
「Pythonで日本語対応したPDFを作成したい」
「xhtml2pdfで作成したPDFが文字化けしている・・・」
このような場合には、この記事の内容が参考となります。
この記事では、xhtml2pdfで作成したPDFの文字化けを解消する方法を説明しています。
本記事の内容
- xhtml2pdfで作成したPDFの文字化け
- @font-face
- 日本語フォント
- 文字化け解消の動作確認
それでは、上記に沿って解説していきます。
xhtml2pdfで作成したPDFの文字化け
xhtml2pdfについては、次の記事で解説しています。

xhtml2pdfにより作成したPDFでは、日本語が文字化けします。
文字化けの状況は、次のような感じです。
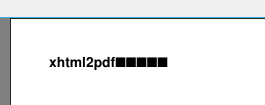
文字化けの部分は、日本語です。
帳票系の場合、基本的には文字化けすると考えたほうがよいでしょうね。
この文字化けを解消する方法は、意外と簡単です。
設定ファイルを修正するとかややこしいことはありません。
ただ、CSSの知識が少し必要になります。
あと、日本語フォントも必要です。
それらに関して、以下で説明します。
@font-face
@font-faceが、xhtml2pdfにおける文字化けを解消するキーになります。
@font-faceは、CSSのアットルールと言われるモノです。
@font-faceには、ダウンロードすべき外部フォントに関する指定を記述します。
具体的には、次のような記述になります。

「Open Sans」という名称でフォントを宣言しています。
そして、その中身となる外部フォントをsrcに設定します。
上記例では、複数を指定しています。
複数指定することにより、ブラウザに最適なフォントが選択されるようです。
ただし、xhtml2pdfでは1つだけの指定で十分でしょう。
そして、format部分も不要です。
あと、urlに設定するものがURLである必要がありません。
ここでは、URLをブラウザでアクセス可能なパスと定義します。
しかし、xhtml2pdfでは実際のファイルパスを指定することになります。
つまり、URLではなくファイルパスを指定します。
@font-face {
font-family: "my_lang";
src: url("/opt/font/ipaexg.ttf");
}
なお、「font-family」には自分で決めた名前を指定できます。
以上、@font-faceについて説明しました。
次は、日本語フォントについて確認します。
日本語フォント
日本語のフォントを用意する必要があります。
ここでは、IPAexフォントをダウンロードしましょう。
IPAexフォントは、無償で使える高品質の日本語フォントです。
IPAexフォント Ver.004.01
https://moji.or.jp/ipafont/ipaex00401/
上記ページから、ダウンロードできます。

ダウンロードするファイルは、明朝とゴシックのパックでよいでしょう。
ダウンロードしたzipを解凍すると、以下の2ファイルを確認できます。
- ipaexm.ttf(IPAex明朝)
- ipaexmgttf(IPAexゴシック)
これで日本語フォントを用意することができました。
以上、日本語フォントについて説明しました。
次は、文字化け解消の動作確認を行います。
文字化け解消の動作確認
xhtml2pdfの仕様を理解している前提で説明を進めます。
xhtml2pdfで利用するhtmlファイルを以下とします。
template.html
<html>
<head>
<title>xhtml2pdfの日本語化</title>
<style type="text/css">
@font-face {
font-family: "my_lang";
src: url("/opt/font/ipaexg.ttf");
}
html, body {
font-family: "my_lang";
}
</style>
</head>
<body>
<h1>xhtml2pdfの日本語化</h1>
</body>
</html>
「/opt/font/ipaexg.ttf」は、用意した日本語フォントのファイルパスです。
ここの値は、各自の環境に合わせて変更してください。
また、宣言した「my_lang」をhtml全体に適用させています。
html, body {
font-family: "my_lang";
}
そして、次のPythonコードを用意します。
template.htmlと同じディレクトリ上にPythonスクリプトを保存しましょう。
from xhtml2pdf import pisa
# htmlファイル名
html_file = "template.html"
# PDFファイル名
output_filename = "output.pdf"
if __name__ == "__main__":
with open(html_file) as source:
source_html = source.read()
with open(output_filename, "w+b") as file:
pisa_status = pisa.CreatePDF(src=source_html, dest=file)
上記コードを実行した結果、「output.pdf」が作成されます。
output.pdf

日本語が文字化けしていませんね。
以上、文字化け解消の動作確認を説明しました。

