
この記事は、とにかく感情分析をやりたい人向けの記事です。
そして、今回はBERTを用いて日本語テキストの感情分析をしています。
そのため、BERTや機械学習自体を詳しく学びたい人には向かない内容となります。
とにかく実践重視の内容です。
その意味では、感情分析を行いたいプログラマー向きになりますね。
本記事の内容
- プログラマーは機械学習の利用に徹するべし
- 【コード選定】BERTで感情分析を行っているコードを探す
- 【データ準備】Amazonレビューを元にしてデータセットを用意する
- BERTによる日本語の感情分析の結果
- 【サンプルコード】MongoDBからデータ取得する部分
それでは、上記に沿って解説を行っていきます。
プログラマーは機械学習の利用に徹するべし
プログラマーから機械学習エンジニアになる必要はありません。
プログラマーであれば、プログラマーとして培ってきたスキル・経験で機械学習に向き合えばいいのです。
私は、完全にその点では割り切ることができました。
プログラマーであれば、プログラミングができる訳です。
じゃあ、そのプログラミングのスキルを活かしましょう。
主にデータを用意するところでそのスキルを活かすことができます。
あとは、検索スキルですね。
プログラマーは、検索スキルが高いはずです。
その検索スキルを活かして、使えるコードを探します。
使えるコードとは、機械学習を行っているPythonのコードのことです。
ありがたいことに、機械学習のプロが惜しみなくコードを公開してくれています。
だから、それを利用させてもらうのです。
以上をまとめます。
プログラマーは機械学習の利用に徹するべきです。
具体的にどうするのか?
- コード選定
- データ準備
上記の2つです。
プログラマーは、この2つに徹しましょう。
もちろん、コード選定をするためには、ある程度の機械学習に関する理解は必要です。
パラメータの調整を行うことも必要となるでしょうからね。
では、以下でコード選定とデータ準備を行っていく様を解説していきます。
【コード選定】BERTで感情分析を行っているコードを探す
培ってきた検索スキルをフルに活かすところです。
「使えるjQueryプラグインか?」
「使えるライブラリか?」
「使えるフレームワークか?」
このようなことを短時間で検索・検証と実践してきたはずです。
同じノリで検索しましょう。
感情分析で検索した結果、「BERTが感情分析に向いている」ことを掴みました。
Amazonレビューデータのネガポジ分析を行い、従来手法に対するBERTの優位性を示すことができました。
従来手法は、Word2vecのことです。
https://www.keywalker.co.jp/blog/bert-for-engineer.html
簡単に比較した結果は以下。
| 自然言語理技術 | 作成元 | 発表日 |
| BERT | 2018年10月 | |
| Word2vec | 2013年 |
両方ともGoogleというのは、さすがですね。
ただ、5年という期間が両者の間には存在しています。
ITの世界で5年は、とてつもなく長い年月になります。
そう考えると、技術的にもかなり進歩したと捉えるのが自然でしょう。
次に、コード選定の本題です。
BERTで日本語テキストの感情分析(Tensorflow版)
https://qiita.com/namakemono/items/4c779c9898028fc36ff3
BERTを使ったテキスト分類モデルを作る
https://qiita.com/masahikoofjoyto/items/f4a7e95a747b9b64b91d
上記2つが、最終的に候補に残りました。
結果的には、以下のページのコードを使います。
「BERTで日本語テキストの感情分析(Tensorflow版)」
詳しさで言えば、「BERTを使ったテキスト分類モデルを作る」の圧勝です。
でも、「BERTで日本語テキストの感情分析(Tensorflow版)」の方がそのまま流用できそうなのです。
また、「BERTで日本語テキストの感情分析(Tensorflow版)」のコードは、シンプルで利用し易そうなので。
いずれにせよ、機械学習のプロによるコード公開には、感謝です。
追記 2021年8月22日
さらに簡単にできる感情分析の方法があります。
次の記事における方法の方が、初心者にも優しい方法です。

【データ準備】Amazonレビューを元にしてデータセットを用意する
プログラマーの皆さんは、ここでプログラミングのスキルを大いに活かしましょう。
データクレンジングと言われるヤツですね。
このデータクレンジングは、簡単に言えば以下です。
- データ取得
- データ整形
- データ整理
面倒なことに思うかもしれません。
でも、これって以前から普通にやっていることなのですよね。
別システムにデータを移行する場合にも同じことをしています。
だから、取り立てて構える必要はありません。
さて、今回はAmazonレビューを元データにしています。
そうなると、スクレイピングしかありませんね。
確か、レビューはAPIでも取得できないはずです。
そのため、スクレイピングでレビューのデータを集めています。

上記の記事のコードをもとにして、約9000件のレビューを収集しました。
そして、そのレビューに対してラベリングを行っています。
レビュー自体もですが、レビューを構成する文(センテンス)ごとにもラベリング済みです。
このことに関しては、以下の記事で解説しています。

