
Yahooニュースは、多くの人が見ています。
そのため、各社がこぞってYahooに記事を提供している状況です。
そのような状況において、トピックスに取り上げられることは大きな意味を持ちます。
トピックスに取り上げられると、多くの人の目に触れます。
このことより、Yahooニュースのトピックスには影響力があると言えます。
この記事では、その影響力のあるYahooニュースのトピックスをスクレイピングしていきます。
本記事の内容
- API・RSSを利用せずにスクレイピングする理由
- Yahooニュースにおけるトピックスのスクレイピング仕様
- スクレイピングするための準備
- 【サンプルコード】Yahooニュースにおけるトピックスのスクレイピング
それでは、上記に沿って解説していきます。
API・RSSを利用せずにスクレイピングする理由
利用できるなら、すでにあるモノを使った方が効率的です。
でも、今回はAPIもRSSも利用しません。
- APIを利用しない理由
- RSSを利用しない理由
それぞれを下記で説明します。
APIを利用しない理由
Yahoo!ニュースWeb APIサービス一時提供終了のお知らせ
https://techblog.yahoo.co.jp/web/news/yahoo_japan_web_api_close/
2014年まではAPIが存在していたようです。
しかし、今はもうYahooニュースに関するAPIが存在していません。
下記は、Googleトレンドで「Yahooニュース」の検索ボリュームを調べた結果です。
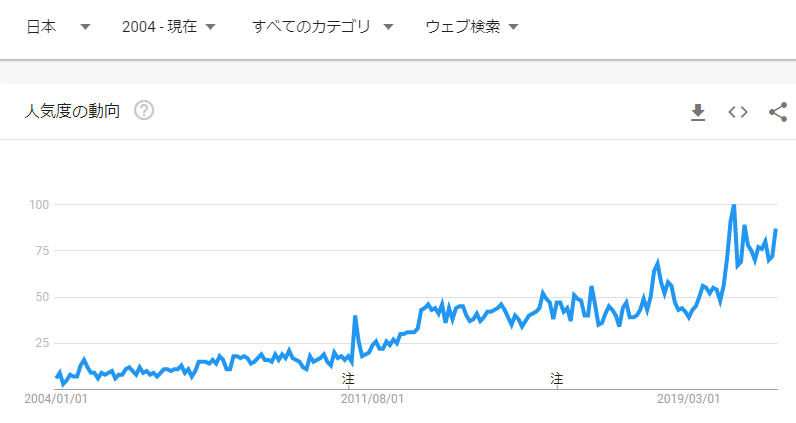
社会動向を掴むという意味では、YahooニュースのAPIへの需要はありそうなんですけどね。
もしかしたら、だからこそAPIがないのかもしれません。
価値ある情報は、簡単にはあげませんよというパターンです。
どんな理由があるにせよ、YahooニュースのAPIが存在していないという状況です。
したがって、APIを利用したくても利用できません。
これが、APIを利用しない理由になります。
RSSを利用しない理由
RSSは、存在しています。
RSS一覧
https://news.yahoo.co.jp/rss
シンプルに使えません。
使えない理由は、トピックスにおける各RSSには最大で8個の記事データしかないからです。
最新の8件のニュースのみです。

やはり、このトピックスのデータはやすやすと公開したくないのかもしれません。
その証拠に、トピックス以外のRSSとはデータ件数が異なります。
| 項目 | RSS上の最大件数 |
| トピックス | 8 |
| カテゴリごとのニュース | 50 |
| ニュース提供社 | 50 |
※「みんなの意見」は、ニュースではないので対象外
この状況を見てどう思いますか?
