっているだけです。
実際は、この部分でエラーになることはほとんどないでしょう。
なぜなら、実際にデータの存在するkaisai_dateが事前に絞り込まれているからです。
しかし、netkeibaのサーバーは時間帯によっては重いときがあります。
その際にエラーになる可能性があります。
(※AmazonやTwitterをスクレイピングする際には、そんな心配はしません)
よって、念のために例外処理を丁寧に記述しているということです。
kaisai_dateリストの取得
# kaisai_dateリストを取得する
def get_list_id():
return ['20180106', '20180107', '20180108', '20180113', '20180114', '20180120', '20180121', '20180127', '20180128']
ここは各自で自由に記述してください。
最終的に、リスト型でデータを返答すればOKです。
第2弾のサンプルコードをもとに、各自でkaisai_dateのリストを保持していることだと思います。
データの保存先は、ファイルやデータベースなど様々でしょう。
この関数内でファイル読み込みやデータベースへのアクセスの処理を記述してください。
実行結果
サンプルコードを実行した結果は、以下。
['201806010101', '201806010102', '201806010103', '201806010104', '201806010105', '201806010106', '201806010107', '201806010108', '201806010109', '201806010110', '201806010111', '201806010112', '201808010101', '201808010102', '201808010103', '201808010104', '201808010105', '201808010106', '201808010107', '201808010108', '201808010109', '201808010110', '201808010111', '201808010112'] ['201806010201', '201806010202', '201806010203', '201806010204', '201806010205', '201806010206', '201806010207', '201806010208', '201806010209', '201806010210', '201806010211', '201806010212', '201808010201', '201808010202', '201808010203', '201808010204', '201808010205', '201808010206', '201808010207', '201808010208', '201808010209', '201808010210', '201808010211', '201808010212']
kaisai_dateが20180106と20180107の2開催日をスクレイピングしています。
PAGE_MAXを2に設定しているため、最大で2ページをスクレイピングするようになっています。
このあたりの説明に関しても、第2弾と同じです。
その結果、2開催日に登録されているすべてのrace_idが表示されています。
まとめ
race_idは以下のコードで表示しています。
# データ保存
print(data)
ここも第2弾と同じように、各自で好きなようにファイルやデータベースに保存してください。
ここまでの過程を経て、race_idのリストが用意できました。
ここまで来れば、あとはもう少しです。
次回は、race_idのリストをもとにレース結果ページをスクレイピングしていきます。
追記 2021年2月25日
続きは以下


