
会社四季報、懐かしい響きです。
昔は、辞書みたいなモノでしか見れませんでした。
でも、今は会社四季報オンラインで見ることができます。
無料の情報だけでも、十分に使えます。
そんな懐かしい会社四季報をスクレイピングしていきます。
本記事の内容
- スクレイピングをやる前に意識すべきこと
- 会社四季報オンラインの利用規約を確認する
- 会社四季報オンラインをスクレイピングするための準備
- 企業ページのスクレイピング仕様
- 企業ページをスクレイピングして株価と会社情報を取得する
それでは、上記に沿って解説していきます。
スクレイピングをやる前に意識すべきこと
スクレイピングは、危険な技術になり得ます。
そのため、プログラムの初心者が適当に実行してはいけません。
やり方次第では、スクレイピングがDoS攻撃・DDos攻撃になってしまいます。
そうなってしまうと、最悪の場合は逮捕されてしまいます。
そうならないために、次の記事を是非とも読んでください。
「【必須】Webスクレイピングに関する考え方」の部分だけは必須です。

スクレイピングをやる上では、リスクを意識することが必須と言えます。
そのリスクを意識すれば、それを反映したコードになります。
以上、スクレイピングをやる前に意識すべきことを説明しました。
次は、会社四季報オンラインの利用規約を確認します。
会社四季報オンラインの利用規約を確認する
会社四季報オンライン利用規約
https://str.toyokeizai.net/-/info/kiyaku/sol/4ol_terms_20200401.pdf
会社四季報オンラインは、PDFで規約を公開しています。

会社四季報オンラインでは、規約でスクレイピングを禁止していますね。
このような金融系サイトは、大抵禁止するという内容を書いています。
でも、これは無視してOKです。
利用規約は、そもそもサービス運営側が勝手に定めたモノです。
同意もしていない利用規約に反しても、何もペナルティは受けません。
ただし、利用規約以前に法律は遵守しましょう。
上記で述べたように、スクレイピングはDoS攻撃・DDos攻撃になりかねません。
度を過ぎると、業務妨害になってしまいます。
なお、ログインした状態でのスクレイピングはやめるべきです。
業務妨害にならなくても、運営側の匙加減一つでペナルティを受ける可能性があります。
自由にペナルティを与える権利が、サービス運営側には存在しているからです。
利用規約に関しては、そのような認識で接すれば問題ありません。
とにかく、法律だけは絶対に守りましょう。
以上、会社四季報オンラインの利用規約を確認することについて説明しました。
次は、会社四季報オンラインをスクレイピングするための準備を行います。
会社四季報オンラインをスクレイピングするための準備
プログラム言語は、Pythonを用います。
そして、必要なライブラリ・ツールは以下。
- Selenium
- BeautifulSoup4
- lxml
下記でそれぞれ説明します。
Selenium
会社四季報オンラインは、スクレイピング対策をしています。
簡単に情報を取得されないように、対策をしているということです。
そのため、Seleniumが必須となります。
Seleniumのインストールに関しては、次の記事を参考にしてください。

上記の記事は、Windowsの場合についてです。
Linux(Ubuntu)の場合は、次の記事で解説しています。

BeautifulSoup4
BeautifulSoup4は、HTMLから情報を抽出するために利用しています。
BeautifulSoup4については、次の記事でまとめています。

lxml
HTMLを解析する際に利用するパーサーです。
BeautifulSoup4で利用することになります。
BeautifulSoup4には、標準のパーサーが用意されています。
しかし、lxmlはその標準パーサーよりも処理が高速です。
インストールは、以下のコマンドで行います。
pip install lxml
まとめ
会社四季報オンラインは、シンプルな静的コンテンツのサイトではありません。
企業ページは、JavaScriptによる動的コンテンツとなっています。
そのため、単純なスクレイピング(ページアクセス)が行えません。
そこで、Seleniumを利用します。
また、BeautifulSoup4により、コーディングを容易にできます。
さらに、lxmlにより、処理を高速化できるようになります。
以上、会社四季報オンラインをスクレイピングするための準備について説明しました。
次は、企業ページのスクレイピング仕様を確認します。
企業ページのスクレイピング仕様
スクレイピングする上で必要な処理は、次の2つです。
- スクレイピング対象ページのURL取得
- 対象ページのスクレイピング
下記でそれぞれを説明します。
スクレイピング対象ページのURL取得
対象ページのURLを取得するのは、重要な処理の一つです。
そして、今回は企業ページがスクレイピング対象となります。
例えば、雪国まいたけの企業ページは以下。
https://shikiho.jp/stocks/1375/
上場企業すべてを対象とするなら、その分だけURLを用意する必要があります。
そのためにスクレイピングを行うことは、普通にありえます。
スクレイピングのためのスクレイピングというヤツです。
「何度かスクレイピングを行って、目的のページにたどり着く」
このことは、スクレイピングにおいてはよくあることです。
例えば、netkeibaという競馬サイトのスクレイピングはそのケースに該当します。