トピックスは、明らかに絞ってますよね。
あくまで、Yahooニュースのトピックスに価値があるのです。
その意味では、RSSのデータは件数不足と言えます。
したがって、RSSは利用価値がありません。
これが、RSSを利用しない理由になります。
なお、RSSへ常時アクセスすれば件数不足の問題は解消できるかもしれません。
しかし、その場合はRSSの更新時間を考慮する必要があるでしょう。
また、常時アクセスは負荷の面からも現実的ではありません。
まとめ
APIは、存在しないので利用できません。
RSSは、存在するけど利用価値がありません。
RSSについては、正確には利用が困難と言ったほうがいいかもしれません。
よって、自分の裁量の及ぶ範囲で頑張るということになります。
スクレイピングなら、不確定の要素を受けることが少ないです。
RSSが廃止するというリスクとも無関係です。
もちろん、スクレイピングにもデザイン変更などのリスクはあります。
でも、そのリスクへは自分自身で対応可能です。
以上、API・RSSを利用せずにスクレイピングする理由を説明しました。
次は、スクレイピング仕様を確認します。
Yahooニュースにおけるトピックスのスクレイピング仕様
スクレイピングは、まずページにアクセスします。
そして、そのページで必要な情報を抽出することになります。
そのことからも、スクレイピングする上では以下の二つが重要な要素と言えます。
- アクセス先URL
- 抽出情報
それぞれを下記で説明します。
アクセス先URL
主要トピックス一覧
https://news.yahoo.co.jp/topics/top-picks
上記URLにアクセスします。
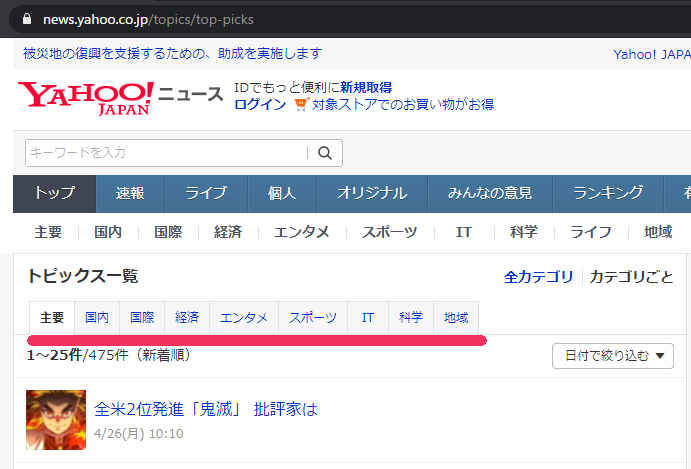
このページでは、最大25件のニュースが表示されています。
そして、改ページリンクがページの下部にあります。

各カテゴリーは、基本的に同じような構成となっています。
カテゴリーは、全部で以下。
| [表示] | [キー] |
| 主要 | top-picks |
| 国内 | domestic |
| 国際 | world |
| 経済 | business |
| エンタメ | entertainment |
| スポーツ | sports |
| IT | it |
| 科学 | science |
| 地域 | local |
[キー]は、●●●に入る値です。
https://news.yahoo.co.jp/topics/●●●
このURLは、下線を引いた箇所のリンクです。
ここまでより、必要なURLが明確になりました。
なお、改ページのURLに関しては必要ありません。
「次へ」リンクをクリックして、遷移するようにします。
Seleniumを使えば、簡単に実現できます。
抽出情報
今回、取得するのは以下の二つのデータとします。
- ピックアップページURLの識別情報(pickup_id)
- ニュースタイトル(title)
これらを取得する方法を説明します。
以下は、「https://news.yahoo.co.jp/topics/●●●」で表示されるページの一部です。
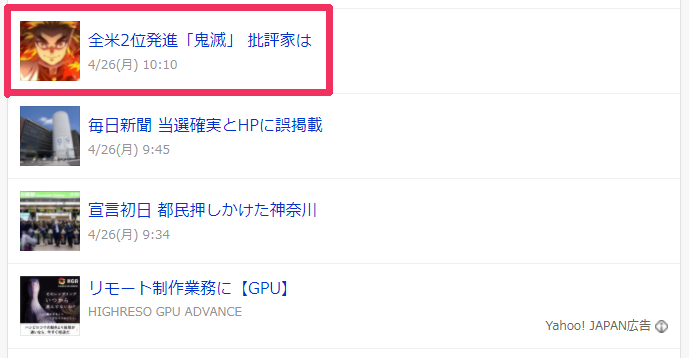
1ページあたり、最大で25個のニュースが存在しています。
この中から、「鬼滅」のニュースのHTMLタグを確認します。
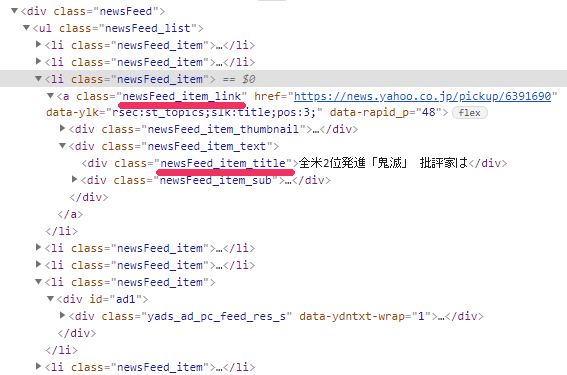
newsFeedをclassに持つ要素(div)が、確認できます。
この要素をbase要素とします。
base要素の下に、newsFeed_item_linkをclassに持つ要素が見えます。
最大で25個あります。
これがニュース記事を表す要素となります。
さらに、newsFeed_item_link要素の下にnewsFeed_item_titleをclassに持つ要素があります。
まずは、この親子関係を認識します。
あとは、もう各要素から値を抽出するだけです。
newsFeed_item_link要素からは、「6391690」という値が対象になります。
newsFeed_item_title要素からは、「全米2位発進「鬼滅」 批評家は」という値を抽出します。
まとめ
比較的素直なページ構成(URL)です。
そして、比較的素直なHTML構造になります。
ただ、改ページが若干面倒になりがちです。
でも、Seleniumを使えば、総件数からページを導き出すということも不要です。
「次へ」が押せる限り、「次へ」を押すだけになります。
以上、Yahooニュースにおけるトピックスのスクレイピング仕様に関する説明でした。
次は、この仕様を実現するために必要なモノを確認します。
スクレイピングするための準備
Pythonで以下のライブラリが動けば、OKです。
- Selenium
