「テキストから動画を生成したい」
「Text-to-video-synthesisのインストールに失敗する・・・」
このような場合には、この記事の内容が参考になります。
この記事では、Text-to-video-synthesisのWebアプリについて解説しています。
本記事の内容
- Text-to-video-synthesisのWebアプリとは?
- Text-to-video-synthesisのWebアプリのシステム要件
- Text-to-video-synthesisのWebアプリのインストール
- Text-to-video-synthesisのWebアプリの動作確認
それでは、上記に沿って解説していきます。
Text-to-video-synthesisのWebアプリとは?
Text-to-video-synthesisを用いると、テキストから動画を生成できます。
Text-to-video-synthesisについては、次の記事で説明しています。

上記の記事では、公式のインストール方法を解説しています。
しかし、その方法は正直言って面倒です。
それに、GUI画面も存在せず、使い勝手も良くありません。
でも、今はすぐに便利なモノが出てきます。
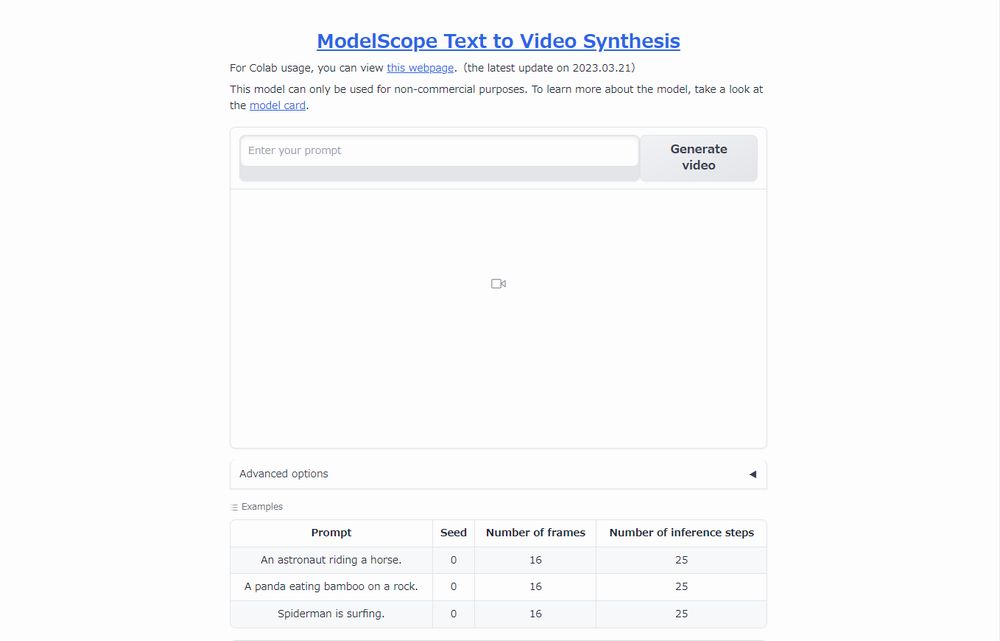
ModelScope Text to Video Synthesis
https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
これは、Text-to-video-synthesisのWebアプリです。
このアプリであれば、GUI画面が存在してます。
そして、インストールも非常に簡単です。
面倒なことをする必要なく、Text-to-video-synthesisを動かすことができます。
以上、Text-to-video-synthesisのWebアプリについて説明しました。
次ぎは、Text-to-video-synthesisのWebアプリのシステム要件を説明します。
Text-to-video-synthesisのWebアプリのシステム要件
基本的には、GPU版のPyTorchが動けばOKです。
バージョンに関しては、1系でも2系でもどちらでも構いません。
ここでは、PyTorch 2.0を推奨しておきます。
GPU版PyTorch 2.0のインストールは、次の記事で説明しています。

また、PyTorch 2.0はPython 3.8以降がサポート対象です。
とにかく、詳細は上記の記事をご覧ください。
以上、Text-to-video-synthesisのWebアプリのシステム要件を説明しました。
次は、Text-to-video-synthesisのWebアプリのインストールを説明します。
Text-to-video-synthesisのWebアプリのインストール
Text-to-video-synthesisのWebアプリのインストールは、次の手順で実施します。
- ファイル一式の取得(Hugging Faceから)
- requirements.txtを使った一括インストール
それぞれを下記で説明します。
ファイル一式の取得(Hugging Faceから)

