
「FAQチャットボットの作り方がわからない・・・」
「専門知識が必要な問い合わせシステムを開発したい」
このような場合には、GPT Indexがオススメです。
この記事では、GPT Indexについて解説しています。
本記事の内容
- GPT Indexとは?
- GPT Indexのシステム要件
- GPT Indexのインストール
- Open AIのAPI key取得
- GPT Indexの動作確認
それでは、上記に沿って解説していきます。
GPT Indexとは?
GPT Indexは、その名前の通りにindex(インデックス)を作成するライブラリです。
GPT-3をLLM(大規模言語モデル)として、API経由で利用します。
そのため、基本的にはGPT Indexを動かすにはOpen AIに課金することになります。
ここは、GPT-3の性能を望む以上は仕方がないのでしょうね。
そんな有償のGPT-3を利用して、GPT Indexでは何ができるのでしょうか?
GPT Indexを用いれば、専門知識を必要とする質疑応答システムを開発することができます。
汎用的なチャットボットではなく、専門知識というところがポイントです。
企業であれば、自社サービス・製品に特化したチャットボットを開発することが可能になります。
また、現状でGPT-3(davinciモデル)には4096トークンという限界が存在します。
しかし、GPT Indexを用いればその限界を突破することが可能になります。
その限界に収めて、APIに問い合わせるというような機能なのでしょう。
その意味では、GPT-3へのデータアクセスの管理を行うライブラリとしても使えそうです。
以上、GPT Indexについて説明しました。
次は、GPT Indexのシステム要件を説明します。
GPT Indexのシステム要件
現時点(2023年1月17日)でのGPT Indexの最新バージョンは、0.2.4となります。
この最新バージョンは、2023年1月16日にリリースされています。
サポートOSに関しては、以下を含むクロスプラットフォーム対応だと思われます。
明示されていませんが、OSを問わないコードになっています。
- Windows
- macOS
- Linux
サポート対象となるPythonのバージョンも明示はされていません。
ただ、Python 3.8以降でテストを実施したことが記載されています。
それに従う方がトラブルはないでしょう。
個人的には、次のPython公式開発サイクルに従えばOKと思います。
| バージョン | リリース日 | サポート期限 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
| 3.11 | 2022年10月25日 | 2027年10月 |
これらが、GPT Indexのシステム要件となります。
普通の環境であれば、GPT Indexは問題なくインストール可能でしょう。
以上、GPT Indexのシステム要件を説明しました。
次は、GPT Indexのインストールを説明します。
GPT Indexのインストール
検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
まずは、現状のインストール済みパッケージを確認しておきます。
> pip list Package Version ---------- ------- pip 22.3.1 setuptools 65.7.0 wheel 0.37.1
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、GPT Indexのインストールです。
GPT Indexのインストールは、以下のコマンドとなります。
pip install gpt-index
GPT Indexのインストールは、しばらく時間がかかります。
処理が終了したら、どんなパッケージがインストールされたのかを確認します。
> pip list Package Version ------------------ ---------- aiohttp 3.8.3 aiosignal 1.3.1 async-timeout 4.0.2 attrs 22.2.0 blobfile 2.0.1 certifi 2022.12.7 charset-normalizer 2.1.1 click 8.1.3 colorama 0.4.6 dataclasses-json 0.5.7 filelock 3.9.0 frozenlist 1.3.3 gpt-index 0.2.4 greenlet 2.0.1 html2text 2020.1.16 huggingface-hub 0.11.1 idna 3.4 joblib 1.2.0 langchain 0.0.63 lxml 4.9.2 marshmallow 3.19.0 marshmallow-enum 1.5.1 multidict 6.0.4 PyYAML 6.0 regex 2022.10.31 requests 2.28.2 setuptools 65.7.0 six 1.16.0 SQLAlchemy 1.4.46 tenacity 8.1.0 tiktoken 0.1.2 tokenizers 0.13.2 tqdm 4.64.1 transformers 4.25.1 typing_extensions 4.4.0 typing-inspect 0.8.0 urllib3 1.26.14 wheel 0.37.1 yarl 1.8.2