- BeautifulSoup4
- lxml
これらのライブラリが必要な理由とそのインストール方法は、次の記事で解説しています。
「メルカリのスクレイピング仕様(考え方)」の部分です。

以上、スクレイピングするための準備に関する説明でした。
次は、実際にスクレイピングを行っていきます。
【サンプルコード】Yahooニュースにおけるトピックスのスクレイピング
トピックスのニュースをスクレイピングするサンプルコードは、以下。
import bs4
import traceback
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
# ドライバーのフルパス
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 2
# 遷移間隔(秒)
INTERVAL_TIME = 3
# 対象カテゴリー
#CATEGORY = ["top-picks", "domestic", "world", "business","entertainment", "sports", "it", "science", "local"]
CATEGORY = ["business"]
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
page_source = driver.page_source
return page_source
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
try:
info = []
base = soup.find(class_="newsFeed")
if base:
a_elems = base.find_all("a", class_="newsFeed_item_link")
for elem in a_elems:
item = {}
href = elem.attrs['href']
pickup_id = href.replace('https://news.yahoo.co.jp/pickup/', '')
title = elem.find(class_="newsFeed_item_title").text
item["pickup_id"] = pickup_id
item["title"] = title
info.append(item)
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# 次のページへ遷移
def next_btn_click(driver):
try:
# 次へボタン
elem_btn = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.CLASS_NAME, 'pagination_item-next'))
)
class_value = elem_btn.get_attribute("class")
if class_value.find('pagination_item-disabled') > 0:
return False
else:
# クリック処理
actions = ActionChains(driver)
actions.move_to_element(elem_btn)
actions.click(elem_btn)
actions.perform()
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
return True
except Exception as e:
print("Exception\n" + traceback.format_exc())
return False
if __name__ == "__main__":
# ブラウザのdriver取得
driver = get_driver()
# ページカウンター制御
page_counter = 0
for category in CATEGORY:
page_counter = page_counter + 1
# 対象ページURL
page = "https://news.yahoo.co.jp/topics/" + str(category)
# ページのソース取得
source = get_source_from_page(driver, page)
result_flg = True
while result_flg:
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存
print(data)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
page_counter = 0
break
