この記事では、Pythonで回帰分析を行う方法を説明します。
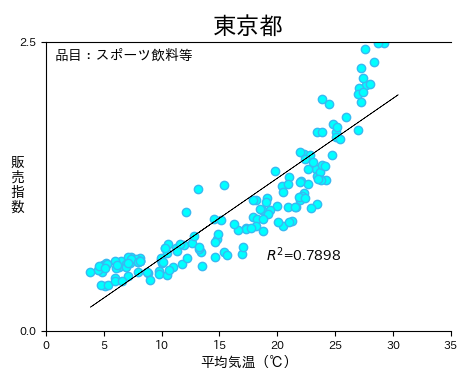
また、次のような散布図に回帰直線を描画するための説明も行います。
本記事の内容
- Pythonで回帰分析を行う環境
- Pythonで散布図を作成する
- Pythonで回帰分析を行う
- Pyhtonで散布図に回帰直線を引く
上記の項目に沿って、本記事の説明を行います。
まずは、この記事で用いた環境の説明からです。
Pythonで散布図を作成するための環境
- Windows 10 Home (バージョン1909)※以下の説明は64bit前提
- Python 3.7.3
- NumPy 1.18.5
- Matplotlib 3.2.1
- Pandas 0.24.2
- scikit-learn 0.20.3
- xlrd 1.2.0
Pythonの上記ライブラリは、すべてインストールしておいてください。
ほぼ、インストール済みとは思いますが、念のためインストールコマンドを載せておきます。
pip install numpy pip install matplotlib pip install pandas pip install scikit-learn pip install xlrd
Matplotlibのグラフを日本語化対応していない場合は、以下の記事をご覧ください。
この記事を参考にすれば、日本語化対応が簡単にできます。

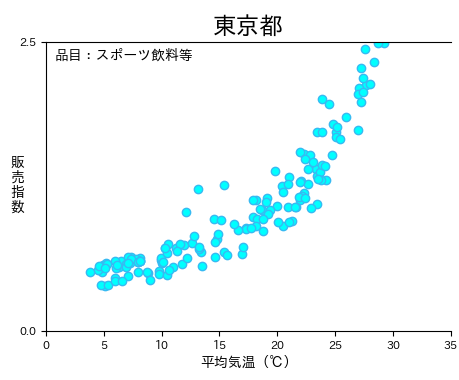
Pythonで散布図を作成する
散布図の作成は、次の記事をご覧ください。
Matplotlibを使ったグラフ作成の基本から学ぶことができます。

早くPythonで回帰分析の方法を確認したい場合は、下記のコードを利用してください。
環境さえ整っていれば、コピペで動きます。
以下、下記コードを「散布図作成コード」と呼びます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('data/DL4.xls', sheet_name=0)
# 欠損値が一つでも含まれる行を削除
df = df.dropna(how='any')
x = df['週別気温']
y = df['週別指数']
# 目盛の値
x_scale = 5
y_scale = 2.5
xscale = np.arange(0, (max(x)+1)*x_scale, x_scale)
yscale = np.arange(0, (max(y)+1)*y_scale, y_scale)
fig = plt.figure(dpi=100, figsize=(4.6,3.8))
fig.suptitle('品目:スポーツ飲料等', fontsize=10, x=0.27, y=0.87)
ax = fig.add_subplot(111)
ax.yaxis.set_label_coords(-0.07,0.4)
# 散布図を描画
plt.scatter(x, y, c='#00FFFF', edgecolors="#37BAF2")
plt.title("東京都", fontsize=17)
plt.xticks(xscale, fontsize=8)
plt.yticks(yscale, fontsize=8)
plt.xlabel("平均気温(℃)", fontsize=10)
plt.ylabel("販\n売\n指\n数", fontsize=10, rotation=0)
plt.xlim(0, 35)
plt.ylim(0.0, 2.5)
plt.gca().spines['right'].set_visible(False)
plt.subplots_adjust(left=0.1, right=0.98, bottom=0.13, top=0.89)
plt.savefig("result1.png", facecolor="white")
ただし、エクセルデータ「DL4.xls」のダウンロードは、必要です。
上の記事にダウンロード方法を載せています。
エクセルファイルも用意して、上記のコードを実行すると以下のグラフが表示(保存)されます。
よって、上記コードをもとに回帰分析を行っていきます。
結果的に、上の散布図に回帰直線が描画されることになります。
また、決定係数の表示も対応します。
Pythonで回帰分析を行う
ここまでの準備が整っていれば、簡単にPythonで回帰分析は可能です。
なお、回帰分析には、機会学習用のライブラリであるscikit-learnを利用します。
上記で載せた「散布図作成コード」に、コードを追加します。
そして、追加したコードは以下。
2か所に追加しています。
from sklearn.linear_model import LinearRegression
まずは、必要モジュールの読み込みですね。
「LinearRegression」は、線形回帰と表しています。
そのままの名前のモジュールをimportです。
# 回帰分析 線形
mod = LinearRegression()
df_x = pd.DataFrame(x)
df_y = pd.DataFrame(y)
# 線形回帰モデル、予測値、R^2を評価
mod_lin = mod.fit(df_x, df_y)
y_lin_fit = mod_lin.predict(df_x)
r2_lin = mod.score(df_x, df_y)
ax.text(19.0, 0.6, '$ R^{2} $=' + str(round(r2_lin, 4)))
plt.plot(df_x, y_lin_fit, color = '#000000', linewidth=0.5)
fit関数では、DataFrameを引数にしています。
そのため、xやyをSeriesからDataFrameに変換する必要があります。
それ以外は、おまじないのようなモノです。
mod_linとy_lin_fitは、回帰直線を描くために必要となります。
r2_linは、決定係数です。
この決定係数は、0~1の間の値を取ります。
この記事では、回帰分析の説明自体を行いません。
あくまでPythonで回帰分析を行う方法を説明することが目的です。
話がそれましたが、Pythonでの回帰分析はたった数行でできます。
これもすべて、便利なライブラリのおかげです。
ここまでライブラリが便利だと、関数に渡すデータを用意するまでポイントになりますね。
今回のプログラムであれば、df_xとdf_yを作るまでと言えます。
Pythonで回帰分析を行う方法は、以上です。
Pyhtonで散布図に回帰直線を引く
散布図に回帰直線を描画・決定係数を表示するコードは以下。
ax.text(19.0, 0.6, '$ R^{2} $=' + str(round(r2_lin, 4)))
plt.plot(df_x, y_lin_fit, color = '#000000', linewidth=0.5)
たった、2行です。
もし、axやpltの詳細を知りたい場合は、次の記事をご覧ください。


