OpenAI CLIPは、OpenAIが開発した汎用画像分類モデルです。
CLIPには、GPT-2やGPT-3で用いられている技術が応用されています。
そのことにより、未知の画像でも適切に分類・評価することが可能になります。
CLIPは、単なるパターンマッチングではないということです。
本記事の内容
- OpenAI CLIPとは?
- OpenAI CLIPのシステム要件
- OpenAI CLIPのインストール
- OpenAI CLIPの動作確認
それでは、上記に沿って解説していきます。
OpenAI CLIPとは?
公式ページ
https://openai.com/blog/clip/
CLIPは、汎用画像分類モデルです。
(※正確には、モデルを簡単に呼び出せるライブラリになります)
そのモデルの作成するために、画像と画像を説明するテキストのペア4億組を学習させています。
CLIPを使うと、ゼロショット画像分類が可能になります。
つまり、全く学習を行わずに画像分類ができるのです。
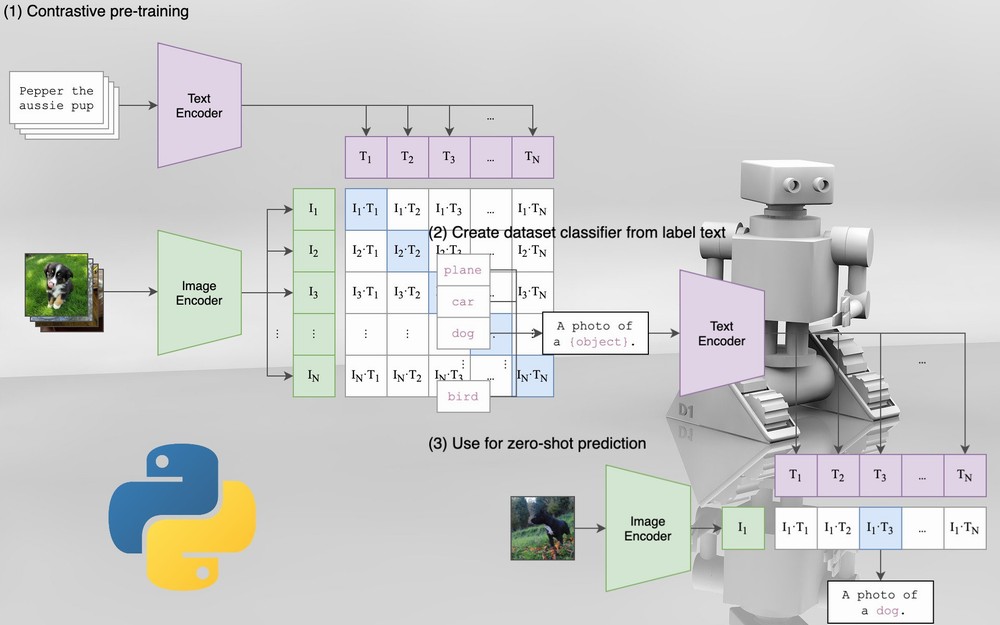
次の画像は、CLIPの仕組みを表しています。
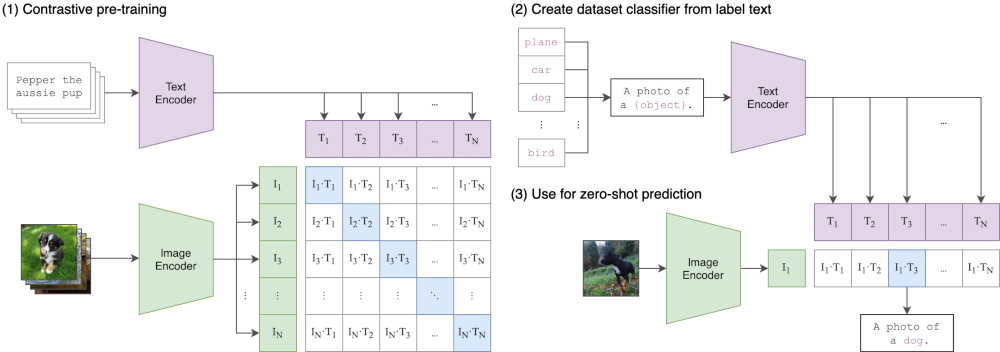
通常の画像分類モデルは、大量のラベル付き画像を用意します。
そして、長時間にわたって学習を行います。
それに対して、CLIPでは画像とテキストの特徴を利用します。
このことにより、CLIPが自然言語処理的な画像処理と言われるのでしょう。
かなりざっくりまとめると、以下のようなイメージになります。
| 通常の画像分類モデル | 具体的 | パターンマッチング |
| CLIP | 抽象的 | 予測 |
通常の画像分類モデルは、量で勝負するイメージです。
対して、CLIPは質で勝負するイメージとなります。
詳細は、CLIP公式ページの説明などをご覧ください。
ここでは、イメージできることを優先にしています。
とにかく、CLIPは汎用画像分類モデルだということです。
そして、汎用的であるからこそ、未知の画像にも対応できます。
抽象化していることの強みと言えるでしょう。
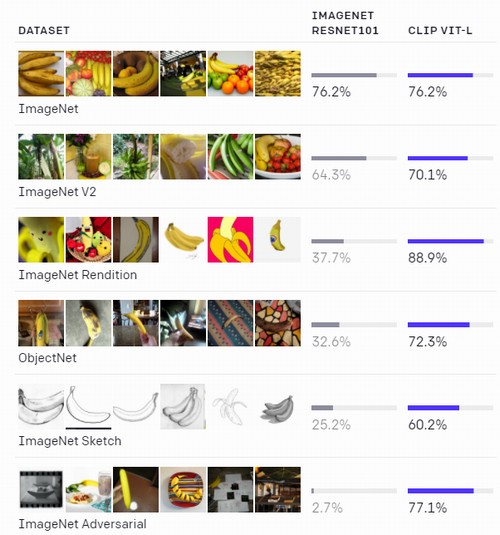
上の画像は、CLIPの汎用性を示したモノです。
ImageNetの画像で学習したIMAGENET RESNET101とCLIPを比較した結果です。
RESNET101は、ImageNet以外の画像は上手く評価できません。
しかし、CLIPはどんなタイプの画像セットでも適切に評価しています。
CLIPの本領発揮というところでしょう。
以上、OpenAI CLIPに関する説明でした。
次は、OpenAI CLIPのシステム要件を確認しましょう。
OpenAI CLIPのシステム要件
現時点(2021年8月)でのOpenAI CLIPの最新バージョンは、1.0となります。
このバージョンは、2021年1月5日にリリースされています。
それ以降は、目立った動きがありません。
サポートOSに関しては、明確に記載はありません。
少なくとも、記載を見つけることができませんでした。
ただ、以下を含むクロスプラットフォーム対応のはずです。
- Windows
- macOS
- Linux
WindowsとUbuntuは、実際に動作確認が取れました。
Ubuntu(Linux)で動いて、macOSで動かない理由もありません。
また、Pythonのバージョンに関しても情報がありません。
ただ、リリースされたのが今年です。
それであれば、Python 3.6以降と考えた方がよいでしょう。
あとは、PyTorhですね。
公式(GitHub上のページ)では、PyTorch 1.7.1が指定されています。
しかし、PyTorch 1.7.1である必要はありません。
現時点(2021年8月時点)で最新版となるPyTorch 1.9.0でも問題なく動きます。
PyTorchのインストールについては、次の記事で説明しています。