GPT Indexは、これだけのパッケージに依存していることが確認できます。
だから、インストールにそこそこ時間がかかるわけですね。
インストールができたら、動作確認を行います。
ただ、GPT IndexはGPT-3のAPIに依存していました。
そのため、動作確認の前にAPI keyの取得が必要となります。
以上、GPT Indexのインストールを説明しました。
次は、Open AIのAPI key取得を説明します。
Open AIのAPI key取得
Open AIのアカウントが必須です。
アカウントがない場合は、次のページから作成してください。
https://beta.openai.com/signup/
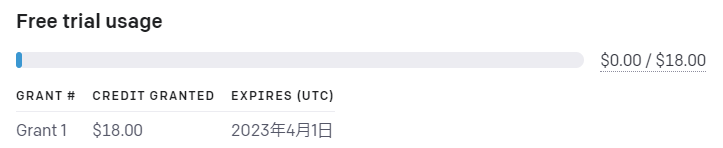
アカウントを新規で作成したら、無料で18ドル分の課金枠が付与されています。
アカウントが用意できたら、Open AIにログインしましょう。
Open AIにログインしたら、ユーザーアイコンをクリック。
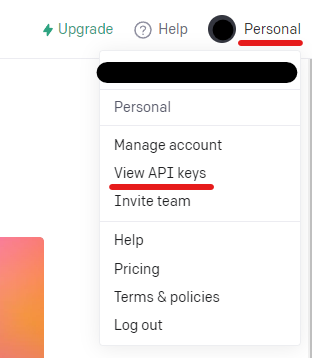
ここで、「View API keys」メニューを選択します。
この画面でAPI keyの管理を行います。
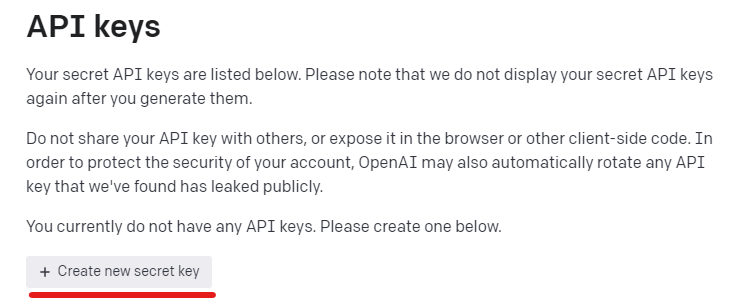
API keyを新規で作る場合は、「Create new secret key」ボタンをクリック。
そうすると、次のポッポアップが表示されます。
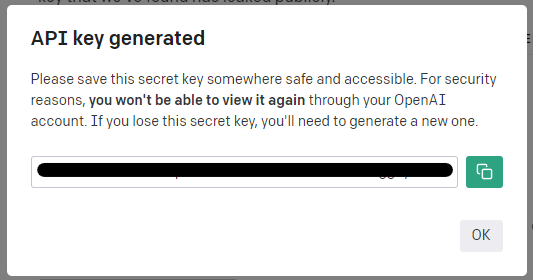
新規に作成したAPI keyを確認できます、。
「OK」ボタンをクリックする前に、API Keyをコピーしておきましょう。
API keyのコピーは、コピーボタンを押せばOK。
コピーする前に「OK」ボタンを押したら、API keyを再度新規作成しましょう。
その場合、不要なAPI keyはゴミ箱をクリックして削除しておきます。
API keyが取得できたら、GPT Indexの動作確認を行います。
以上、Open AIのAPI key取得を説明しました。
次は、GPT Indexの動作確認を説明します。
GPT Indexの動作確認
今回は、Webページの内容をGPT-3に理解させます。
そして、そのページの内容について質疑応答を行うという流れです。
その流れをGPT Index風に表現すると、以下になります。
- indexの作成・保存
- indexの読み込み(質疑応答)
Webページの内容を取得するために必要なライブラリがあります。
以下のコマンドにより、追加でインストールします。
pip install html2text
indexの作成・保存
まずは、indexの作成です。
indexは、GPT-3で管理しやすいデータに変換したモノと言えます。
実際のデータは、後ほど確認しましょう。
今回は、「OpenAI」のWikipediaページを対象とします。
そのページのindexを作成して保存するコードは、以下となります。
なお、課金が発生するために実行の際には慎重に作業しましょう。
無駄に課金されたくありませんからね。
test_save.py
import os from gpt_index import GPTSimpleVectorIndex, SimpleWebPageReader os.environ["OPENAI_API_KEY"] = "your_API_key" json_path = "./data/wiki.json" url = "https://ja.wikipedia.org/wiki/OpenAI" documents = SimpleWebPageReader(html_to_text=True).load_data([url]) index = GPTSimpleVectorIndex(documents) index.save_to_disk(json_path)
「your_API_key」には、あなたの取得したAPI keyを設定します。
上記を実行した結果、コンソールには次のように表示されます。
> Adding chunk: コンテンツにスキップ
サイドバーの切り替え [  [2]
ウェブサイト| ...
