
Amazonレビューは、何かと話題になります。
今なら、Amazonレビューにはサクラが多くて胡散臭いという話題でしょうか?
Amazonレビューは、以前は本当に役に立ちました。
参考にして買い物をすることも多くありました。
しかし、今はレビューを参考にすることが、めっきりと減りました。
そもそも、Amazonでの買い物をする機会が減りました。
その代わりに、安全なイメージのヨドバシで買い物をしています。
レビュー以外にも、悪質な業者の問題がAmazonには存在していますからね。
そのイメージの悪いAmazonレビューに関して、この記事で取り上げます。
どう取り上げるかと言うと、センチメント分析(感情分析)の対象とします。
本記事の内容
- Amazonレビューをセンチメント分析(感情分析)する目的・意図
- Amazonレビューを取得(データ収集)する
- Amazonレビューをセンチメント分析(感情分析)する
- Amazonレビューのセンチメント分析結果
- センチメント分析(感情分析)は使えない!?
それでは、上記に沿って解説していきます。
Amazonレビューをセンチメント分析(感情分析)する目的・意図
Amazonレビューには、多くの情報が集まっています。
まず、その投稿の量が圧倒的です。
確かに、サクラも多いのでしょう。
でも、サクラ以外の真っ当なレビューも多く投稿されています。
その投稿数が、他サイトとは比較にはなりません。
ヨドバシでは、レビューはほとんど投稿されないようです。
その意味でも、Amazonのレビューには価値があります。
また、コメントと評価(星1~5)がセットになっているのもポイントです。
このようにセットになっている点が、データ分析の際には役に立ちます。
以上より、Amazonレビューにはデータ量と内容(コメントと評価)が備わっていると言えます。
そして、何よりもネガポジ分析を実際のデータでやりたかったというのが大きいです。
自分にも身近なデータで分析する方が、モチベーションも沸きますからね。
Amazonレビューを取得(データ収集)する
データ分析の最初の関門となります。
どうやってデータを大量に集めるのか?ということですね。
これに関しては、全く問題ありません。
本ブログでは、多くのサイトをスクレイピングした結果を記事にしています。





その中でも、次の記事は今回の作業にビンゴです。

上の記事の内容を若干修正して、データを集めました。
改良したコードは以下。
import bs4
import time
import re
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
CHROME_DRIVER = "chromedriver.exeのパス"
FILE_PATH = "./amazon_data/review.json"
# Amazonページ取得
def get_page_from_amazon(url):
text = ""
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROME_DRIVER, options=options)
driver.get(url)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
text = driver.page_source
# ブラウザ停止
driver.quit()
return text
# 全ページ分をリストにする
def get_all_reviews(url):
rvw_list = []
i = 1
while True:
print(i,'searching')
i += 1
text = get_page_from_amazon(url)
amazon_soup = bs4.BeautifulSoup(text, features='lxml')
for ratings in amazon_soup.find_all("div", attrs={"data-hook": "review"}):
