
OpenCVでは、簡単に物体検出が可能です。
例えば、顔認証・顔検出は簡単にできます。
しかし、それを特定の人間だけの顔を対象にするとなると、どうでしょうか?
一気にハードルが上がるように感じませんか?
データを集めるという点では、難しいかもしれません。
ただ、特定の顔だけを学習させることは、それほど難易度の高いことではありません。
この記事では、OpenCVに学習させる方法について解説しています。
OpenCVの用語を使えば、カスケード分類器を自作する方法を解説します。
本記事の内容
- OpenCVでの物体検出の仕組み
- OpenCVのダウンロード
- 画像の準備
- カスケード分類器の作成
- 自作したカスケード分類器の検証
それでは、上記に沿って解説していきます。
OpenCVでの物体検出の仕組み
OpenCVでは、カスケード分類器によって物体検出を行っています。
カスケード分類器とは、検出したい物体の特徴をギュッとまとめたデータを指します。
この特徴のことを、特徴量と呼びます。
つまり、カスケード分類器は物体の特徴量をまとめたデータと言えます。
そして、OpenCVでは最初から複数のカスケード分類器を用意してくれています。
OpenCVで簡単に顔認識・顔検出ができるのも、そのおかげです。
OpenCVによる顔認識・顔検出は、次の記事で解説しています。

以上、OpenCVでの物体検出の仕組みでした。
これ以降は、ここでの理解が前提となります。
OpenCVのダウンロード
OpenCVのダウンロードをしていきます。
しかし、この時点ですでにPythonからOpenCVを利用できていることが前提です。
もっと言うと、次の記事の内容は済ませている必要があります。

では、なぜ改めてOpenCVをダウンロードするのか?
それは、カスケード分類器を作るためです。
そのために必要なツールがOpenCVに同梱されています。
今回は、そのツールが欲しいだけです。
それでは、いざダウンロードページへ。
OpenCV公式サイト
https://opencv.org/releases/
上記ページへアクセス。
OpenCVのバージョン3系と4系が、存在しています。
カスケード分類器の自作で必要なツールは、3系にのみ含まれています。
なぜ4系にはないのか、そのあたりの事情はわかりません。
とりあえず、3系を選んでダウンロードします。
2020年12月8日時点では、3系では3.4.12が最新バージョンです。
利用している環境は、「Windows」です。
選択してダウンロードします。
ダウンロードしたexeを実行します。
解凍先を聞いてくるので、適当な場所を指定してください。
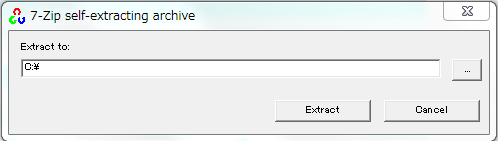
「Extract」をクリックすると、処理が始まります。
今回は、「C:\」を選択。
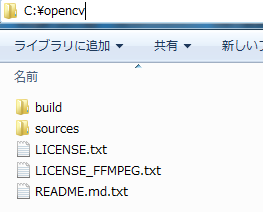
処理が終わると、選択した場所にopencvフォルダが作成されています。
作成されたことを確認できれば、「C:\opencv\build\x64\vc15\bin」へ移動します。
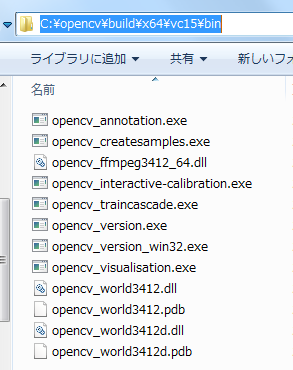
ここで重要なのは、次のファイルです。
- opencv_createsamples.exe
- opencv_traincascade.exe
- opencv_world3412.dll
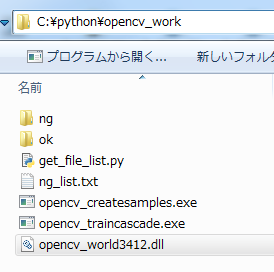
この3ファイルを適当な場所へコピーしてください。
その場所で、カスケード分類器を作成する作業を行います。
今回は、以下のフォルダを用意。
C:\python\opencv_work
ここに先ほどの3ファイルをコピーします。
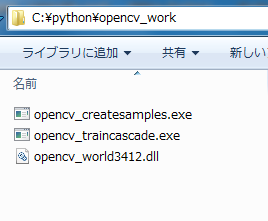
以上で、OpenCVのダウンロードに関する解説を終わります。
ここまでの作業により、カスケード分類器を自作するために必要なツールを準備できました。
次は、そのツールを使って画像を準備します。
カスケード分類器を作成するためには、多くの画像が必要となります。
その画像を準備していきましょう。
画像の準備
カスケード分類器を作成するためには、多くの画像が必要です。
検出したい物体の画像を正解画像とします。
そして、検出したい物体に関係のない画像を不正解画像とします。
OpenCVの公式サイトによると、使えるレベルのカスケード分類器を作るためには以下のサンプル数が必要とのこと。
- 正解画像:7000枚
- 不正解画像:3000枚
正直、これだけ用意するのは無理ゲーです。
でも、実際にビジネスで利用するなら、これぐらいは必須でしょうね。
別々の方法で、正解画像と不正解画像を準備しましょう。
正解画像
ただ、個人でこれだけ集めるのは困難です。
そこで、ダウンロードしたツールの出番となります。
2つのexeがありましたね。
そのうちに、「opencv_createsamples.exe」を利用します。
このプログラムを利用すると、1枚の画像から1000枚の画像を用意できます。
いろんなバリエーションで画像を自動作成してくれます。
その便利なプログラム「opencv_createsamples.exe」を利用してみましょう。
まず、以下のフォルダに正解画像を1枚設置します。
C:\python\opencv_work\ok
なお、正解画像は以下とします。
ファイル名は、ok.pngです。