> Adding chunk: GPT-3[[編集](/w/index.php?title=OpenAI&action=edi...
> Adding chunk: "Category:アメリカ合衆国の研究所")
* [サンフランシスコの企業](/wiki...
> [build_index_from_documents] Total LLM token usage: 0 tokens
> [build_index_from_documents] Total embedding token usage: 15239 tokens
対象ページを読み込んでいる感じが、わかりますね。
処理が完了すると、jsonファイルが作成されています。

ページの文章は、5分割(nodes_dict数)されています。
それらは、ベクトルとして保存されていることが確認できます。

ここまでの処理でindexを保存することができました。
indexの読み込み(質疑応答)
次は、先ほど作成したindexを利用して質疑応答を行います。
ただし、一つ注意点があります。
注意点とは、課金は質疑応答毎(indexの照会)に発生するということです。
保存したindexを利用すれば、indexの作成時にAPIをコールする必要はありません。
つまり、indexの作成分のコストは節約できます。
しかし、読み込んだindexをもとに問い合わせを行う場合にはAPIがコールされます。
この部分では、毎回課金が行われるということです。
Open AIの「Usage」で課金状況を確認できます。
https://beta.openai.com/account/usage
もちろん、同じような質疑応答に関しては課金を発生させないことも可能です。
ただし、それはデータベースを用意してロジックを組む必要があります。
GPT Indexにそのような機能があれば、とてもありがたいのですけどね。
今のところ、そのような機能は見つけられていません。
では、indexの読み込みと質疑応答を行っていきましょう。
コードは、以下を用います。
test_load.py
import os
from gpt_index import GPTSimpleVectorIndex
os.environ["OPENAI_API_KEY"] = "your_API_key"
json_path = "./data/wiki.json"
index = GPTSimpleVectorIndex.load_from_disk(json_path)
print(index.query("設立はいつ?"))
print(index.query("設立者は?"))
print(index.query("所在地は?"))
print(index.query("何をしている会社?"))
保存したindexをロードしています。
この部分の課金は、発生しません。
上記コードでは、4つの質問を行っています。
この部分では、課金が毎回(トークン数による従量課金)発生します。
その返答として、コンソールには次のように結果が表示されています。
> [query] Total LLM token usage: 1811 tokens > [query] Total embedding token usage: 12 tokens 2015年 > [query] Total LLM token usage: 1819 tokens > [query] Total embedding token usage: 10 tokens 設立者は不明です。 > [query] Total LLM token usage: 1827 tokens > [query] Total embedding token usage: 10 tokens 所在地はアメリカ合衆国です。 > [query] Total LLM token usage: 2557 tokens > [query] Total embedding token usage: 15 tokens OpenAIは、人工知能(AI)研究所であり、人類全体に利益をもたらす形で友好的なAIを普及・発展させることを目標に掲げ、AI分野の研究を行っている会社です。
返答結果は、ほとんど正しいです。
ただ、設立者については微妙と言えます。

複数の名前が記載されているから、不明となったのかもしれません。
他の回答は、完璧です。
以上、GPT Indexの動作確認を説明しました。