# 改ページ処理
result_flg = next_btn_click(driver)
source = driver.page_source
page_counter = page_counter + 1
# 閉じる
driver.quit()
全体的には、仕様の内容を見ながら確認してください。
説明が必要だと思う箇所を、下記で説明していきます。
サンプルコードを動かす上で、とても重要な定数です。
内容を必ず理解してください。
# 改ページ(最大) PAGE_MAX = 2 # 遷移間隔(秒) INTERVAL_TIME = 3
詳細は、次の記事の「商品一覧ページから商品IDを抽出する」をご覧ください。
これら定数の意味を理解しないと、サンプルコードは全件数分のニュースを取得してくれません。
次の定数は、カテゴリーに関してです。
# 対象カテゴリー #CATEGORY = ["top-picks", "domestic", "world", "business","entertainment", "sports", "it", "science", "local"] CATEGORY = ["business"]
現状は、ビジネスだけ対象にしています。
複数を対象にする場合は、リスト形式で指定します。
次は、改ページ処理の部分です。
「次へ」を押して遷移すると箇所になります。
class_value = elem_btn.get_attribute("class")
if class_value.find('pagination_item-disabled') > 0:
return False
else:
# クリック処理
actions = ActionChains(driver)
actions.move_to_element(elem_btn)
actions.click(elem_btn)
actions.perform()
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
return True
Yahooニュースは、最後のページまで行っても「次へ」ボタンが出たままです。

一般的には、最終ページでは「次へ」が非表示になります。
でも、Yahooニュースは表示されたままです。
単純にCSSで見た目を変えているだけです。
正確には、「pagination_item-disabled」がclassに付加されます。
よって、「pagination_item-disabled」を「次へ」の要素に含めばそこで終了としています。
含まないなら、「次へ」をクリックして遷移することになります。
最後に、上記のサンプルコードを実行した際の処理について説明しておきます。
上記のサンプルコードを実行すると、次の結果が表示されます。
[{'pickup_id': '6391700', 'title': '義務化の有休5日 取得率順位は'}, {'pickup_id': '6391686', 'title': '木造ビル増加 東京・銀座にも'}, {'pickup_id': '6391679', 'title': 'いすゞ乗用車 今も根強い人気'}, {'pickup_id': '6391681', 'title': 'トヨタ ソフト系人材採用倍増へ'}, {'pickup_id': '6391662', 'title': 'JAL 春秋航空日本を子会社化へ'}, {'pickup_id': '6391629', 'title': 'GWのキャンセル限定的? 背景は'}, {'pickup_id': '6391622', 'title': '苦境のJR西 教訓は生きているか'}, {'pickup_id': '6391620', 'title': 'ピスタチオ人気 理由は淡い緑'}, {'pickup_id': '6391615', 'title': '鴨川の納涼床 宣言対応迫られる'}, {'pickup_id': '6391600', 'title': 'コロナ入社組「普通」知らない'}, {'pickup_id': '6391570', 'title': '減便検討も時間不足 戸惑う鉄道'}, {'pickup_id': '6391558', 'title': '宣言直前 休業前に「駆け込み」'}, {'pickup_id': '6391551', 'title': '「泥船」苦境の製本 親子の奮闘'}, {'pickup_id': '6391540', 'title': '「ずっと生殺しの状態」嘆く店'}, {'pickup_id': '6391538', 'title': '休業要請「なぜ一律」首かしげ'}, {'pickup_id': '6391533', 'title': 'ビッグサイト無観客 主催者困惑'}, {'pickup_id': '6391524', 'title': '酒類提供の自粛要請 店主ぼう然'}, {'pickup_id': '6391522', 'title': 'マック 宣言地域で店内利用中止'}, {'pickup_id': '6391525', 'title': '爆音マフラー なぜ派手に改造?'