何段階に分けて、スクレイピングを行っています。
このことが、スクレイピングを行う上での手間と言えるでしょう。
しかし、会社四季報オンラインの企業ページに関しては、その手間が不要となります。
なぜなら、企業ページのURLが推測できるからです。
https://shikiho.jp/stocks/●●●/
「●●●」は、証券コードです。
よって、証券コード一覧を用意すればOKということになります。
そして、その証券コード一覧はCSVで手に入ります。
その取得方法に関しては、次の記事で説明しています。

CSVで用意できれば、そのためのスクレイピングは必要ありません。
これで、大きなヤマは越えました。
対象ページのスクレイピング
すでに書いた通り、企業ページは動的コンテンツです。
そのため、若干の工夫が必要となります。
工夫しないと、空っぽのページをスクレイピングすることになります。
SEO的には、完全に価値のないページです。
では、どういう工夫をすればよいのかとなります。
その工夫とは、「article」をclassに持つ要素(以下article要素)の存在をチェックすることです。
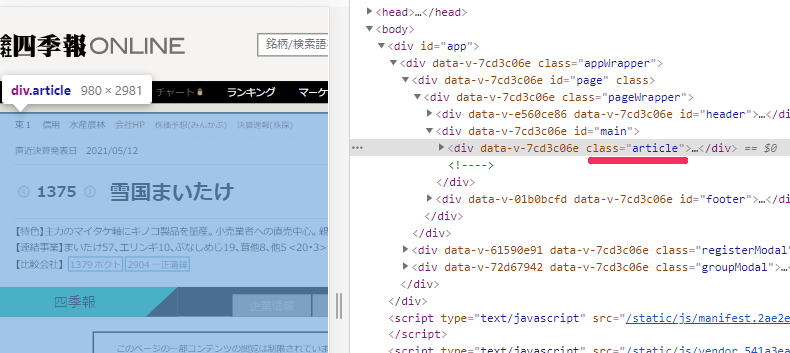
article要素が表示されたら、コンテンツはページに追加されていることになります。
もっと正確にいうと、article要素が表示されるまで待ちます。
そして、article要素内の情報をスクレイピングしていきます。
今回は、以下の要素をスクレイピングします。
article要素の中のmain要素とarticle要素の中のinformation要素
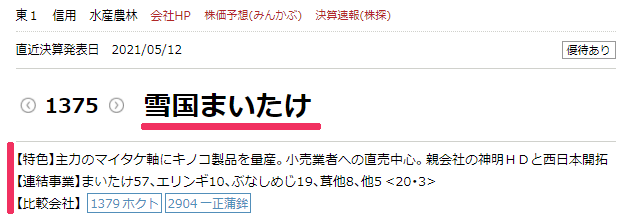
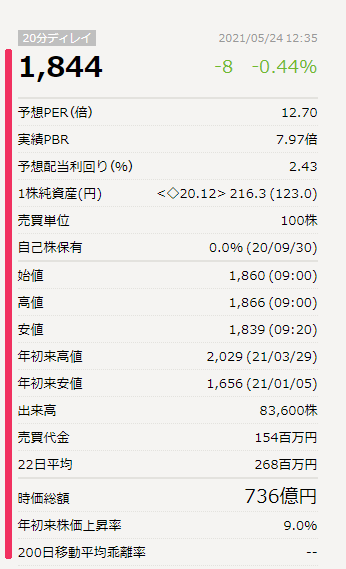
aricle要素の中のsection要素
まとめ
やはり、動的コンテンツというのがポイントになります。
ここさえクリエできたら、あとはそれほど大したことはありません。
サンプルコードを見てわからない場合は、他の記事を参考にしてください。
当ブログでは、多くのサイトをスクレイピングして記事にしています。
それらの記事の中で、疑問を解消する説明があるかもしれません。
以上、企業ページのスクレイピング仕様の説明でした。
最後は、スクレイピングそ行うサンプルコードを載せておきます。
企業ページをスクレイピングして株価と会社情報を取得する
コピペで動くサンプルコードです。
これをベースにして、各自で使いやすいようにカスタマイズしてください。
import bs4
import traceback
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 3
# 遷移間隔(秒)
INTERVAL_TIME = 2
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
def get_source_from_page(driver, url):
# ターゲット
driver.get(url)
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CLASS_NAME, 'article')))
page = driver.page_source
return page
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
try:
company_name = ""
information = ""
current = None
main_elem = soup.find("div", class_="main")
if main_elem:
name_elem = main_elem.find(class_="name")
if name_elem:
company_name = name_elem.text
information_elem = soup.find("div", class_="information")
if information_elem:
p_tag_all = information_elem.find_all('p')
for p_tag in p_tag_all:
tmp_text = p_tag.text
if tmp_text:
information = information + str(tmp_text)
# 比較会社
rival = []
li_tag_all = information_elem.find_all("li")
for li_tag in li_tag_all:
tmp_text = li_tag.text
tmp_list = tmp_text.split(" ")
if len(tmp_list) > 0:
# 会社名にスペースがある場合は会社名の一部だけ(そもそも、codeさえ取得できればOK)
tmp_company = {"code": tmp_list[0],
"name": tmp_list[1]}
rival.append(tmp_company)
section_elem = soup.find("div", class_="section")
