
「DeepFloyd IFの使い方がイマイチよくわからない」
「とりあえず、DeepFloyd IFをローカル環境で動かしたい」
このような場合には、この記事の内容が参考になります。
この記事では、DeepFloyd IFを実際に動かす方法を解説しています。
本記事の内容
- DeepFloyd IFとは?
- DeepFloyd IFのシステム要件
- DeepFloyd IFのインストール
- DeepFloyd IFの動作確認
それでは、上記に沿って解説していきます。
DeepFloyd IFとは?
DeepFloyd IFについては、次の記事で解説しています。

上記の記事から、3ヶ月以上が経過しています。
開発元のStability AI社としては、かなり慎重になっていたのでしょう。
コード自体は、数日前に公開されていました。
そして、本日(2023年4月29日)にモデルが公開されたということです。
公式ページでは、次のような画像でDeepFloyd IFについて説明しています。
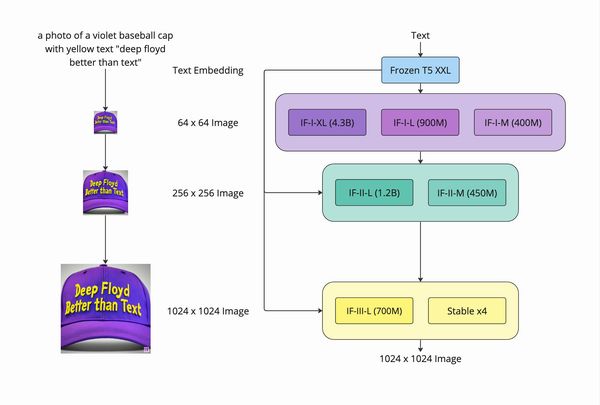
3つのフェーズで処理が行われていることを確認できます。
3つのフェーズがあるということは、頭の片隅にでも置いておきましょう。
詳細は、次のページで日本語で記載されています。
https://ja.stability.ai/blog/deepfloyd-if-text-to-image-model
あと、各フェーズ毎にモデルが用意されているということも認識しておきましょう。
なお、現時点で第3フェーズの「IF-III-L」は公開されていません。
以上、DeepFloyd IFについて説明しました。
次は、DeepFloyd IFのシステム要件を説明します。
DeepFloyd IFのシステム要件
DeepFloyd IFのシステム要件として、PyTorchが必須になります。
バージョンに関しては、1系でも2系でも大丈夫のようです。
ここでは、PyTorch 2.0系のインストールを推奨しておきます。

PyTorch 2.0系の方が処理が断然速いです。
ただし、その場合はDiffusersでDeepFloyd IFを動かすことになります。
DiffusersでDeepFloyd IFを動かす方法の方が、拡張性があります。
別の選択肢であるdeepfloyd_ifライブラリを用いる方法は、PyTorch 1系に限定されています。
そのうち、PyTorch 2.0系でもdeepfloyd_ifが動くようになるとは思いますけどね。
また、PyTorchはGPU版に限ります。
ただし、大きめのモデルだと結構なサイズのVRAMを必要とします。
(小さいサイズのモデルはこれよりはマシなのかもしれません)
- 16GB vRAM for IF-I-XL & IF-II-L
- 24GB vRAM for IF-I-XL & IF-II-L & Stable x4
そして、各GPUのメモリ毎にできる処理が分けられています。
DeepFloyd IFが3つのフェーズで画像生成を行っていましたね。
| 第1 | IF-I-XL(4.3B text to 64×64 base module) |
| 第2 | IF-II-L (1.2B to 256×256 upscaler module) |
| 第3 | Stable x4 (to 1024×1024 upscaler) |
第2フェーズを行うには、16GBが必要ということです。
第3フェーズまで行うには、24GBが必要になることを表しています。
最低でも16GBのVRAMが必要というのは、なかなか厳しい条件です。
ただし、これもそのうち解決されるとは思います。
世界中のハッカーたちが、8GBでも動くようになんとかしてくれるでしょう。
その流れは、Stable DiffusionやDreamBoothで何度も見てきました。
以上、DeepFloyd IFのシステム要件を説明しました。
次は、DeepFloyd IFのインストールを説明します。
DeepFloyd IFのインストール
DeepFloyd IFのインストールは、Python仮想環境の利用をオススメします。
Python仮想環境は、次の記事で解説しています。

検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
そして、システム要件のGPU版PyTorch 2.0系がインストール済みという状況です
このような状況であれば、あとはライブラリのインストールだけで済みます。
すでに述べたように、今回はDiffusersを用いた方法でDeepFloyd IFを利用します。
この場合、次のコマンドを実行することになります。
pip install diffusers accelerate transformers safetensors sentencepiece
インストールが完了したら、DeepFloyd IFを動かせる環境になりました。
ただし、DeepFloyd IFのモデルを利用するには規約への同意が必要です。
Hugging Faceにログインした状態で次のページへアクセスします。

