「Wikipediaの記事データを大量に収集したい」
「機械学習で大量のテキストデータが必要になった」
「Wikipediaをスクレイピングしようと考えている」
このような場合には、WikiExtractorがオススメです。
この記事では、WikiExtractorについて解説しています。
本記事の内容
- WikiExtractorとは?
- WikiExtractorのシステム要件
- WikiExtractorのインストール
- WikiExtractorの動作確認
それでは、上記に沿って解説していきます。
WikiExtractorとは?
Wikipediaの記事を取得できるPythonツールです。
コマンドラインツールとして利用します。
大量のテキストが必要な場合に、WikiExtractorが役に立ちます。
例えば、機械学習における自然言語処理です。
データ収集と言うと、どうしてもスクレイピングという発想になります。
しかし、WikiExtractorを使えばスクレイピング不要です。
この辺については、後述します。
以上、WikiExtractorについて説明しました。
WikiExtractorのシステム要件
現時点(2022年3月末)でのWikiExtractorの最新バージョンは、3.0.6となります。
この最新バージョンは、2021年10月14日にリリースされています。
サポートOSに関しては、以下を含むクロスプラットフォーム対応です。
- Windows
- macOS
- Linux
しかし、Windowsではまともに動かない場合があります。
公式サイトでも、そのことについて言及しています。
修正の入ったWikiExtractorであれば、Windowsでも動きます。
ただし、バージョンが3.0.4になります。
3.0.4だと、JSON形式に出力できないのです。
そのこともあり、Windowsでの利用はオススメできません。
また、サポート対象となるPythonのバージョンはPython 3となっています。
Python 3というのは、かなり幅が広いと言えます。
以下は、Python公式開発サイクルです。
| バージョン | リリース日 | サポート期限 |
| 3.6 | 2016年12月23日 | 2021年12月23日 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
このPython公式開発サイクルに従うなら、Python 3.7以降のサポートだけで十分です。
個人的にも、古いPythonは切り捨ててもいいと思います。
よって、ここではPython 3.7以降を推奨しておきます。
以上、WikiExtractorのシステム要件について説明しました。
次は、WikiExtractorをインストールしていきます。
WikiExtractorのインストール
検証は、次のバージョンのPythonで行います。
$ python -V Python 3.10.2
まずは、現状のインストール済みパッケージを確認しておきます。
$ pip list Package Version ---------- ------- pip 22.0.4 setuptools 61.2.0 wheel 0.36.2
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、WikiExtractorのインストールです。
WikiExtractorのインストールは、以下のコマンドとなります。
pip install wikiextractor
WikiExtractorのインストールは、すぐに終わります。
終了したら、どんなパッケージがインストールされたのかを確認します。
$ pip list Package Version ------------- ------- pip 22.0.4 setuptools 61.2.0 wheel 0.36.2 wikiextractor 3.0.6
WikiExtractorには、依存パッケージがありませんね。
これであれば、既存環境にも容易に導入が可能です。
以上、WikiExtractorのインストールを説明しました。
次は、WikiExtractorの動作確認を行います。
WikiExtractorの動作確認
WikiExtractorの動作確認は、次の流れで説明します。
- Wikipedia記事データの取得
- WikiExtractorによるデータ抽出(JSON化)
それぞれを下記で説明します。
Wikipedia記事データの取得
Wikipediaの記事データは、XML形式で公開されています。
そのため、スクレイピングをする必要はありません。
Wikipediaは、スクレイピングによるサーバー負荷を嫌っています。
また、スクレイピングで取得できないデータは基本的にはありません。
つまり、抵抗するだけ無駄と言えます。
その意味では、Wikipediaの考え方には大いに賛成します。
Amazonなどもこの考え方を見習って欲しいモノです。
そうすれば、余計なサーバー負荷を減らせると思います。
あと、余計なスクレイピング対策ですね。
システム的にも、その分だけ複雑になってしまいます。
話が逸れましたが、Wikipediaの記事データはXMLで用意されています。
Index of /jawiki/latest/
https://dumps.wikimedia.org/jawiki/latest/
最新の日本語データは、上記URLで公開されています。
たくさんありますが、必要なファイルは以下。
jawiki-latest-pages-articles.xml.bz2