if section_elem:
current_elem = section_elem.find(class_="current")
if current_elem:
current = current_elem.text
# stockの下の各行
stock = []
dl_tag_all = section_elem.find(class_="stock").find_all("dl")
for dl_tag in dl_tag_all:
dt_tag = dl_tag.find("dt")
dd_tag = dl_tag.find("dd")
if dt_tag and dd_tag:
dt_text = dt_tag.text
dd_text = dd_tag.text
tmp_row = {"title": dt_text,
"data": dd_text}
stock.append(tmp_row)
info = {"name": company_name,
"information": information,
"rival": rival,
"current": current,
"stock": stock}
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# 証券コード一覧取得
def get_code_list():
result = ['1375', '1376', '1377', '1379', '1380', '1381', '1382', '1383', '1384']
return result
if __name__ == "__main__":
code_list = get_code_list()
base_url = "https://shikiho.jp/stocks/"
# ブラウザのdriver取得
driver = get_driver()
# ページカウンター制御
page_counter = 0
for code in code_list:
page_counter = page_counter + 1
target_url = base_url + str(code) + "/"
# ページのソース取得
source = get_source_from_page(driver, target_url)
# ソースからデータ抽出
data = get_data_from_source(source)
print(data)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
# 閉じる
driver.quit()
上記を実行すると、次の結果が表示されます。
{'name': '雪国まいたけ', 'information': '【特色】主力のマイタケ軸にキノコ製品を量産。小売業者への直売中心。親会社の神明HDと西日本開拓【連結事業】まいたけ57、エリンギ10、ぶなしめじ19、茸他8、他5 <20・3>', 'rival': [{'code': '1379', 'name': 'ホクト'}, {'code': '2904', 'name': '一正蒲鉾'}], 'current': '1,850', 'stock': [{'title': '予想PER(倍)', 'data': '12.72'}, {'title': '実績PBR', 'data': '7.99倍'}, {'title': '予想配当利回り(%)', 'data': '2.43'}, {'title': '1株純資産(円)', 'data': '<◇20.12> 216.3 (123.0)'}, {'title': '売買単位', 'data': '100株'}, {'title': '自己株保有', 'data': '0.0% (20/09/30)'}, {'title': '始値', 'data': '1,860 (09:00)'}, {'title': '高値', 'data': '1,866 (09:00)'}, {'title': '安値', 'data': '1,839 (09:20)'}, {'title': '年初来高値', 'data': '2,029 (21/03/29)'}, {'title': '年初来安値', 'data': '1,656 (21/01/05)'}, {'title': '出来高', 'data': '112,100株'}, {'title': '売買代金', 'data': '207百万円'}, {'title': '22日平均', 'data': '268百万円'}, {'title': '時価総額', 'data': '737億円'}, {'title': '年初来株価上昇率', 'data': '9.2%'}, {'title': '200日移動平均乖離率', 'data': '--'}]}
