「テキストから動画を生成したい」
「AUTOMATIC1111版web UIで簡単にtxt2videoを試したい」
このような場合には、ModelScope text2video Extensionがオススメです。
この記事では、web UIでテキストから動画を生成する方法を解説しています。
本記事の内容
- sd-webui-modelscope-text2videoとは?
- sd-webui-modelscope-text2videoのインストール
- sd-webui-modelscope-text2videoの動作確認
それでは、上記に沿って解説していきます。
sd-webui-modelscope-text2videoとは?
sd-webui-modelscope-text2video(以下text2video拡張と呼ぶ)とは、AUTOMATIC1111版web UIのエクステンションです。
GitHub上で公式ページが公開されています。
https://github.com/deforum-art/sd-webui-modelscope-text2video
text2video拡張により、テキストから動画を生成することができます。
この拡張機能は、Text-to-video-synthesisをベースに開発されています。

上記の方法は、公式が公開しているインストール方法に準じています。
ただ、その方法だとインストールが面倒です。
と言うか、初心者では苦労する部分があるでしょう。
それにGUI画面もなく、決して使いやすいとは言えません。
インストールやGUI画面の問題をクリアする方法として、次の方法があります。

単体のWebアプリ方式ですね。
シンプルで使いやすいと言えます。
しかし、これはこれで問題があるようです。
VRAMが、最低でも16GBは必要と言われています。
おそらく、公式の方法でもそれぐらいのVRAMは必要なのかもしれません。
つまり、上記二つの方法ではVRAMの問題があると言うことです。
そのVRAMの問題をクリアする方法として、text2video拡張が存在します。
256×256サイズの動画であれば、8GBのGPUメモリで十分のようです。
8GBであれば、大抵のGPUでも対応できるでしょう。
それに、text2video拡張はweb UIの拡張機能であり、導入が非常に容易です。
以上、sd-webui-modelscope-text2videoについて説明しました。
次は、sd-webui-modelscope-text2videoのインストールを説明します。
sd-webui-modelscope-text2videoのインストール
text2video拡張のインストールを説明します。
その大前提として、AUTOMATIC1111版web UIのインストールは必須です。
まず、「Extensions」タブをクリック。
そして、「Extensions」内の「Install from URL」タブを開きます。
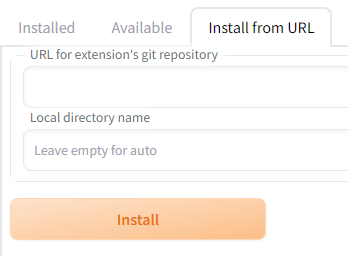
「URL for extension’s git repository」に次のURLを入力します。
https://github.com/deforum-art/sd-webui-modelscope-text2video.git
入力できたら、「Install」ボタンをクリック。
処理が完了したら、「Extensions」内の「Installed」タブをクリック。

sd-webui-modelscope-text2videoがインストールされていることを確認できます。
確認できたら、「Apply and restart UI」ボタンをクリック。
web UIが再表示されれば、次のようにタブが増えていることを確認できます。

これで、text2video拡張のインストールは完了です。
以上、sd-webui-modelscope-text2videoのインストールを説明しました。
次は、sd-webui-modelscope-text2videoの動作確認を説明します。
sd-webui-modelscope-text2videoの動作確認
sd-webui-modelscope-text2videoの動作確認を行います。
ただ、このままでは動作確認ではできません。
動作に必要なモデルをダウンロードする必要があります。
ここは、自分でやらないとダメみたいです。
軽量化されたモデルをダウンロードするようにしましょう。