このファイルに記事が記述されています。
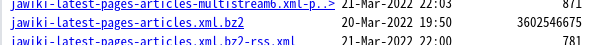
この時点のファイル容量は、3.3GB以上です。
ダウンロードには、30分程度は見積もった方がよいでしょう。
なお、PowerShellのwgetでは途中でエラーになります。
そもそも、Windowsでの利用はオススメしていませんけどね。
WikiExtractorによるデータ抽出(JSON化)
wikiextractorコマンドとして利用します。
ヘルプを見ると、オプションがたくさんあります。
$ wikiextractor -h
usage: wikiextractor [-h] [-o OUTPUT] [-b n[KMG]] [-c] [--json] [--html] [-l] [-ns ns1,ns2] [--templates TEMPLATES] [--no-templates] [--html-safe HTML_SAFE]
[--processes PROCESSES] [-q] [--debug] [-a] [-v]
input
Wikipedia Extractor:
Extracts and cleans text from a Wikipedia database dump and stores output in a
number of files of similar size in a given directory.
Each file will contain several documents in the format:
<doc id="" url="" title="">
...
</doc>
If the program is invoked with the --json flag, then each file will
contain several documents formatted as json ojects, one per line, with
the following structure
{"id": "", "revid": "", "url": "", "title": "", "text": "..."}
The program performs template expansion by preprocesssng the whole dump and
collecting template definitions.
positional arguments:
input XML wiki dump file
options:
-h, --help show this help message and exit
--processes PROCESSES
Number of processes to use (default 7)
Output:
-o OUTPUT, --output OUTPUT
directory for extracted files (or '-' for dumping to stdout)
-b n[KMG], --bytes n[KMG]
maximum bytes per output file (default 1M); 0 means to put a single article per file
-c, --compress compress output files using bzip
--json write output in json format instead of the default <doc> format
Processing:
--html produce HTML output, subsumes --links
-l, --links preserve links
-ns ns1,ns2, --namespaces ns1,ns2
accepted namespaces
--templates TEMPLATES
use or create file containing templates
--no-templates Do not expand templates
--html-safe HTML_SAFE
use to produce HTML safe output within <doc>...</doc>
Special:
-q, --quiet suppress reporting progress info
--debug print debug info
-a, --article analyze a file containing a single article (debug option)
-v, --version print program version
実際に利用したのは、次のコマンドです。
wikiextractor jawiki-latest-pages-articles.xml.bz2 -o ./output --json
jawiki-latest-pages-articles.xml.bz2は、ダウンロードしたXMLファイルです。
圧縮されたままで利用できます。
-o ./output
抽出結果の保存先の指定です。
事前にディレクトリを作成する必要はありません。
--json
使いづらい 「<doc>…</doc>」ではなく、JSON形式で抽出可能です。
後で楽をしたいなら、このオプションは利用しましょう。
まとめ
上記で示したコマンドを実行した結果を確認します。
outputディレクトリの下には、次のディレクトリが作成されています。
