
ここ最近は、Animagine XL 3.0を用いた検証を行っています。

このモデルは、噛めば噛むほど味が出るスルメのようです。
プロンプトを工夫すると、その分だけ反応を示してくれます。
そのプロンプトの工夫で言うと、年代タグがあります。

また、LoRA不要となるようなシリーズタグの存在もありますね。

このシリーズタグについては、87個を取得することができました。
次の記事でその一覧を紹介しています。

これだけでも、かなりの種類の絵柄を試すことができます。
でも、もっといろいろと試してみたいとなるわけなんですよね。
ということで、できる限りで多くのタグを集めてみます。
Danbooruのスクレイピング
方法としては、スクレイピングです。
スクレイピングと聞くと、ヤバいと思う人がまだまだいるかもしれません。
でも、スクレイピングは何も悪いことではありません。
そのことは、以下の記事で説明しています。


したがって、利用規約で禁止されていても平然とスクレイピングをしています。



当サイトでは、スクレイピングの記事がたくさんあります。
興味のある方は、ご覧ください。
Danbooruの話に戻すと、もちろん利用規約でスクレイピングに該当するようなことを禁止しています。
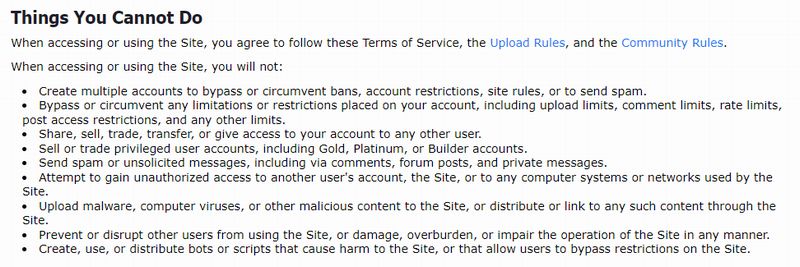
でも、非ログインでルールさえ守れば、このような規約は無視してOKです。
スクレイピングによるシリーズタグの取得
Danbooruのスクレイピングは、実は簡単とは言えません。
スクレイピングの対策は、実施されています。
結論から言うと、Seleniumを使わないと厳しいです。
Seleniumについては、次の記事で解説しています。

さらに、headless(ヘッドレス)モードもNGとなります。
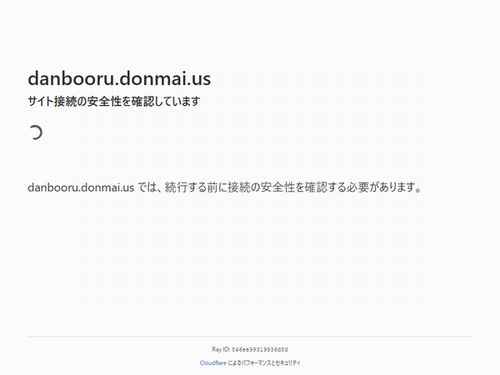
headlessモードだと、Cloudflareで通行止めされます。
突破できる方法があるのかもしれませんが、今回はheadlessモードは諦めることにします。

仕様としては、次のタグページを検索した結果を取得するというモノになります。
https://danbooru.donmai.us/tags
検索条件は、以下。
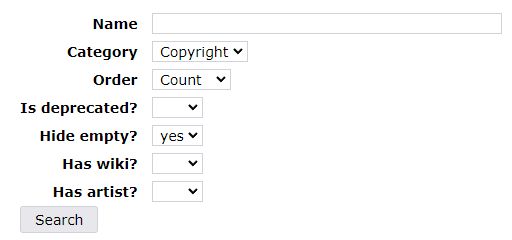
1ページに20個のタグが表示されています。
そのため、改ページ対応も必要となります。
それらを考慮したのが、次のコードです。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
class DanbooruScraper:
def __init__(self, chromedriver_path, base_url, max_page, output_file, wait_time):
self.base_url = base_url
self.max_page = max_page
self.output_file = output_file
self.wait_time = wait_time
chrome_service = Service(executable_path=chromedriver_path)
options = Options()
# options.add_argument("--headless")
self.driver = webdriver.Chrome(service=chrome_service, options=options)
def scrape_tags(self):
with open(self.output_file, "w") as file:
for page in range(1, self.max_page + 1):
self.driver.get(f"{self.base_url}&page={page}")
time.sleep(self.wait_time) # ページ間の待機時間
tags = self.driver.find_elements(By.CSS_SELECTOR, "td.name-column a.tag-type-3")
tag_names = [tag.text for tag in tags if tag.text and tag.text != '?']
file.writelines([tag + "\n" for tag in tag_names])
def close_driver(self):
self.driver.quit()
# 使用例
chromedriver_path = "chromedriverのパス"
base_url = "https://danbooru.donmai.us/tags?commit=Search&search%5Bcategory%5D=3&search%5Bhide_empty%5D=yes&search%5Border%5D=count"
max_page = 5
output_file = "scraped_tags.txt"
wait_time = 1 # 1秒待機
scraper = DanbooruScraper(chromedriver_path, base_url, max_page, output_file, wait_time)
scraper.scrape_tags()
scraper.close_driver()
ポイントを絞って、説明しておきます。
コードの詳細を知りたい場合は、ChatGPTに説明させましょう。
わからない場合は、ワンツーマンで教えてくれます。
「max_page = 5」でページ指定を行っています。
5ページなので、全部で人気の100タグが取得できます。
「wait_time = 1」により、サーバへの負荷を考慮しています。
これは、スクレイピングを行う際のルールです。
必ず守りましょう。
コードを実行すると、「scraped_tags.txt」に100個のタグが記録されているはずです。
もっとタグが欲しい場合は、 max_pageを調整してみてください。

