
「VQGAN+CLIPをWindowsで試したい」
「AIアートをWindowsで動かしたい」
このような方にとって、参考となる記事です。
本記事の内容
- VQGAN+CLIPとは?
- WindowsでVQGAN+CLIPを動かす方法
- VQGAN+CLIPの動作に必要なモノ
- VQGAN+CLIPのインストール
- VQGAN+CLIPの動作確認
それでは、上記に沿って解説していきます。
VQGAN+CLIPとは?
VQGAN+CLIPは、入力したテキストから画像を生成することを可能にします。
VQGANは、VQ-VAEという画像生成モデルを敵対的生成ネットワーク(GAN)に発展させたモノです。
VQGANやGANの詳細は、専門的な記事や論文を参考にしてください。
CLIPは、画像とテキストの関連性をランク付けするニューラルネットワークです。
次の記事では、CLIPを 汎用画像分類モデルと表現しています。

VQGANとCLIPを組み合わせることにより、テキストによる画像生成を実現しています。
そして、そのコードがGoogle Colaboratoryで公開されています。
Google Colaboratory上のVQGAN+CLIP
https://colab.research.google.com/drive/1ZAus_gn2RhTZWzOWUpPERNC0Q8OhZRTZ
よって、Google Colaboratory上であれば、VQGAN+CLIPを試すことが可能です。
実際、Google Colaboratoryを利用した記事が検索でヒットします。
それとは逆に、VQGAN+CLIPをローカル環境で動かすための情報はほとんどありません。
そのこともあり、VQGAN+CLIPを触らずに時間が経過していました。
しかし、VQGAN+CLIPをローカル環境で動かす仕組みが公開されていることを発見!!
WindowsでVQGAN+CLIPを動かす方法
VQGAN-CLIP(GitHub)
https://github.com/nerdyrodent/VQGAN-CLIP
ローカル環境でVQGAN+CLIPを動かす方法が、上記ページに記載されています。
ただし、Ubuntu 20.04で検証したということです。
基本的には、同じ手順でWindowsでも動きます。
ただ、若干Windows用に変更も必要となります。
そのために、必要なモノから説明します。
VQGAN+CLIPの動作に必要なモノ
特に重要なモノが、以下となります。
- gitコマンド(Git for Windows)
- Python 3.9
- Pythonの仮想環境
- PyTorch(GPU対応版)
それぞれを下記で説明します。
gitコマンド(Git for Windows)
gitコマンドが、必ずいるという訳ではありません。
zipをダウンロードして、解凍すれば済む話です。
でも、gitコマンドを合計で3回も利用します。
それなら、これを機会にWindowsでgitコマンドを使えるようにしましょう。

上の記事通りにすれば、簡単にgitコマンドが利用できるようになります。
なお、インストール手順はgitコマンドが動く前提で説明します。
Python 3.9
VQGAN-CLIP(GitHub)ページでは、Python 3.9で検証されているようです。
後述するPyTorchも最新版(1.9.0)を利用しています。
それに従って、Pythonも最新にしておきましょう。
現時点(2021年8月末)なら、Python 3.9.6が最新となります。

Pythonの仮想環境
VQGAN+CLIPは、多くのパッケージに依存しています。
そのため、既存の環境にインストールというわけにはいきません。
VQGAN+CLIPは、Pythonの仮想環境にインストールしましょう。
Windowsなら、IDEにPyCharmを使えば簡単に仮想環境を利用できます。
プロジェクト毎に仮想環境となります。
また、以下のようにコマンドでも簡単に仮想環境を利用できます。

Windowsなら、PyCharmの利用をおススメします。
非常に便利なIDEです。
PyTorch(GPU対応版)
VQGAN+CLIPにおける機械学習の処理は、PyTorchで実行されています。
よって、PyTorchをインストールする必要があります。
GPU対応版と記載していますが、必須ではありません。
CPU版でも動くことは、動くでしょう。
でも、かなり遅いと思います。
CPUでVQGAN+CLIPを動かすことは、おススメしません。
PyTorchのインストールは、次の記事で解説しています。

