
「プロンプトのトークン数は、どうやって数えるの?」
「Stable Diffusionにおけるトークンについて理解したい」
このような場合には、この記事の内容が参考になります。
この記事では、プロンプトのトークン数を確認する方法について解説しています。
本記事の内容
- プロンプトのトークンとは?
- Stable Diffusion v1-5までのトークン数確認方法
- Stable Diffusion v2以降のトークン数確認方法
- 言語モデルの違い
それでは、上記に沿って解説していきます。
プロンプトのトークンとは?
プロンプトは、もうみなさんお馴染みですね。
呪文と言ったりすることもあります。
Stable Diffusionのデフォルトとも言えるのが、次のプロンプトです。
a photo of an astronaut riding a horse on mars
このプロンプトでは、次のような画像を生成できます。

実際にこのプロンプトを利用しているコードは、次の記事に載せています。

では、このプロンプトは一体何個のトークンからできているのでしょうか?
答えは、10個のトークンとなります。
'a</w>', 'photo</w>', 'of</w>', 'an</w>', 'astronaut</w>', 'riding</w>', 'a</w>', 'horse</w>', 'on</w>', 'mars</w>'
10個であれば、Stable Diffusionにおいてはすべて対象となります。
しかし、トークン数が76個以上となればすべてが対象とはなりません。
最初の75個までが、画像生成における対象プロンプトとなります。
つまり、プロンプトは最大75個のトークンで記述する必要があるということです。
もちろん、これには例外があります。
76個以上のトークンでも、すべてを画像生成時のプロンプトとして対象にすることは可能です。
長いプロンプトを利用する方法については、次の記事で解説しています。

では、トークンとは一体何なのでしょうか?
簡単に言うと、プログラム(AI)が認識できる単位で区切った言葉と言えます。
その場合の判断には、言語モデルを利用しています。
この言語モデルの質によって、AIの文章に対する理解度が変わってきます。
以上、プロンプトのトークンについて説明しました。
次は、Stable Diffusion v1-5までのトークン数確認方法を説明します。
Stable Diffusion v1-5までのトークン数確認方法
Stable Diffusion v1-5までは、推論時に次の言語モデルを利用しています。
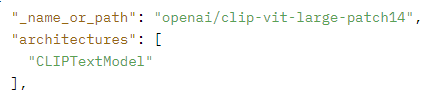
このモデルは、Hugging Face上で公開されています。
openai/clip-vit-large-patch14 · Hugging Face
https://huggingface.co/openai/clip-vit-large-patch14
上記モデルを利用して、トークンを認識しています。
したがって、トークンの状況を確認するには以下コードを用います。
import pprint from transformers import AutoTokenizer text_model_id = "openai/clip-vit-large-patch14" tokenizer = AutoTokenizer.from_pretrained(text_model_id) prompt = "a photo of an astronaut riding a horse on mars" tokens = tokenizer.tokenize(prompt) print(len(tokens)) pprint.pprint(tokens)
上記コードを実行すると、次のような結果が表示されます。
ただし、言語モデルが存在しない場合はモデルのダウンロードが始まります。
10 ['a</w>', 'photo</w>', 'of</w>', 'an</w>', 'astronaut</w>', 'riding</w>', 'a</w>', 'horse</w>', 'on</w>', 'mars</w>']
「10」は、トークン数を表示しています。
それ以外は、トークンすべての表示となります。
以上、Stable Diffusion v1-5までのトークン数確認方法を説明しました。
次は、Stable Diffusion v2以降のトークン数確認方法を説明します。
Stable Diffusion v2以降のトークン数確認方法
Stable Diffusion v2以降は、推論時に次の言語モデルを利用しています。

ただし、このモデルは一般的に公開はされていません。
なぜなら、Stable Diffusion専用で新たに開発された言語モデルだからです。
おそらく、ベースとなるのは次の言語モデルだと思われます。

学習時には、laionのOpenCLIP-ViT/Hを言語モデルに利用したと記載されています。
このモデルは、正式には次の名称となります。

この言語モデルは、公開されています。
そのため、次のようなコードでもトークンの状況は把握可能です。
import pprint from transformers import AutoTokenizer text_model_id = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K" tokenizer = AutoTokenizer.from_pretrained(text_model_id) prompt = "a photo of an astronaut riding a horse on mars" tokens = tokenizer.tokenize(prompt) print(len(tokens)) pprint.pprint(tokens)
ただし、これは本当に推論時に利用されている言語モデルではありません。
実際の言語モデルを指定するなら、次のような指定となります。
text_model_id = "safe-stable-diffusion-2-1/tokenizer"
上記のパスは、「stabilityai/stable-diffusion-2-1」のトークナイザを直接指定しています。
正確には、Stable Diffusion v2-1をSafetensors形式に変換したモデルとなります。
変換については、次の記事で解説しています。

コードの実行を結果を載せておきます。
どちらの言語モデルを指定しても、同じ結果です。
10 ['a</w>', 'photo</w>', 'of</w>', 'an</w>', 'astronaut</w>', 'riding</w>', 'a</w>', 'horse</w>', 'on</w>', 'mars</w>']
以上、Stable Diffusion v2以降のトークン数確認方法を説明しました。
次は、言語モデルの違いについて説明します。
言語モデルの違い
上記の結果を見る限り、言語モデルの違いで差異はありませんでした。
トークン数は「10」で全く同じです。
しかし、もっとも長いプロンプトの場合だと結果は変わってくる可能性はあります。
それぞれの言語モデルには、一応は性能的に差があります。
上のモデルほど、良いモデルとされています。

言語モデル(テキストエンコーダ)が異なることによる差異は、次の記事で説明しています。

画像を生成してみると、その違いは思ったよりも鮮明になります。
以上、言語モデルの違いを説明しました。