submission_date = ratings.find("span", {'data-hook':'review-date'}).text
rating = ratings.find('i', attrs={"data-hook": "review-star-rating"}).text
review_txt = ratings.find("span", {'data-hook':'review-body'}).text
#paid = ratings.find("span", attrs={"class": "a-color-success a-text-bold"})
print(submission_date + "@" + rating + "@" + review_txt)
print('\n')
if submission_date:
rating = rating.replace("5つ星のうち", "")
submission_date = extract_date(submission_date)
info = {}
info["postdate"] = submission_date
info["rating"] = rating
info["review_txt"] = review_txt
rvw_list.append(info)
# 次へボタン
next_page = amazon_soup.select('li.a-last a')
if next_page != []:
next_url = 'https://www.amazon.co.jp/' + next_page[0].attrs['href']
url = next_url
# 最低でも1秒は間隔をあける
time.sleep(1)
else:
break
return rvw_list
def extract_date(s):
date_pattern = re.compile('(\d{4})年(\d{1,2})月(\d{1,2})日')
result = date_pattern.search(s)
if result:
y, m, d = result.groups()
return str(y) + str(m.zfill(2)) + str(d.zfill(2))
else:
return None
if __name__ == '__main__':
# Amzon商品ページ
url = 'https://www.amazon.co.jp/dp/B081CR9LQ1?pf_rd_r=9G7DP9DBQV9R5WWBA7GB&pf_rd_p=cf3dd3d4-7c29-4fa2-a9b7-8e9f95c1f37f&pd_rd_r=56934866-4323-49ea-ae8e-289260468100&pd_rd_w=bIWmn&pd_rd_wg=gA4B0&ref_=pd_gw_ci_mcx_mr_hp_d'
# URLをレビューページのものに書き換える
new_url = url.replace('dp', 'product-reviews')
# レビューの取得
rvw_list = get_all_reviews(new_url)
# データフレームに変換
df = pd.DataFrame(rvw_list)
# jsonとして保存
df.to_json(FILE_PATH, orient='records')
内容に不明な点があれば、過去記事を参考にしてください。
詳細を説明しています。
このサンプルコードを動かすと、該当するAmazonの商品ページのレビューを収集します。
その結果は、amazon_dataフォルダ内のreview.jsonに保存されます。
- 投稿日
- 評価
- コメント
項目的には、上記の3つとなります。
Amazonレビューをセンチメント分析(感情分析)する
センチメント分析(感情分析)は、難しそう。。。
このように思うかもしれません。
ただ、分析するだけなら簡単にできます。
やり方は以下。
- 単語感情極性対応表(ネガポジ辞書)を取得する
- 分析対象の文章を単語に分割する(形態素解析)
- ネガポジ辞書と単語を比較する(否定・肯定の判定)