これをベースにして、1000枚の画像を作成します。
画像を設置したら、コマンドプロンプトかPowerShellのどちらかを起動します。
そして、作業場所となるC:\python\opencv_workまで移動します。
そこで次のコマンドを実行。
.\opencv_createsamples.exe -img ./ok/ok.png -num 1000 -vec ok.vec
実行した結果は、以下。
PS C:\python\opencv_work> .\opencv_createsamples.exe -img ./ok/ok.png -num 1000 -vec ok.vec Info file name: (NULL) Img file name: ./ok/ok.png Vec file name: ok.vec BG file name: (NULL) Num: 1000 BG color: 0 BG threshold: 80 Invert: FALSE Max intensity deviation: 40 Max x angle: 1.1 Max y angle: 1.1 Max z angle: 0.5 Show samples: FALSE Width: 24 Height: 24 Max Scale: -1 RNG Seed: 12345 Create training samples from single image applying distortions... Done
作業場所フォルダを確認します。
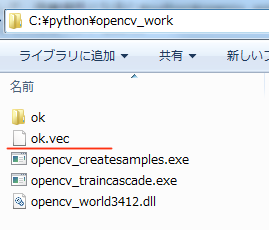
しかし、1000枚の画像は見当たりません。
実は、ok.vecに1000枚の画像がまとめられています。
以上より、1000枚の正解画像を準備できました。
不正解画像
不正解画像は、正解画像と異なり比較的容易に準備できます。
正解画像と異なっていれば、それでOKです。
機械学習のデータセットを適当に探せば、画像一覧は見つかります。
https://lionbridge.ai/ja/datasets/20-best-image-datasets-for-computer-vision/
取得した画像をC:\python\opencv_work\ngに保存します。
全部で100個の不正解画像を用意できました。
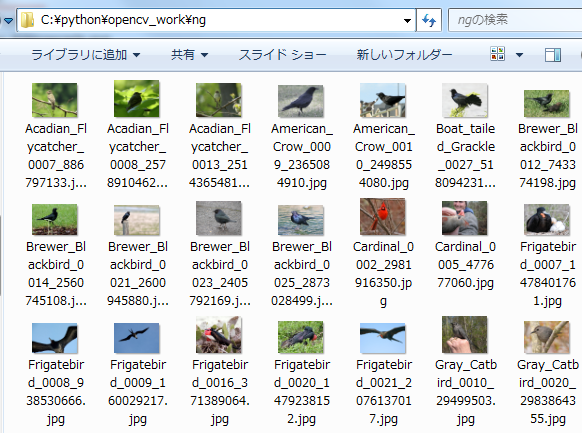
鳥のデータセットから100個ほど抽出しました。
全部で6000個以上ありました。
さて、不正解画像に関しては一つのvecファイルに集約していません。
そこで、不正解画像の名称一覧を記したファイルを用意しないといけません。
Pythonを使って、ファイル一覧を作成します。
その際のコードは、以下。
get_file_list.py
import os
list_file = "ng_list.txt"
path = "./ng/"
all_str = ""
files = os.listdir(path)
for file in files:
str = path + file
all_str = all_str + str + "\n"
with open(list_file, mode='w',encoding="utf-8") as f:
f.write(all_str)
get_file_list.pyを作業場所C:\python\opencv_workに設置して、実行するだけです。
ng_list.txtが作成されます。
ng_list.txtの内容は、以下。
./ng/Acadian_Flycatcher_0007_886797133.jpg ./ng/Acadian_Flycatcher_0008_2578910462.jpg ./ng/Acadian_Flycatcher_0013_2514365481.jpg ./ng/American_Crow_0009_2365084910.jpg ./ng/American_Crow_0010_2498554080.jpg ./ng/Boat_tailed_Grackle_0027_518094231.jpg ./ng/Brewer_Blackbird_0012_743374198.jpg ./ng/Brewer_Blackbird_0014_2560745108.jpg ./ng/Brewer_Blackbird_0021_2600945880.jpg ./ng/Brewer_Blackbird_0023_2405792169.jpg ・・・
ファイル数と同じで100行あります。
これにて、不正画像の方も準備が整いました。
カスケード分類器の作成
カスケード分類器を作成します。
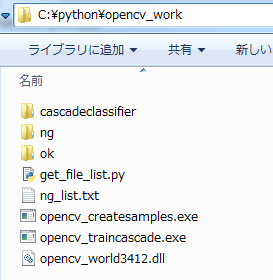
まずは、作成したカスケード分類器を保存するフォルダの作成です。
作業場所C:\python\opencv_workに「cascadeclassifier」フォルダを作成します。
実際に学習させていきます。
その際に利用するツールは、「opencv_traincascade.exe」です。
次のような使い方をします。
.\opencv_traincascade.exe -data ./cascadeclassifier/ -vec ./ok.vec -bg ./ng_list.txt -numPos 900 -numNeg 100
numPosには、正解画像数を指定します。
ただ、今回は900を指定しています。
正解画像枚数×0.9を目安にして値を設定すればいいようです。
このことにより、100個ほどは利用不可の画像があっても無視してくれます。