上記ページでファイルを確認できます。
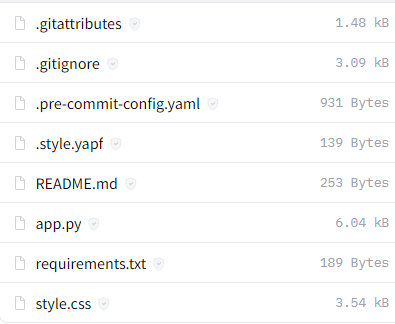
この中で必要なモノは、次の3ファイルです。
- app.py
- requirements.txt
- style.css
これだけであれば、一ファイル毎にダウンロードしましょう。
ダウンロードできたら、同じディレクトリ(コンテンツルート)に保存します。
requirements.txtを使った一括インストール
先ほどダウンロードしたrequirements.txtを見てください。
requirements.txt
accelerate==0.17.1 git+https://github.com/huggingface/diffusers@9dc8444 gradio==3.23.0 huggingface-hub==0.13.3 imageio[ffmpeg]==2.26.1 torch==2.0.0 torchvision==0.15.1 transformers==4.27.2
PyTorchはインストール済みのため、関連パッケージをコメントにしておきます。
#torch==2.0.0 #torchvision==0.15.1
変更後のrequirements.txtを利用して、必要なモノを一気にインストールします。
実行するのは、次のコマンドです。
pip install -r requirements.txt
処理が完了したら、インストールは終了です。
以上、Text-to-video-synthesisのWebアプリのインストールを説明しました。
次は、Text-to-video-synthesisのWebアプリの動作確認を説明します。
Text-to-video-synthesisのWebアプリの動作確認
Text-to-video-synthesisのWebアプリの動作確認を行います。
コンテンツルートに配置したapp.pyを実行すれば、起動できます。
初回起動時は、モデル(約3.5GB)のダウンロードが行われます。
2分ほど待たされました。
でも、これは全然軽いし速いです。
公式のインストール方法の場合だと、15GBほどのサイズ容量となります。
さらに、ファイル保存元のModelScopeからのダウンロードは非常に遅いです。
1時間以上は待たされる可能性があります。
今回の方法だと、Hugging Faceからのダウンロードになります。
そのため、ダウンロードでストレスを感じることはないでしょう。
上手く起動できたら、コンソールには次のように表示されます。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
Chromeなどのブラウザで「http://127.0.0.1:7860」にアクセスします。
Hugging Face上のデモと同じ画面を確認できます。
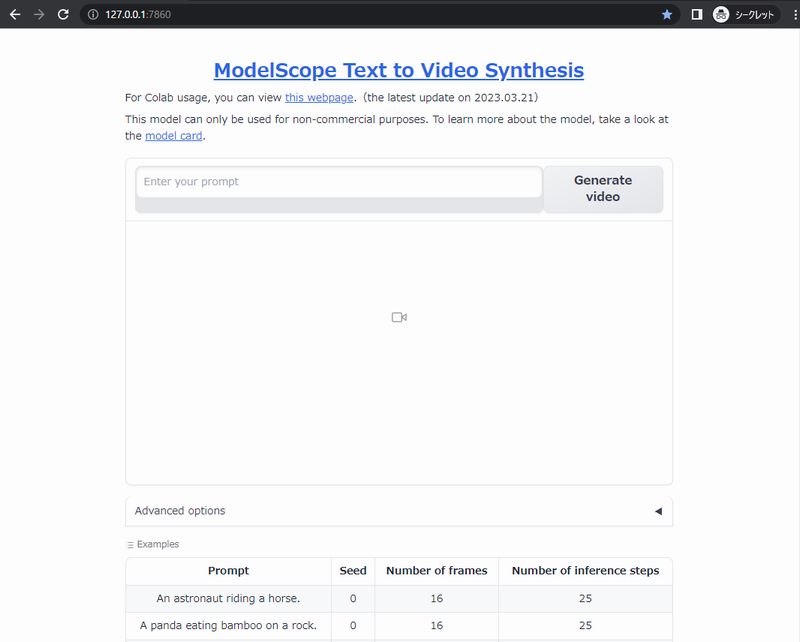
あとは、プロンプトを入力して「Generate video」ボタンを押すだけです。
「Advanced options」でSeedやStepsなどを設定できます。
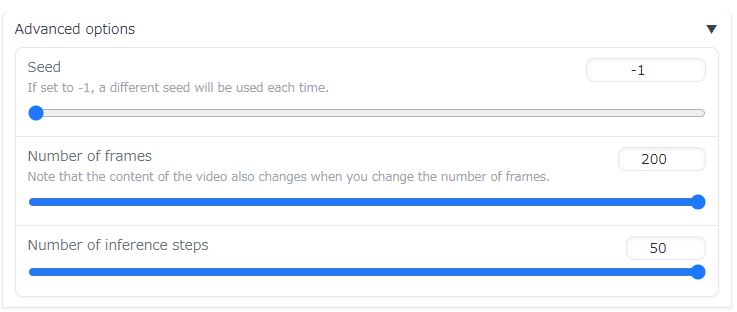
ちなみに上記の設定の場合、2分30秒ほどの時間がかかりました。

再生時間は、25秒ほどです。

追記 2023年3月25日
メモリ不足でエラーが出る場合は、次の記事をご覧ください。
以上、Text-to-video-synthesisのWebアプリの動作確認を説明しました。