では、上記を説明していきましょう。
単語感情極性対応表(ネガポジ辞書)を取得する
以下のページにアクセスします。
「日本語」のリンク先が辞書となります。
http://www.lr.pi.titech.ac.jp/~takamura/pndic_ja.html
優れる:すぐれる:動詞:1 良い:よい:形容詞:0.999995 喜ぶ:よろこぶ:動詞:0.999979 褒める:ほめる:動詞:0.999979 めでたい:めでたい:形容詞:0.999645 ~ 厄難:やくなん:名詞:-0.765276 紡ぐ:つむぐ:動詞:-0.765358 自製:じせい:名詞:-0.765388 死亡:しぼう:名詞:-0.765674 主義:しゅぎ:名詞:-0.765714
上記がその内容です。
単語毎に値が設定されています。
その値の範囲は、-1から1までとなります。
1に近いほど、肯定的なワードです。
-1に近いほど、否定的なワードです。
分析対象の文章を単語に分割する(形態素解析)
文章を形態素解析します。
形態素解析に関しては、次の記事で詳しく説明しています。

プログラム的には、複雑なことはしません。
専用のソフトを用いて、簡単に行うことができます。
今回は、MecabをPythonから用いて形態素解析を行っています。
ネガポジ辞書と単語を比較する(否定・肯定の判定)
ここまで説明してきたら、わかると思います。
形態素解析によって、文章毎(レビューのコメント)に単語が求められます。
そして、その単語が単語感情極性対応表(ネガポジ辞書)にあるかどうかを調べます。
あった場合は、何点(-1~1の間の数値)なのかを求めます。
複数の単語がマッチする場合は、その平均を用います。
Amazonレビューのセンチメント分析結果
約9000件のレビューを分析しました。
上記のデータ収集プログラムで集めたデータです。
以下の3つの結果を確認しましょう
- ヒストグラム
- 散布図
- 結果一覧
では、それぞれを確認します。
ヒストグラム
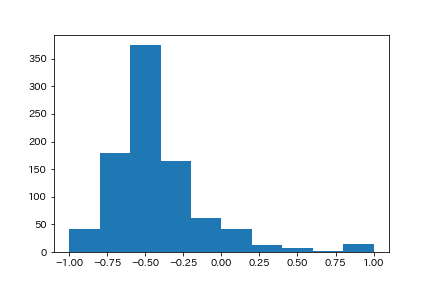
基本的には、ネガティブの結果が多いです。
9割以上が、0以下という結果ですね。
ヒストグラムに関しては、次の記事が参考になります。
簡単にヒストグラムの図を作成できます。
レビューのコメントには、ネガティブな結果が多いことはわかりました。
では、その結果と評価(星1~5)との関係が気になります。
その二つの値の関係性を見るには、散布図が約に立ちます。
以下で、それを確認しましょう。
散布図
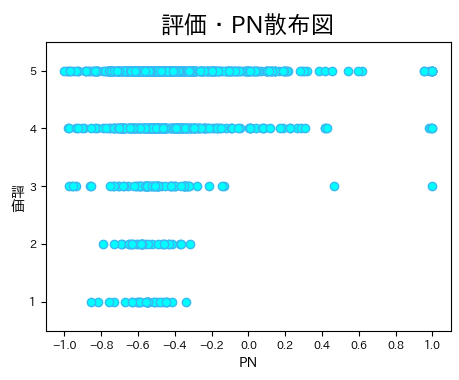
横(x軸)が、ネガポジ(PN)結果の値です。
縦(y軸)が、Amazonレビューにおける評価です。
この結果を見ると、次のことが言えます。
- 低評価(1と2)にはネガティブなコメントしかない
- 高評価にもネガティブなコメントが多い
- 基本的にはネガティブなコメントが多い
結果一覧
結果を直接確認します。
まずは、ポジティブなコメントから。
つまり、値が1に近いモノということです。
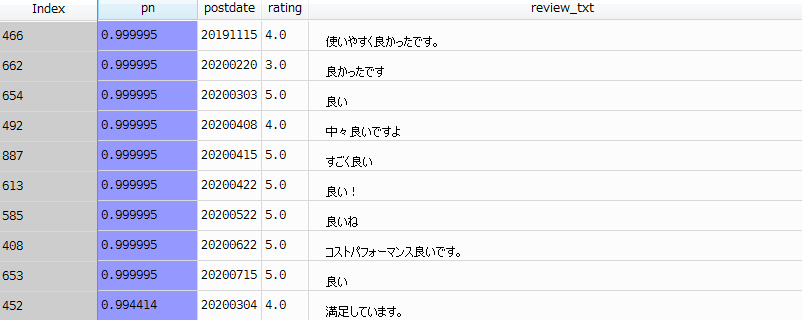
pn:ネガポジ分析の値
rating:Amazonレビューにおける評価(星)
review_text:Amazonレビューにおけるコメント
確かに、肯定的なコメントが並びます。
あと、コメントが短いというのが目立ちますね。
次は、ネガティブなコメントを確認しましょう。
pnが-1に近いモノということです。
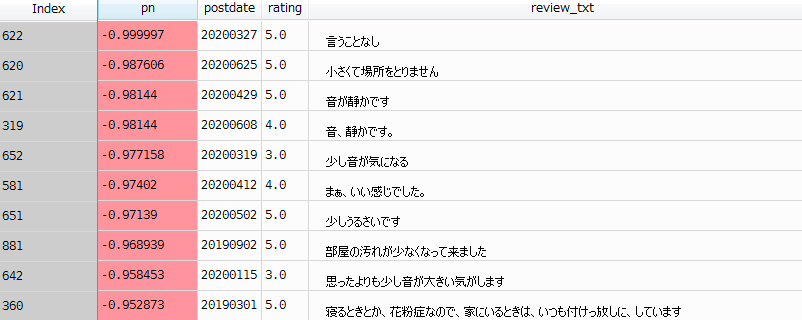
どうもオカシイ。。。
まあ、これが単語感情極性対応表(ネガポジ辞書)を単純に利用した場合の限界ですね。
「言うことなし」の「なし」が、ネガティブ判定されているのです。
「部屋の汚れが少なくなって来ました」では、「汚れ」や「少なく」がネガティブとされているのでしょう。
文脈に沿った分析を行えていないという証拠になります。
単純に、単語で判定するとこのような結果になってしまうのでしょう。
センチメント分析(感情分析)は使えない!?