仮に1000を指定して1枚でも利用不可の画像があれば、エラーとなります。
0.9の値を指定するのは、そのエラーになるのを防ぐ意味があると考えてください。
つまり、100個は利用不可の画像が存在していても、スルーして処理を継続するということです。
numNegは、不正解画像の画像数です。
厳密に言うと、ng_list.txtに指定した画像数となります。
実際、上記コマンド実行した結果は以下。
PS C:\python\opencv_work> .\opencv_traincascade.exe -data ./cascadeclassifier/ -vec ./ok.vec -bg ./ng_list.txt -numPos 900 -numNeg 100 PARAMETERS: cascadeDirName: ./cascadeclassifier/ vecFileName: ./ok.vec bgFileName: ./ng_list.txt numPos: 900 numNeg: 100 numStages: 20 precalcValBufSize[Mb] : 1024 precalcIdxBufSize[Mb] : 1024 acceptanceRatioBreakValue : -1 stageType: BOOST featureType: HAAR sampleWidth: 24 sampleHeight: 24 boostType: GAB minHitRate: 0.995 maxFalseAlarmRate: 0.5 weightTrimRate: 0.95 maxDepth: 1 maxWeakCount: 100 mode: BASIC Number of unique features given windowSize [24,24] : 162336 ===== TRAINING 0-stage ===== <BEGIN POS count : consumed 900 : 900 NEG count : acceptanceRatio 100 : 1 Precalculation time: 1.837 +----+---------+---------+ | N | HR | FA | +----+---------+---------+ | 1| 1| 0| +----+---------+---------+ END> ・・・
===== TRAINING 0-stage =====
処理が進むにつれて、数字増えていきます。
今回のケースでは、4まで進みました。
===== TRAINING 4-stage ===== <BEGIN POS count : consumed 900 : 900 NEG count : acceptanceRatio 0 : 0 Required leaf false alarm rate achieved. Branch training terminated.
メッセージだけ見ると、途中で強制的に終了したようです。
しかし、このメッセージはエラーを表しているわけではありません。
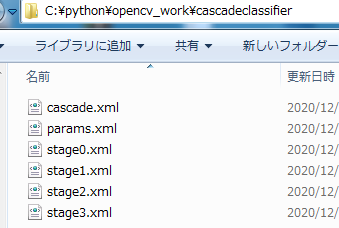
cascade.xmlは、作成されています。
精度はともあれ、これでカスケード分類器を作成できました。
カスケード分類器の作成方法自体は、それほど難しいことではありません。
ただ、その精度がどうかということです。
自作したカスケード分類器の検証
作成したcascade.xmlは、単体(コピーして移動可)で利用可能です。
次のコードで、自作したカスケード分類器の検証ができます。
import cv2
XML_PATH = "cascade.xml"
INPUT_IMG_PATH = "input.png"
OUTPUT_IMG_PATH = "output.png"
classifier = cv2.CascadeClassifier(XML_PATH)
img = cv2.imread(INPUT_IMG_PATH)
color = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
targets = classifier.detectMultiScale(color)
for x, y, w, h in targets:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imwrite(OUTPUT_IMG_PATH, img)
以下は、各自の環境に合わせて変更してください。
XML_PATH = "cascade.xml" INPUT_IMG_PATH = "input.png" OUTPUT_IMG_PATH = "output.png"
実行した結果、以下。
input.png

output.png

まあ、物体検出できていると言えばできています。
ただし、その精度は微妙です。
では、次の画像を読み込んでみましょう。
input.png

結果は・・・
以下です!!
output.png

物体検出が一切行われれていません。
若干、ファイルサイズが大きくなっただけです。
この結果だけ見ると、カスケード分類器の作成に失敗しているように感じます。
しかし、一つの前の検証では物体検出はできてはいます。
精度は、微妙ですが。。。
つまり、学習させたデータがダメということなのでしょう。
データ数(画像数)も少ないし、データとしての質も低かったのかもしれません。
今度は、データの量・質ともに上げてみます。
そうすれば、もっと精度の高い物体検出ができるようになるはず。
では、またそのときまでサヨウナラ。

