「日本語対応のLLMを家庭用のPCで動かしたい」
「つよつよGPUでなくてもLLMを動かしてみたい」
このような場合には、rinna/youri-7b-chat-gptqがオススメです。
この記事では、日本語対応のLLMであるrinna/youri-7b-chat-gptqについて解説しています。
本記事の内容
- rinna/youri-7b-chat-gptqとは?
- rinna/youri-7b-chat-gptqの利用方法
- rinna/youri-7b-chat-gptqの動作確認
それでは、上記に沿って解説していきます。
rinna/youri-7b-chat-gptqとは?
rinna/youri-7b-chat-gptqは、LLM(Large Language Model)の一つです。
rinna/youri-7b-chat-gptqの先祖は、llama2-7bになります。
進化の過程は、以下の表をご覧ください。
| モデル名 | 基本モデル | 説明 |
|---|---|---|
| llama2-7b | – | 基本モデル。大規模なデータセットで事前学習されたもの。 |
| rinna/youri-7b | llama2-7b | llama2-7bを基に日本語と英語のデータセットで継続的な事前学習を行ったモデル。 |
| rinna/youri-7b-chat | rinna/youri-7b | rinna/youri-7bのチャットスタイルのタスクに特化して調整されたモデル。 |
| rinna/youri-7b-chat-gptq | rinna/youri-7b-chat | rinna/youri-7b-chatの量子化バージョン。 |
ざっくり言うと、llama2-7bに以下の要素を加えたモノがrinna/youri-7b-chat-gptqということです。
- 日本語特化
- 小型化(量子化)
- チャット用
rinna/youri-7b-chat自体が、10GBのGPUメモリで動くと言われています。
それを量子化したrinna/youri-7b-chat-gptqは、もっと小さいGPUメモリでも動く可能性があります。
以上、rinna/youri-7b-chat-gptqについて説明しました。
次は、rinna/youri-7b-chat-gptqの利用方法を説明します。
rinna/youri-7b-chat-gptqの利用方法
Windowsは、以下のコマンドを実行するだけでOK。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
現時点において、AutoGPTQのサポート状況は以下となります。
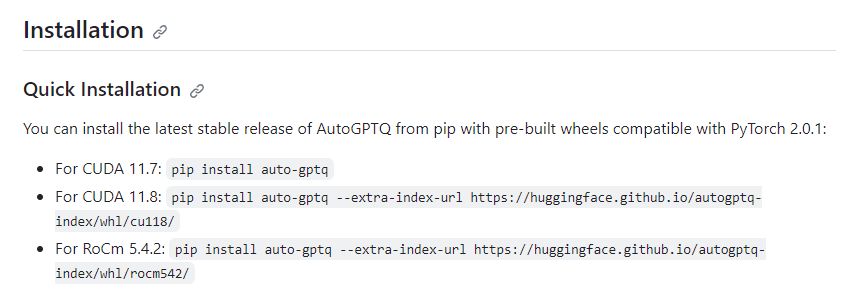
そのため、PyTorchも「cu118」をインストールしています。
PyTorchだけ「cu121」をインストールしても良いかどうかは不明です。
とりあえず、今回は「cu118」で統一しています。
「cu118」で統一している場合、rinna/youri-7b-chat-gptqをGPUで利用できています。
以上、rinna/youri-7b-chat-gptqの利用方法を説明しました。
次は、rinna/youri-7b-chat-gptqの動作確認を説明します。
rinna/youri-7b-chat-gptqの動作確認
公式ページにサンプルコードが掲載されています。
それをもとに質疑応答の動作を検証してみましょう。
import torch
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/youri-7b-chat-gptq")
model = AutoGPTQForCausalLM.from_quantized("rinna/youri-7b-chat-gptq", use_safetensors=True)
instruction = "次の質問に答えてください。"
input = "西暦2023年は和暦何年ですか?"
context = [
{"speaker": "設定", "text": instruction},
{"speaker": "ユーザー", "text": input}
]
prompt = "\n".join([f"{uttr['speaker']}: {uttr['text']}" for uttr in context])
prompt += "\nシステム: "
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
input_ids=token_ids.to(model.device),
max_new_tokens=200,
do_sample=True,
temperature=0.5,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
output = output[len(prompt):-len("</s>")].strip()
print(output)
上記コードを実行すると、以下のように返ってきます。
令和5年
この回答は正確です。
私の環境(GeForce RTX 3090 24GB)では、10秒で返答があります。
これは、かなり良い反応と言えるのではないでしょうか。
正直、今までのLLMは家庭用PCでは重過ぎでした。
日本語に強くて、この処理速度なら可能性は広がりますね。
やっと、ちゃんと試してみようと思えるLLMが出てきた感じです。
やはり、日本語ができないと面白くありませんからね。
以上、rinna/youri-7b-chat-gptqの動作確認を説明しました。