}, {'pickup_id': '6391518', 'title': '派手な改造車 機能的価値ある?'}, {'pickup_id': '6391515', 'title': 'ホンダ 小型ロケット開発明かす'}, {'pickup_id': '6391509', 'title': '緊急宣言で6990億円損失も 試算'}, {'pickup_id': '6391504', 'title': '休業要請に落胆 GW直撃で悲鳴'}, {'pickup_id': '6391491', 'title': '4都府県 ワタミや鳥貴族休業へ'}, {'pickup_id': '6391485', 'title': '航空・鉄道各社 減便検討始める'}][{'pickup_id': '6391479', 'title': '百貨店支援20万円 話にならない'}, {'pickup_id': '6391474', 'title': 'たまごっち 在庫の山から再起'}, {'pickup_id': '6391468', 'title': 'USJ 宣言受け25日から臨時休業'}, {'pickup_id': '6391456', 'title': '休業要請 最大20万円の協力金'}, {'pickup_id': '6391454', 'title': 'ANA 赤字予想1050億円改善'}, {'pickup_id': '6391451', 'title': '都 千平方m以内も休業要請へ'}, {'pickup_id': '6391449', 'title': 'GWの国内線予約 昨年の約4倍'}, {'pickup_id': '6391441', 'title': 'ホンダ 40年に全新車EVとFCVに'}, {'pickup_id': '6391436', 'title': '都 20時以降の看板ネオン消灯を'}, {'pickup_id': '6391431', 'title': '居酒屋 酒出せないなら休むしか'}, {'pickup_id': '6391430', 'title': '休業要請へ 1千平方mどのくらい'}, {'pickup_id': '6391405', 'title': '関電前会長ら立件見送りで調整'}, {'pickup_id': '6391384', 'title': 'GW中の高速道路割引 休止へ'}, {'pickup_id': '6391382', 'title': 'ワタミ100億円調達へ 支援活用'}, {'pickup_id': '6391371', 'title': '健保組合 賃金減で8割弱赤字'}, {'pickup_id': '6391366', 'title': 'アップリンク渋谷 5月に閉館'}, {'pickup_id': '6391359', 'title': 'トヨタCO2ゼロ車 レース参戦へ'}, {'pickup_id': '6391346', 'title': '無印良品 全飲料をアルミ缶に'}, {'pickup_id': '6391347', 'title': '日本の富豪50人 資産が48%増'}, {'pickup_id': '6391332', 'title': '東電HD会長 小林喜光氏で調整'}, {'pickup_id': '6391328', 'title': '東京モーターショー 開催中止'}, {'pickup_id': '6391325', 'title': '東京株、午前終値は591円高'}, {'pickup_id': '6391282', 'title': '百貨店協会 休業要請しないで'}, {'pickup_id': '6391280', 'title': '楽天を監視 警戒強める日本政府'}, {'pickup_id': '6391261', 'title': '日本郵政 674億円の特損計上'}]
これは、次のコードで実現しています。
# データ保存
print(data)
ここは、好きな形式でデータを保存してください。
そういう意味で「データ保存」とコメントしています。
私の場合なら、MongoDBにサクッと保存する形です。
ユニークキーを設定すれば、二重登録も簡単に防げます。
MongoDBのインストールは、次の記事で解説しています。

そして、PythonからMongoDBを操作する方法は次の記事でまとめています。

あとは、もしわからない箇所があれば、本ブログでそのキーワードを検索してみてください。
同じような関数や記述について、詳細を説明している場合があります。