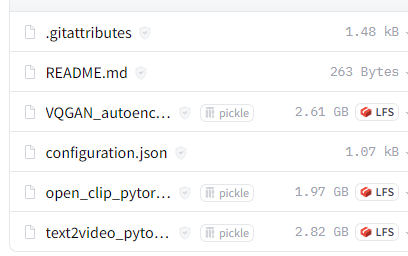
この中で必要なファイルは、以下の4ファイルです。
- VQGAN_autoencoder.pth
- configuration.json
- open_clip_pytorch_model.bin
- text2video_pytorch_model.pth
これらをダウンロードできたら、「models/ModelScope/t2v」に保存します。
「ModelScope」ディレクトリは、自分で作成する必要があります。
もちろん、「t2v」ディレクトリも同様です。
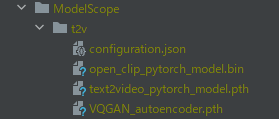
このように保存できたら、準備はOKです。
念のため、web UIは再起動しましょう。
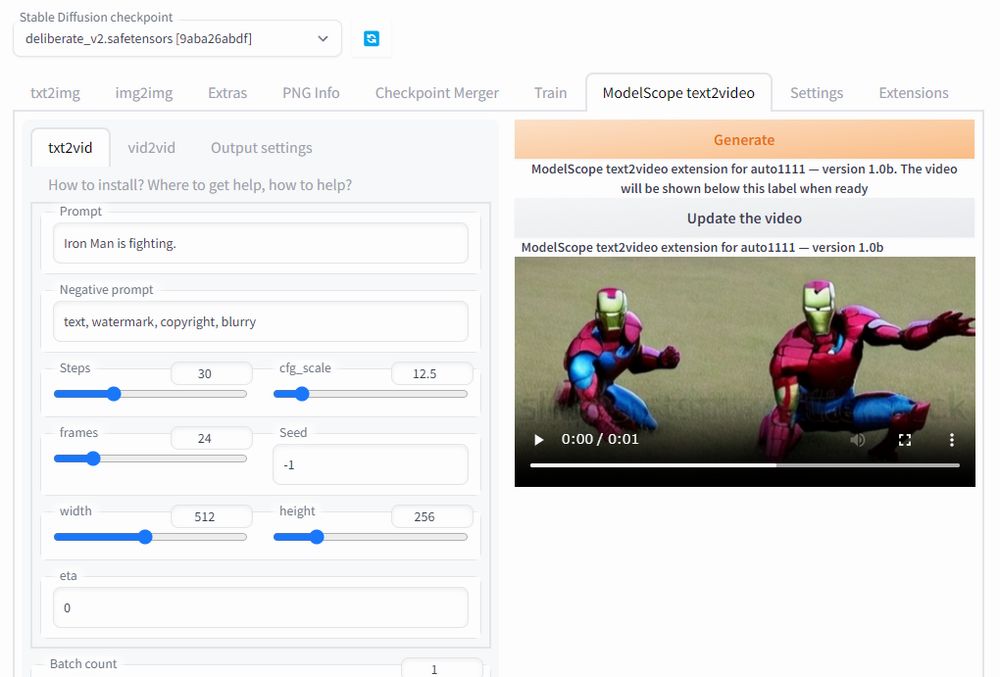
まずは、「ModelScope text2video」タブを開きます。
今回は、「txt2vid」を動作確認します。
※「vid2vid」はこの時点では動きません。
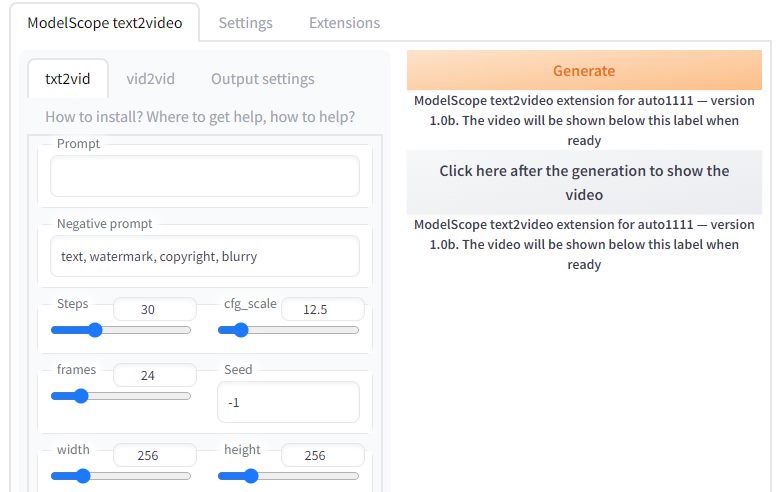
適当にプロンプトを入力して「Generate」ボタンをクリックしましょう。
しかし、現状のバージョンでは画面上では何も動きがありません。
コンソールでは、次のように処理状況を確認できます。
device cuda Working in txt2vid mode latents torch.Size([1, 4, 24, 32, 32]) tensor(0.0003, device='cuda:0') tensor(0.9995, device='cuda:0') DDIM sampling tensor(1): 100%|██████████████████████████████████████████████████████████████████████████████| 31/31 [00:16<00:00, 1.87it/s] STARTING VAE ON GPU. 24 CHUNKS TO PROCESS VAE HALVED DECODING FRAMES VAE FINISHED torch.Size([24, 3, 256, 256])
画面上でも進捗状況を出さないと利用者は不安になってしまうでしょうね。
当面は、コンソールを確認して状況を確認しましょう。
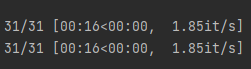
Stitching *video*... Stitching *video*... Video stitching done in 0.20 seconds! t2v complete, result saved at ~outputs/img2img-images\text2video-modelscope\20230325093953
処理が完了したら、コンソールでは上記のように表示されます。
この表示を確認できたら、画面上の「Click here after the generation to show the video」ボタンをクリックします。
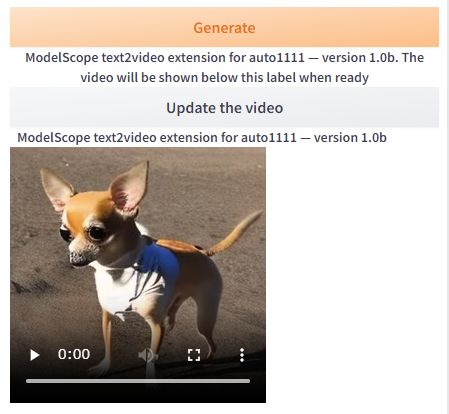
このように生成された動画が表示されます。
次回以降は、「Update the video」ボタンをクリックします。
デフォルトの設定であれば、再生時間が1秒の動画となります。
また、動画生成の処理時間は32秒となっています。
Stepsとframesは、次の値にまで増やすことができます。
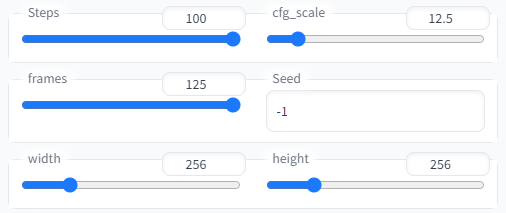
この設定で動画を生成すると、8分36秒の時間がかかりました。

生成された動画の再生時間は、7秒です。
以上、sd-webui-modelscope-text2videoの動作確認を説明しました。