以上、OpenAI CLIPのシステム要件を説明しました。
次は、OpenAI CLIPをインストールしていきます。
OpenAI CLIPのインストール
OpenAI CLIPのGitHubページ
https://github.com/openai/CLIP
上記ページでは、以下の手順が記載されています。
$ conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0 $ pip install ftfy regex tqdm $ pip install git+https://github.com/openai/CLIP.git
Anaconda(conndaコマンド)前提です。
でも、Anacondaもconndaコマンドも使う必要はありません。
pipコマンドだけで、OpenAI CLIPをインストールできます。
インストールを実行する前に、現状のインストール済みパッケージを確認しておきます。
>pip list Package Version ----------------- ------------ pip 21.2.4 setuptools 57.4.0
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、OpenAI CLIPのインストールを行いましょう。
実際に私が利用したコマンドは、以下。
(※PyTorchはGPU版をインストールしています)
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html pip install ftfy regex tqdm pip install git+https://github.com/openai/CLIP.git
なお、gitコマンドを利用できない場合はインストールしましょう。
gitコマンドは何かと便利です。
WindowsへのGitのインストールは、次の記事で説明しています。

インストールが完了したら、パッケージを確認しておきましょう。
>pip list Package Version ----------------- ------------ clip 1.0 colorama 0.4.4 ftfy 6.0.3 numpy 1.21.2 Pillow 8.3.1 pip 21.2.4 regex 2021.8.21 setuptools 57.4.0 torch 1.9.0+cu111 torchaudio 0.9.0 torchvision 0.10.0+cu111 tqdm 4.62.1 typing-extensions 3.10.0.0 wcwidth 0.2.5
以上、OpenAI CLIPのインストールについて説明しました。
最後は、OpenAI CLIPの動作確認を行います。
OpenAI CLIPの動作確認
OpenAI CLIPの動作確認は、次のコードで行います。
import torch
import clip
from PIL import Image
# 画像
IMG_PATH = "dog.jpg"
# テキスト
TEXT_LIST = ["wolf", "dog", "cat"]
# 利用デバイスの設定
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデルの読み込み
model, preprocess = clip.load("ViT-B/32", device=device)
# 画像の読み込み、テキストの用意
image = preprocess(Image.open(IMG_PATH)).unsqueeze(0).to(device)
text = clip.tokenize(TEXT_LIST).to(device)
with torch.no_grad():
# 画像、テキストのエンコード
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# 推論
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
# 類似率の出力(テキスト毎に類似率を表示)
for i in range(len(TEXT_LIST)):
rate = probs[0][i]
print(TEXT_LIST[i] + "---" + str(rate))
プログラムで行う処理を確認します。
事前に、次の画像(dog.jpg)を用意しています。

そして、この画像とテキストとの類似率(一致率)を取得して終わります。
テキストは、リスト形式で設定します。
# テキスト TEXT_LIST = ["wolf", "dog", "cat"]
コードを実行した結果は、以下。
wolf---0.001431 dog---0.998 cat---0.0005693
「dog」である確率はかなり高いようです。
そして、「cat」よりは「wolf」の方が類似率は高くなっています。
以上、OpenAI CLIPの動作確認を説明しました。

