「効果音などの音声ファイルをAIの力で簡単に作成したい」
「画像ができるなら、音声もテキストから生成できるはず・・・」
このような場合には、AudioLDMがオススメです。
この記事では、AudioLDMについて解説しています。
本記事の内容
- AudioLDMとは?
- AudioLDMのシステム要件
- AudioLDMのインストール
- AudioLDMの動作確認
それでは、上記に沿って解説していきます。
AudioLDMとは?
AudioLDMとは、テキストから音声を生成できるAIです。
Stable Diffusionの音声版と言えます。
Audioldm Text To Audio Generation – a Hugging Face Space by haoheliu
https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation
まずは、上記ページで試してみてください。
サーバーが混んでいれば、なかなか返答が戻って来ないかもしれません。
その場合は、次のページでサンプル音声を確認してみましょう。
多くの音声が公開されています。
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models – Speech Research
https://audioldm.github.io/
以上、AudioLDMについて説明しました。
次は、AudioLDMのシステム要件を説明します。
AudioLDMのシステム要件
AudioLDMのシステム要件を説明します。
AudioLDMのsetup.pyには、次のように記載されています。
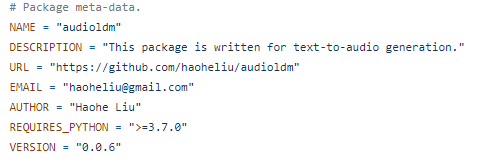
AudioLDMは、現時点ではバージョンが0.0.6となっています。
サポートOSは、以下となります。
- Windows
- macOS
- Linux
GitHubの公式ページでは、次のように記載されています。
A system with a 64-bit operating system (Windows 7, 8.1 or 10, Ubuntu 16.04 or later, or macOS 10.13 or later)
Pythonのバージョンについては、Python 3.7以降となっています。
次のPython公式開発サイクル通りですね。
| バージョン | リリース日 | サポート期限 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
| 3.11 | 2022年10月25日 | 2027年10月 |
また、公式ページでは次のハードウェア要件が記載されています。
- GPU 8GB
- メモリ 16GB
GPU必須ということです。
それに関連して、PyTorchはGPU版をインストールする必要があります。

以上、AudioLDMのシステム要件を説明しました。
次は、AudioLDMのインストールを説明します。
AudioLDMのインストール
AudioLDMには、WebのデモがHugging Faceで公開されていました。
先ほど、紹介したURLのページです。
今回は、これをダウンロードしてローカル環境にインストールしましょう。
おそらく、この方法が最も汎用的で簡単です。
AudioLDMのインストールは、Python仮想環境の利用をオススメします。
Python仮想環境は、次の記事で解説しています。

検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
そして、システム要件であるGPU版PyTorchをインストール済という状況です。
このような状況において、次の手順でAudioLDMのインストールを進めます。
- AudioLDMの取得(Hugging Faceから)
- requirements.txtを使った一括インストール
それぞれを下記で説明します。
AudioLDMの取得(Hugging Faceから)
AudioLDMのファイル
https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation/tree/main
上記ページでファイルを確認できます。
ここでは、ツールを使ってすべてのファイル・ディレクトリをダウンロードします。

huggingface_hubを利用すると、自動的にファイルをダウンロードしてくれます。
huggingface_hubをインストールできたら、次のコードを実行します。
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="haoheliu/audioldm-text-to-audio-generation",
repo_type="space",
revision="main",
cache_dir="./")
上記コードを実行すると、ダウンロード処理が開始されます。
ダウンロードには、少し時間がかかるでしょう。
約2.5GBのモデルが存在しており、それのダウンロードに時間がかかります。
処理が完了すると、ディレクトリ上に「spaces–haoheliu–audioldm-text-to-audio-generation」を確認できます。
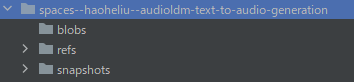
そして、「snapshots」以下にあるファイル・ディレクトリをコピーします。
「9d792c02188b08c7b902afd5e5e8c8ea514edab5」は、リポジトリのバージョンです。
バージョンが更新されれば、この値も変わってきます。
この長たらしいディレクトリより下のモノをコピーしましょう。
コピーしたファイルは、コンテンツルートに保存します。
requirements.txtを使った一括インストール
コンテンツルートには、コピーしたrequirements.txtが存在しています。
requirements.txt
git+https://github.com/huggingface/diffusers.git --extra-index-url https://download.pytorch.org/whl/cu113 torch scipy torchaudio>=0.13.0 torchvision>=0.14.0 tqdm pyyaml einops numpy<=1.23.5 soundfile librosa pandas # transformers torchlibrosa transformers ftfy
PyTorchはインストール済みのため、関連パッケージをコメントにしておきます。
また、Gradioが必要であるため追記します。
#--extra-index-url https://download.pytorch.org/whl/cu113 #torch #torchaudio>=0.13.0 #torchvision>=0.14.0 gradio
Gradioについては、次の記事で説明しています。