必要なモノが揃ったら、VQGAN+CLIPをインストールしていきます。
VQGAN+CLIPのインストール
最初に、コマンドプロンプトかPowerShellのどちらかを起動します。
PyTorchはインストール済みとします。
この状態で、まずは以下のパッケージをインストールしていきます。
pip install ftfy regex tqdm omegaconf pytorch-lightning IPython kornia imageio imageio-ffmpeg einops torch_optimizer
インストールが完了したら、以下コマンドを立て続けに実行。
gitコマンドが、大活躍します。
git clone https://github.com/nerdyrodent/VQGAN-CLIP cd VQGAN-CLIP git clone https://github.com/openai/CLIP git clone https://github.com/CompVis/taming-transformers
そして、VQGAN-CLIPディレクトリの下にcheckpointsディレクトリを作成します。
そのcheckpointsに移動して、VQGANで学習済みモデルとそれに関するYAMLファイルをダウンロード。
mkdir checkpoints cd checkpoints wget "https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1" -O vqgan_imagenet_f16_16384.yaml wget "https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fckpts%2Flast.ckpt&dl=1" -O vqgan_imagenet_f16_16384.ckpt
ただし、モデルに関しては、wgetでダウンロードが終わらない可能性があります。
その場合は、ブラウザでファイルURLにアクセスしてダウンロードしましょう。
多分、そっちの方が圧倒的に速いです。
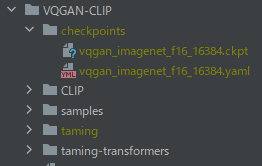
結果的に、上の画像のような構成になればOKです。
yaml・ckptファイルの名称には、注意してください。
あと、学習済みモデルは他にも用意されています。
VQGAN-CLIPディレクトリ直下にあるdownload_models.shにファイルURLが記載されています。
必要な場合は、各自でダウンロードしましょう。
以上、VQGAN+CLIPのインストールが完了しました。
最後は、VQGAN+CLIPの動作確認を行いましょう。
VQGAN+CLIPの動作確認
VQGAN-CLIPディレクトリに移動しておきます。
VQGAN-CLIPは、以下の状況です。
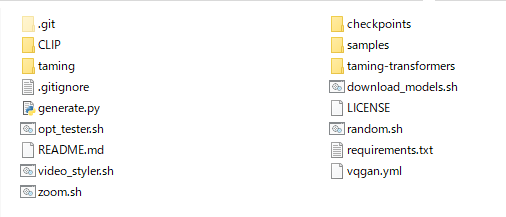
コマンドプロンプトかPowerShellなどで、次のコマンドを実行します。
python generate.py -p "A painting of an apple in a fruit bowl"
「フルーツのボウルに入った一つのリンゴ」の絵を描くように指示しています。
実行すると、以下のように処理が行われていきます。
>python generate.py -p "A painting of an apple in a fruit bowl" Working with z of shape (1, 256, 16, 16) = 65536 dimensions. loaded pretrained LPIPS loss from taming/modules/autoencoder/lpips\vgg.pth VQLPIPSWithDiscriminator running with hinge loss. Restored from checkpoints/vqgan_imagenet_f16_16384.ckpt Using device: cuda:0 Optimising using: Adam Using text prompts: ['A painting of an apple in a fruit bowl'] Using seed: 168539432353200 i: 0, loss: 0.926831, losses: 0.926831 i: 50, loss: 0.742013, losses: 0.742013 i: 100, loss: 0.699988, losses: 0.699988 i: 150, loss: 0.702984, losses: 0.702984 i: 200, loss: 0.63899, losses: 0.63899 i: 250, loss: 0.641753, losses: 0.641753 i: 300, loss: 0.674027, losses: 0.674027 i: 350, loss: 0.640589, losses: 0.640589 i: 400, loss: 0.62411, losses: 0.62411 i: 450, loss: 0.66097, losses: 0.66097 i: 500, loss: 0.612466, losses: 0.612466 500it [02:35, 3.21it/s]
最終的に処理が終了すると、VQGAN-CLIP上にoutput.pngが作成されています。

リンゴがボウルに入っているようには、見えます。
オーダー通りと言えばオーダー通りですけどね。。。
精度云々は、ステップ数を増やしたりすれば改善できるようです。
もちろん、利用する学習済みモデル次第のところもあるでしょう。