{'name': 'カネコ種苗', 'information': '【特色】野菜・牧草種子など種苗事業や農薬が収益柱。農業資材や花きも販売。利益は下期の比重高い【連結事業】種苗14(11)、花き15(1)、農材46(3)、施設材25(3) <20・5>', 'rival': [{'code': '1377', 'name': 'サカタタネ'}, {'code': '1382', 'name': 'ホーブ'}, {'code': '1383', 'name': 'ベルグアス'}], 'current': '1,558', 'stock': [{'title': '予想PER(倍)', 'data': '15.28'}, {'title': '実績PBR', 'data': '0.89倍'}, {'title': '予想配当利回り(%)', 'data': '1.79'}, {'title': '1株純資産(円)', 'data': '<連20.11> 1,769 (1,749)'}, {'title': '売買単位', 'data': '100株'}, {'title': '自己株保有', 'data': '0.2% (20/11/30)'}, {'title': '始値', 'data': '1,551 (09:00)'}, {'title': '高値', 'data': '1,562 (09:07)'}, {'title': '安値', 'data': '1,551 (09:00)'}, {'title': '年初来高値', 'data': '1,695 (21/04/06)'}, {'title': '年初来安値', 'data': '1,530 (21/05/13)'}, {'title': '出来高', 'data': '1,400株'}, {'title': '売買代金', 'data': '2百万円'}, {'title': '22日平均', 'data': '9百万円'}, {'title': '時価総額', 'data': '183億円'}, {'title': '年初来株価上昇率', 'data': '-1.1%'}, {'title': '200日移動平均乖離率', 'data': '0.2%'}]}
{'name': 'サカタのタネ', 'information': '【特色】種苗首位級。ブロッコリー世界シェア6割。ヒマワリ、トルコギキョウ等花き強化。造園緑化も【連結事業】国内卸売27(31)、海外卸売60(29)、小売9(0)、他5(3)【海外】60 <20・5>', 'rival': [{'code': '1376', 'name': 'カネコ種苗'}, {'code': '1382', 'name': 'ホーブ'}, {'code': '1383', 'name': 'ベルグアス'}], 'current': '3,785', 'stock': [{'title': '予想PER(倍)', 'data': '27.64'}, {'title': '実績PBR', 'data': '1.66倍'}, {'title': '予想配当利回り(%)', 'data': '0.87'}, {'title': '1株純資産(円)', 'data': '<連20.11> 2,357 (2,278)'}, {'title': '売買単位', 'data': '100株'}, {'title': '自己株保有', 'data': '5.8% (20/11/30)'}, {'title': '始値', 'data': '3,820 (09:00)'}, {'title': '高値', 'data': '3,820 (09:00)'}, {'title': '安値', 'data': '3,780 (09:07)'}, {'title': '年初来高値', 'data': '4,145 (21/03/29)'}, {'title': '年初来安値', 'data': '3,490 (21/01/04)'}, {'title': '出来高', 'data': '217,000株'}, {'title': '売買代金', 'data': '827百万円'}, {'title': '22日平均', 'data': '387百万円'}, {'title': '時価総額', 'data': '1,796億円'}, {'title': '年初来株価上昇率', 'data': '6.0%'}, {'title': '200日移動平均乖離率', 'data': '1.9%'}]}
説明が必要な箇所を説明しておきます。
# 証券コード一覧取得
def get_code_list():
result = ['1375', '1376', '1377', '1379', '1380', '1381', '1382', '1383', '1384']
return result
ここは、本来ならCSVから読み込んだ証券コード一覧が返ります。
上場企業すべての情報が必要なら、CSVを読み込む処理に変更しましょう。
あと、次の記述部分でプログラムの暴発を防いでいます。
CHROMEDRIVER = "chromedriver.exeのパス" # 改ページ(最大) PAGE_MAX = 3 # 遷移間隔(秒) INTERVAL_TIME = 2
上記の設定では、最大で3社分(PAGE_MAX = 3)をスクレイピングします。
そして、処理毎に2秒の待ち時間(INTERVAL_TIME = 2)を設けています。
各自で判断して、ここの設定を変更してください。
上場企業全部を対象にしたいなら、「PAGE_MAX = 10000」に設定することになります。