センチメント分析(感情分析)を行ってきました。
正直、微妙ですね。
散布図を見る限りでは、全く見当違いというわけでもないようです。
そのため、「センチメント分析(感情分析)は使えない」と断定するのは時期早々でしょう。
これは、あくまでセンチメント分析(感情分析)のスタートです。
ここからネガポジ判定の精度をどうやって上げていくのか?
単語感情極性対応表(ネガポジ辞書)にもっと情報を増やすのか?
それとも、文脈を考慮した分析方法があるのか?
センチメント分析(感情分析)における課題ですね。
それでは、最後にセンチメント分析(感情分析)を行ったサンプルコードを載せておきます。
import pandas as pd
import json
import MeCab
import re
import matplotlib.pyplot as plt
import numpy as np
FILE_PATH = "./amazon_data/review.json"
DIC_PATH = "-d ipadic-neologdのパス" # 辞書ipadic-neologdがあれば、そのパスを記述
def get_dic_list(text):
mecab = MeCab.Tagger(DIC_PATH)
parsed = mecab.parse(text)
lines = parsed.split('\n')
lines = lines[0:-2]
dic_list = []
for line in lines:
tmp = re.split('\t|,', line)
dic = {'dsp':tmp[0], 'kind_1':tmp[1], 'kind_2':tmp[2], 'value':tmp[7]}
dic_list.append(dic)
return dic_list
# PN判定
def judge_pn(pn_dict, dic_list):
all_pn = 0
count = 0
result = ""
for word in dic_list:
base = word['value']
if base in pn_dict:
count = count + 1
pn = float(pn_dict[base])
all_pn = all_pn + pn
if all_pn != 0:
result = all_pn / count
return result
# Amazonレビューの読み込み
json_open = open(FILE_PATH, 'r')
review_list = json.load(json_open)
# ネガポジ辞書の読み込み
pn_df = pd.read_csv('dic/pn_ja.dic.txt',\
sep=':',
encoding='utf-8',
names=('Word','Reading','POS', 'PN')
)
# ネガポジ辞書をデータフレームからdict型に変換
word_list = list(pn_df['Word'])
pn_list = list(pn_df['PN'])
pn_dict = dict(zip(word_list, pn_list))
new_review_list = []
for review in review_list:
review_txt = review["review_txt"]
rating = review["rating"]
postdate = review["postdate"]
dic_list = get_dic_list(review_txt)
pn = judge_pn(pn_dict, dic_list)
review["pn"] = pn
if pn:
new_review_list.append(review)
new_review_list_df = pd.DataFrame(new_review_list)
# 欠損値が一つでも含まれる行を削除
new_review_list_df = new_review_list_df.dropna(how='any')
x = new_review_list_df["pn"].astype(float)
y = new_review_list_df["rating"].astype(float)
fig = plt.figure(dpi=100, figsize=(4.6,3.8))
#fig.suptitle('評価:PN', fontsize=10, x=0.27, y=0.87)
ax = fig.add_subplot(111)
ax.yaxis.set_label_coords(-0.07,0.4)
# 目盛の値
xscale = np.arange(-1.0, 1.1, 0.2)
yscale = np.arange(0, 6, 1.0)
# 散布図を描画
plt.scatter(x, y, c='#00FFFF', edgecolors="#37BAF2")
plt.title("評価・PN散布図", fontsize=17)
plt.xticks(xscale, fontsize=8)
plt.yticks(yscale, fontsize=8)
plt.xlabel("PN", fontsize=10)
plt.ylabel("評\n価", fontsize=10, rotation=0)
plt.xlim(-1.1, 1.1)
plt.ylim(0.5, 5.5)
plt.subplots_adjust(left=0.1, right=0.98, bottom=0.13, top=0.89)
plt.savefig("result_1.png", facecolor="white")
"""
# グラフを表示
plt.hist(x)
# グラフを画像保存
plt.savefig("result_2.png", facecolor="white")
"""