$ ls output/ AA AC AE AG AI AK AM AO AQ AS AU AW AY BA BC BE BG BI BK BM BO BQ BS BU BW BY CA CC CE CG CI CK CM CO AB AD AF AH AJ AL AN AP AR AT AV AX AZ BB BD BF BH BJ BL BN BP BR BT BV BX BZ CB CD CF CH CJ CL CN
そして、各ディレクトリの下にファイルが作成されます。
$ ls output/AA wiki_00 wiki_06 wiki_12 wiki_18 wiki_24 wiki_30 wiki_36 wiki_42 wiki_48 wiki_54 wiki_60 wiki_66 wiki_72 wiki_78 wiki_84 wiki_90 wiki_96 wiki_01 wiki_07 wiki_13 wiki_19 wiki_25 wiki_31 wiki_37 wiki_43 wiki_49 wiki_55 wiki_61 wiki_67 wiki_73 wiki_79 wiki_85 wiki_91 wiki_97 wiki_02 wiki_08 wiki_14 wiki_20 wiki_26 wiki_32 wiki_38 wiki_44 wiki_50 wiki_56 wiki_62 wiki_68 wiki_74 wiki_80 wiki_86 wiki_92 wiki_98 wiki_03 wiki_09 wiki_15 wiki_21 wiki_27 wiki_33 wiki_39 wiki_45 wiki_51 wiki_57 wiki_63 wiki_69 wiki_75 wiki_81 wiki_87 wiki_93 wiki_99 wiki_04 wiki_10 wiki_16 wiki_22 wiki_28 wiki_34 wiki_40 wiki_46 wiki_52 wiki_58 wiki_64 wiki_70 wiki_76 wiki_82 wiki_88 wiki_94 wiki_05 wiki_11 wiki_17 wiki_23 wiki_29 wiki_35 wiki_41 wiki_47 wiki_53 wiki_59 wiki_65 wiki_71 wiki_77 wiki_83 wiki_89 wiki_95
$ ls output/AB wiki_00 wiki_06 wiki_12 wiki_18 wiki_24 wiki_30 wiki_36 wiki_42 wiki_48 wiki_54 wiki_60 wiki_66 wiki_72 wiki_78 wiki_84 wiki_90 wiki_96 wiki_01 wiki_07 wiki_13 wiki_19 wiki_25 wiki_31 wiki_37 wiki_43 wiki_49 wiki_55 wiki_61 wiki_67 wiki_73 wiki_79 wiki_85 wiki_91 wiki_97 wiki_02 wiki_08 wiki_14 wiki_20 wiki_26 wiki_32 wiki_38 wiki_44 wiki_50 wiki_56 wiki_62 wiki_68 wiki_74 wiki_80 wiki_86 wiki_92 wiki_98 wiki_03 wiki_09 wiki_15 wiki_21 wiki_27 wiki_33 wiki_39 wiki_45 wiki_51 wiki_57 wiki_63 wiki_69 wiki_75 wiki_81 wiki_87 wiki_93 wiki_99 wiki_04 wiki_10 wiki_16 wiki_22 wiki_28 wiki_34 wiki_40 wiki_46 wiki_52 wiki_58 wiki_64 wiki_70 wiki_76 wiki_82 wiki_88 wiki_94 wiki_05 wiki_11 wiki_17 wiki_23 wiki_29 wiki_35 wiki_41 wiki_47 wiki_53 wiki_59 wiki_65 wiki_71 wiki_77 wiki_83 wiki_89 wiki_95
ファイルは、単語数ではなく容量で区切られています。
例えば、wiki_00には10個、wiki_01には15個というような感じです。
今回は、JSON形式での出力を指定しています。
ほぼ確実に勘違いするところですが、決してJSONファイルではありません。
記事毎のデータが、JSON形式で出力されています。
1個のwikiファイル内にJSONが改行されて記述されているのです。
{"id": "143962", "revid": "", "url": "", "title": "", "text": "記事本文"}
{"id": "143963", "revid": "", "url": "", "title": "", "text": "記事本文"}
そのため、wikiファイルはJSONファイルとは言えません。
そして、これはこれで扱いにくいデータです。
しかし、デフォルトではもっと扱いにくいデータと言えます。
デフォルトでは、次のように出力されます。
<doc id="143962" revid="" url="" title="">
... (記事本文)
</doc>
<doc id="143963" revid="" url="" title="">
... (記事本文)
</doc>
以上、WikiExtractorの動作確認を説明しました。

