
「精度の高いAIアートをPythonで試したい」
「GoogleのColaboratoryではなく、ローカル環境でStable Diffusionを動かしたい」
このような場合には、この記事の内容が参考になります。
この記事では、ローカル環境で簡単にStable Diffusionを実行する方法を解説しています。
本記事の内容
- Stable Diffusionとは?
- Stable DiffusionをDiffusersで利用する方法
- 学習済みモデルのダウンロード
- 【動作確認】テキストからの画像生成
それでは、上記に沿って解説していきます。
Stable Diffusionとは?
Stable Diffusionとは、オープンソース化された高性能画像生成AIです。
Stable Diffusionを用いると、テキストから画像を出力することが可能となっています。
例えば、「Cyberpunk old man」というテキストからは次のような画像が作成されます。

ヤバくないですか?
このサイトでも、過去にAIアートなるモノを扱ってきました。



その中でも、Stable Diffusionは頭が一つも二つも抜けています。
それに加えて、商用利用もOKのようです。
生成した画像の権利は、作成者自身が持ちます。
不適切な画像は、作成できないようにも対策されています。
不適切な画像を作成するような場合、次のような警告が表示されます。
NSFWとは、「職場閲覧注意」の意味です。
Potential NSFW content was detected in one or more images. A black image will be returned instead. Try again with a different prompt and/or seed.
このNSFWフィルタは、無効化することができます。
その方法については、次の記事で説明しています。

また、Stable DiffusionをAIと表現していますが、その正体は基本的にはモデルです。
次のページでその詳細が解説されています。
CompVis/stable-diffusion · Hugging Face
https://huggingface.co/CompVis/stable-diffusion
ソースコードまで公開しているので、学習させてモデルを自作・強化することも可能でしょう。
Windowsなどのローカル環境で利用を行う場合、NVIDIAのGPUが推奨されています。
以上、Stable Diffusionについて説明しました。
次は、Stable DiffusionをDiffusersで利用する方法を説明します。
Stable DiffusionをDiffusersで利用する方法
Stable Diffusionを利用する方法は、大きく以下の二つがあります。
- 公式ツールを用いた方法
- Diffusersを用いた方法
公式ツールとは、次のページで公開されているツールのことです。
GitHub – CompVis/stable-diffusion
https://github.com/CompVis/stable-diffusion
公式ツールの導入は、決して簡単とは言えません。
むしろ、困難な部類に入ります。
それに対して、Diffusersを用いた方法は簡単です。
基本的には、pipコマンドだけでインストールできます。
この記事では、その簡単な方を解説します。
システム要件としては、Diffusersがポイントになります。
Diffusersのインストールは、次の記事で丁寧に解説しています。

Diffusersが動くようになれば、半分は終わったようなものです。
とにかく、Diffusersが動くようにしましょう。
あとは、Stable Diffusion本体である学習済みモデルを手に入れるだけです。
ただし、それが少し単純ではありません。
次では、学習済みモデルのダウンロードを説明します。
学習済みモデルのダウンロード
学習済みモデルのダウンロードには、次の作業が必要となります。
- モデルの利用規約に同意
- Access Token(アクセストークン)の取得
それぞれを以下で説明します。
モデルの利用規約に同意
CompVis/stable-diffusion-v1-4 · Hugging Face(モデルのページ)
https://huggingface.co/CompVis/stable-diffusion-v1-4
Stable Diffusionのモデルは、上記ページで公開されています。
ただし、単純にそのモデルをダウンロードすることはできません。
ダウンロードするためには、利用規約に同意しないといけません。
利用規約に同意するためには、Hugging Faceサイトのアカウントが必要になります。
アカウントがない場合は、次のページから作成します。
Hugging Face – The AI community building the future.
https://huggingface.co/join
アカウントが作成できたら、サイトにログイン。
ログインできたら、まずはモデルのページにアクセスします。
次のような利用規約を確認できます。