変更後のrequirements.txtを利用して、必要なモノを一気にインストールします。
実行するのは、次のコマンドです。
pip install -r requirements.txt
処理完了までは、少し待ちます。
処理が完了したら、AudioLDMのインストールは終了です。
以上、AudioLDMのインストールを説明しました。
次は、AudioLDMの動作確認を説明します。
AudioLDMの動作確認
AudioLDMの動作確認を行います。
コンテンツルートに配置したapp.pyを実行します。
初回実行時には、必要なファイルをダウンロードすることになります。
処理が諸々完了したら、コンソールに以下のように表示されます。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
では、Chromeなどのブラウザで「http://127.0.0.1:7860」にアクセスします。
Hugging Face上のデモと同じような画面を確認できます。
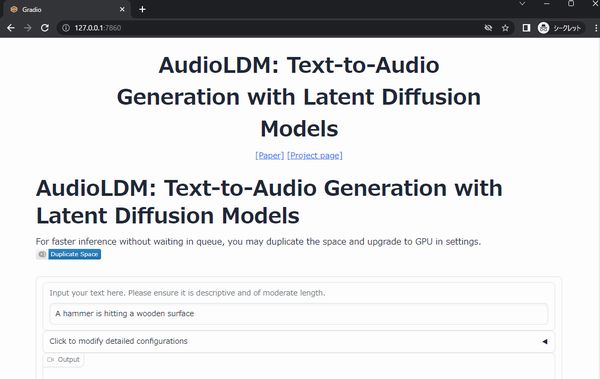
単語の羅列ではなく、文章を英語で入力します。
a man is playing the guitar.
文章の方が、その内容を適切に反映しているように感じます。
入力できたら、「送信」ボタンをクリック。
処理が完了すると、動画が表示されます。
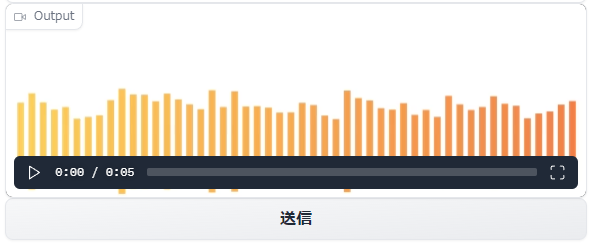
生成された音声は、以下で確認できます。
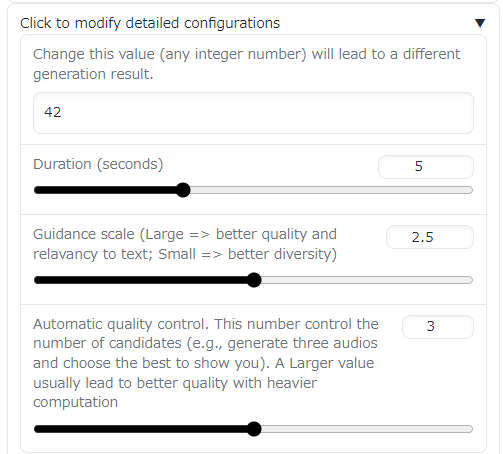
また、設定を変更することで生成される音声の再生時間を変更できます。

上記をクリックすると、設定画面が表示されます。
以上、AudioLDMの動作確認を説明しました。