画面上に次のような表示を確認できます。
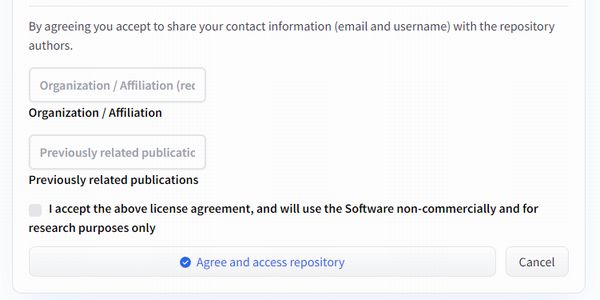
ここに情報を入力して、同意のボタンをクリックします。
各項目は入力必須のため、必要な情報を入力しましょう。
なお、現状ではDeepFloyd IFは研究用ライセンスとなっています。
だからこそ、組織や著書などが聞かれているのです。
しかし、無名の個人が研究したらダメということはありません。
無名の個人であるため、「Free」、「None」と入力しています。
規約に同意できたら、DeepFloyd IFのインストールは完了です。
以上、DeepFloyd IFのインストールを説明しました。
次は、DeepFloyd IFの動作確認を説明します。
DeepFloyd IFの動作確認
DeepFloyd IFの動作確認を行う前に、Hugging Faceのアクセストークンを取得します。
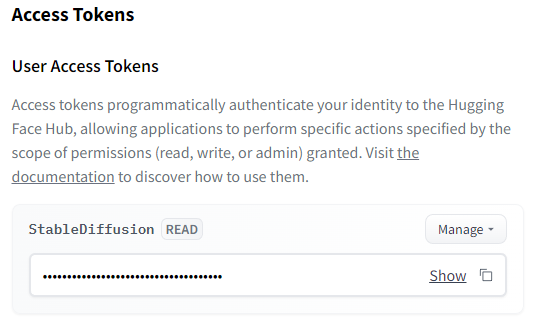
Hugging Faceにログイン済みなら、次のURLで確認できます。
https://huggingface.co/settings/tokens
その取得したアクセストークンを用いて、次のコードを実行します。
from diffusers import DiffusionPipeline
from diffusers.utils import pt_to_pil
import torch
TOKEN = "コピーしたアクセストークン"
# stage 1
stage_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0",
variant="fp16",
torch_dtype=torch.float16,
use_auth_token=TOKEN)
# stage_1.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_1.enable_model_cpu_offload()
# stage 2
stage_2 = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0",
text_encoder=None,
variant="fp16",
torch_dtype=torch.float16,
use_auth_token=TOKEN
)
# stage_2.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_2.enable_model_cpu_offload()
# stage 3
safety_modules = {"feature_extractor": stage_1.feature_extractor, "safety_checker": stage_1.safety_checker, "watermarker": stage_1.watermarker}
stage_3 = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-x4-upscaler", **safety_modules, torch_dtype=torch.float16)
# stage_3.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_3.enable_model_cpu_offload()
prompt = 'Poster on wall that says "COFFEE" inside minimalistic coffee shop, coffee machines, tables, chairs, high detail quality.'
# text embeds
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
generator = torch.manual_seed(0)
image = stage_1(prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt").images
pt_to_pil(image)[0].save("./if_stage_I.png")
image = stage_2(
image=image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt"
).images
pt_to_pil(image)[0].save("./if_stage_II.png")
image = stage_3(prompt=prompt, image=image, generator=generator, noise_level=200).images
image[0].save("./if_stage_III.png")
ただし、初回実行時はかなりの時間を待たされます。
それは、モデルのダウンロードに時間がかかるからです。
Windowsの場合、キャッシュに次のように保存されます。
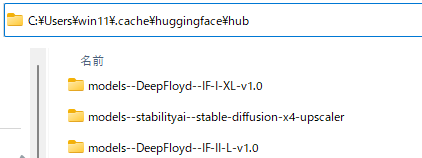
各モデルのサイズは、以下。
| モデル | サイズ |
| IF-I-XL | 19.3GB |
| IF-II-L | 2.88GB |
| stable-diffusion-x4-upscaler | 3.23GB |
結構デカいです。
それもあって、画像生成の処理自体にも時間がかかります。

全部で2分30秒の時間を要した処理の場合に、上記のように表示されています。
そのため、これが総処理時間ではないことは確実です。
時間がかかる以前に、処理中に他の操作が何もできなくなる瞬間があります。
もちろん、各自の環境でそれは異なってくるとは思います。
ちなみに、検証に用いた環境はGeForce RTX 3090(24GB)を搭載済みです。
GeForce RTX 4090なら、ストレスなく動かせるのかもしれません。
とにかく、世界中の優秀な開発者たちに期待しましょう。
最後に、上記コードで生成できた画像を確認しておきます。

「COFFEE」という文字が、綺麗に表示されています。
「IF」というロゴは、第3フェーズの高解像度画像にだけ付くようです。
以上、DeepFloyd IFの動作確認を説明しました。