その利用規約の最後に、次のチェックボックスがあります。
そこにチェックを入れて、「Access repository」をクリック。
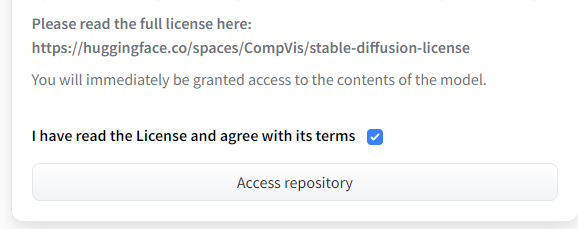
クリックしたら、利用規約に同意したことになります。
Access Token(アクセストークン)の取得
次は、モデルのダウンロードを行います。
しかし、モデルのダウンロードは直接ファイルをダウンロードする必要はありません。
Diffusersを利用しているため、Diffusersにモデルをダウンロード・設置させましょう。
つまり、プログラム上からダウンロードするということです。
そのことを実現するために、Access Token(アクセストークン)を利用します。
Hugging Faceのサイトにログインした状態で、次のページにアクセスします。
Access Token管理画面
https://huggingface.co/settings/tokens
この画面でAccess Tokenの管理を行います。

「New token」ボタンをクリック。
Access Tokenの情報を入力する画面が、ポッポアップで表示されます。
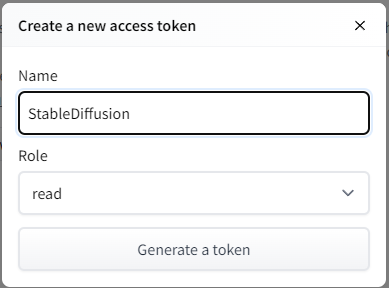
「Name」を入力して、「Generate a token」ボタンをクリックします。
「Role」は、「read」のままでOK。
ポップアップが閉じたら、作成したAccess Tokenが確認できます。
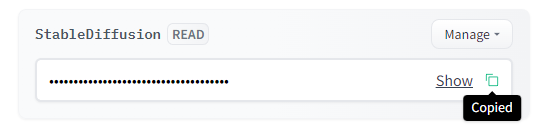
コピーのアイコンをクリックして、アクセストークンを取得します。
まとめ
利用規約に同意して、アクセストークンまで取得できました。
これで、Diffusersを用いてモデルをダウンロードする準備ができたと言えます。
ダウンロード自体は、コードを実行した際に自動で実施されます。
次は、実際に動作確認のためにコードを動かしてみましょう。
【動作確認】テキストからの画像生成
Stable Diffusionと言えば、テキストからの画像生成です。
そのための動作確認用コードが、以下。
import torch
from diffusers import StableDiffusionPipeline
from torch import autocast
MODEL_ID = "CompVis/stable-diffusion-v1-4"
DEVICE = "cuda"
YOUR_TOKEN = "コピーしたアクセストークン"
pipe = StableDiffusionPipeline.from_pretrained(MODEL_ID, revision="fp16", torch_dtype=torch.float16, use_auth_token=YOUR_TOKEN)
pipe.to(DEVICE)
prompt = "a dog painted by Katsuhika Hokusai"
with autocast(DEVICE):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("test.png")
上記コードを実行すると、初回時はモデルのダウンロードが実行されます。
モデルは容量的に数GBあるので、結構な時間を待たされます。
(※2回目以降は、ダウンロードが省略されます)
モデルのダウンロードが終わったら、次のように表示される場合があります。
ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy.
これは、Tokenizer(トークナイザ)についての警告です。
気になる場合は、ftfyかspacyをインストールすればよいでしょう。
個人的には、英語では日本語ほどTokenizerについて重要性を感じません。
今回のようなケースでは、英語だけの利用ですからね。
この辺は、各自のお好きなようにしてください。
処理の実行に話を戻しましょう。
警告の後に、次のような表示が行われます。
18it [00:04, 4.77it/s]
0bitから始まり、51bitまで表示され続けます。
51it [00:11, 4.53it/s]
51bitになったら、処理が完了して画像が生成されています。
同じディレクトリ上に、test.pngという名前のファイルを確認できるはずです。
test.png

実行する度に、生成される画像は異なります。
画像を固定したい場合は、次の記事をご覧ください。

次に作成された画像は、以下。

なかなか渋いですね。
これらが自動で作成されてしまうことに、衝撃を感じます。
なお、作成される画像を変更する場合は以下のテキストを変更します。
prompt = "a dog painted by Katsuhika Hokusai"
Stable Diffusionでは、このテキストのことを呪文と呼ぶことがあります。
呪文の効果的な唱え方については、次の記事で解説しています。

以上、【動作確認】テキストからの画像生成を説明しました。