ラベリングには、Google Cloud Natural Language APIを利用します。
APIの利用もプログラマーなら、慣れたものですよね。
以下に、APIを利用してラベリングした結果の一部を載せておきます。
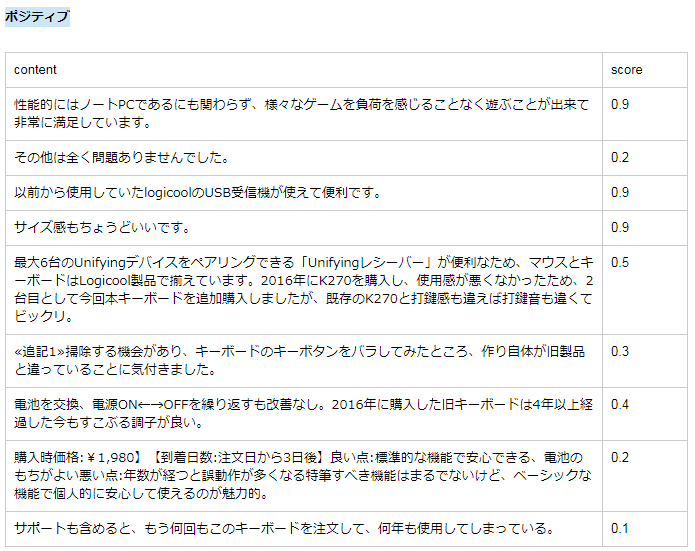

scoreは、-1から1の間の値となります。
-1に近いほど、ネガティブです。
逆に1に近いほど、ポジティブということです。
センテンスの内容と、感情分析の結果(score)は適切だと思いませんか?
やはり、Googleはスゴイですよね。
ここまでいくと、主観に影響される人間がやるよりも適切な結果になると感じます。
人間の主観なんて、それこそバラバラなので。
なお、センテンスは全部で35114件です。
つまり、 35114 件の感情分析されたセンテンスがあるということです。
もうこれは、立派なデータセットと言ってもいいでしょう。
さらに、このデータを加工・整理します。
| 条件 | NP |
| score > 0 | 1 |
| score = 0 | 除去 |
| score < 0 | 0 |
scoreに応じて、ネガティブがポジティブかに分類しておきます。
NPの値が1は、ポジティブ
NPの値が0は、ネガティブ
scoreが0は、除去します。
判定不能の場合は、Googleから「0」としてラベリングされているようです。
BERTによる日本語の感情分析の結果
ここまでくれば、あとは選定したコードに準備したデータを食わせるだけです。
データ数が多ければ、それなりの時間を待つことになります。
もちろん、事前に少ないデータ件数でのテストランは必要です。
プログラムでバッチを作成するときと同じ要領で考えればよいでしょう。
分析対象とするセンテンスは、全部で23260件です。
内訳は以下。
- ポジティブ:11630件
- ネガティブ:11630件
ポジティブとネガティブが同数になるようにしました。
これだけのデータを手動で準備するのは、不可能です。
だからこそ、プログラマーが機械学習の世界に入り込む余地は十分にあります。
で、肝心の結果は以下。
Accuracy: 0.80261
正解率 (Accuracy)は、「本来ポジティブに分類すべきアイテムをポジティブに分類し、本来ネガティブに分類すべきアイテムをネガティブに分類できた割合」を示します。
ということは、80%の確率で正解を導けるモデルができたと言えます。
ただ、参考としたコードのパラメータを全く変更していません。
変更すると数字が変わる可能性があります。
もっと改善するのか、悪化するのかはわかりません。
あと、処理には2時間かかりました。
処理を行なったPCスペックは以下。

7年前のPCです。
CPUのみでGPUはありません。
さすがにこれではマズイです。
今後は、ゲーミングPCの方で処理するようにします。
【追記】2020年08月30日
ゲーミングPCでパラメータと日本語辞書を変更して、再度挑戦しました。
その結果は以下。
Accuracy: 0.87964
詳細は、また別途まとめたいと思います。
【サンプルコード】MongoDBからデータ取得する部分
最後に、今回の処理で作成した関数を載せておきます。
import pandas as pd
from pymongo import MongoClient
from sklearn.model_selection import train_test_split
def get_sentence(client, kind, limit):
db = client.amazon # データベースを取得する。
collection = db.sentence # コレクションを取得する。
#collection.update_many({},{'$set':{'score':""}})
if kind == "P":
result = collection.find({"score": {"$gt": 0 }}).limit(limit)
else:
result = collection.find({"score": {"$lt": 0 }}).limit(limit)
return result
def get_data(limit):
# MogoDB
client = MongoClient("localhost",27017)
sentences_P = get_sentence(client, "P", limit)
df_P = pd.DataFrame(sentences_P)
df_P["NP"] = 1
sentences_N = get_sentence(client, "N", limit)
df_N = pd.DataFrame(sentences_N)
df_N["NP"] = 0
df_P_train, df_P_test = train_test_split(df_P, random_state=0)
df_N_train, df_N_test = train_test_split(df_N, random_state=0)
df_train = pd.concat([df_P_train, df_N_train])
df_test = pd.concat([df_P_test, df_N_test])
train_texts = df_train.content.tolist()
train_labels = df_train.NP.tolist()
test_texts = df_test.content.tolist()
test_labels = df_test.NP.tolist()
return train_texts,train_labels,test_texts,test_labels
基本は、次のコードそのままです。
BERTで日本語テキストの感情分析(Tensorflow版)
https://qiita.com/namakemono/items/4c779c9898028fc36ff3
新作した関数追加の箇所以外は、以下だけ変更しています。
"""
# 訓練データ
train_texts = [
"この犬は可愛いです",
"その猫は気まぐれです",
"あの蛇は苦手です"
]
train_labels = [1, 0, 0] # 1: 好き, 0: 嫌い
# テストデータ
test_texts = [
"その猫はかわいいです",
"どの鳥も嫌いです",
"あのヤギは怖いです"
]
test_labels = [1, 0, 0]
"""
train_texts,train_labels,test_texts,test_labels = get_data(11630)
ベタ書きのlistデータを関数から取得するように変更しています。
正直、MongoDBのデータがなければ役に立たないコードかもしれません。
要望があれば、MongoDBのデータの作り方を記事にします。
さすがに、MongoDBのデータを公開するのはマズイので。
もとがスクレイピングなので、著作権の問題になりかねません。