回帰分析を行うコードと、回帰直線を描く(決定係数の表示含む)コードを「散布図作成コード」に追加します。
この状態のコードは以下。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
df = pd.read_excel('data/DL4.xls', sheet_name=0)
# 欠損値が一つでも含まれる行を削除
df = df.dropna(how='any')
x = df['週別気温']
y = df['週別指数']
# 目盛の値
x_scale = 5
y_scale = 2.5
xscale = np.arange(0, (max(x)+1)*x_scale, x_scale)
yscale = np.arange(0, (max(y)+1)*y_scale, y_scale)
fig = plt.figure(dpi=100, figsize=(4.6,3.8))
fig.suptitle('品目:スポーツ飲料等', fontsize=10, x=0.27, y=0.87)
ax = fig.add_subplot(111)
ax.yaxis.set_label_coords(-0.07,0.4)
# 散布図を描画
plt.scatter(x, y, c='#00FFFF', edgecolors="#37BAF2")
plt.title("東京都", fontsize=17, fontweight="bold")
plt.xticks(xscale, fontsize=8)
plt.yticks(yscale, fontsize=8)
plt.xlabel("平均気温(℃)", fontsize=10)
plt.ylabel("販\n売\n指\n数", fontsize=10, rotation=0)
plt.xlim(0, 35)
plt.ylim(0.0, 2.5)
# 回帰分析 線形
mod = LinearRegression()
df_x = pd.DataFrame(x)
df_y = pd.DataFrame(y)
# 線形回帰モデル、予測値、R^2を評価
mod_lin = mod.fit(df_x, df_y)
y_lin_fit = mod_lin.predict(df_x)
r2_lin = mod.score(df_x, df_y)
ax.text(19.0, 0.6, '$ R^{2} $=' + str(round(r2_lin, 4)))
plt.plot(df_x, y_lin_fit, color = '#000000', linewidth=0.5)
plt.gca().spines['right'].set_visible(False)
plt.subplots_adjust(left=0.1, right=0.98, bottom=0.13, top=0.89)
plt.savefig("result1.png", facecolor="white")
そして、このコードを実行した結果は以下。
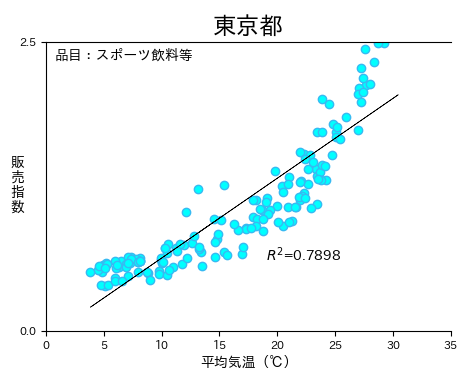
冒頭の画像と同じモノになりました。
今回の記事で追加したコードは、10行未満です。
たった、それだけで回帰分析が実行できます。
おまけに、回帰直線も引くことが可能。
このようなデータ解析やグラフ表示を行うとなると、Pythonは圧倒的な破壊力です。
これを他の言語でやろうとすると、かなり大変です。

