
「DreamBoothをWindowsで試したい」
「Stable Diffusionで高精度のファインチューニングを実行したい」
このような場合には、Dreambooth-Stable-Diffusionがオススメです。
この記事では、WindowsでDreamboothを動かすための方法を解説しています。
本記事の内容
- Dreambooth-Stable-Diffusionとは?
- Dreambooth-Stable-Diffusionのシステム要件
- Dreambooth-Stable-Diffusionのインストール
- Dreambooth-Stable-Diffusionの学習
- Dreambooth-Stable-Diffusionの推論
それでは、上記に沿って解説していきます。
Dreambooth-Stable-Diffusionとは?
追記 2022年12月4日
Stable Diffusion v2に対応した方法を次の記事で解説しています。

Dreambooth-Stable-Diffusionとは、Dreamboothで学習可能なStable-Diffusionのことです。
DreamBooth
https://dreambooth.github.io/
DreamBoothは、まさに夢の技術と言われています。
少ない画像で学習が可能になりますからね。
それも精度の追加学習手法です。
そんな凄い技術であるため、需要は多く存在しています。
特に、Stable Diffusionと組み合わせての利用に期待が大きいです。
しかし、DreamBoothは簡単には動きません。
DreamBoothを動かすには、VRAM 40 GB(GPU)が必要です。
ただ、世界の技術者は凄いですね。
彼らは、小さい容量のVRAMでDreamBoothが動くように改良しています。
そのおかげで、今では10GBを切るGPUでもDreamBoothが動くらしいです。
ただ、DreamBooth単体で動いても仕方がありません。
DreamBoothとStable Diffusionをセットにする必要があります。
それが、望まれている形です。
現状GitHubで「Dreambooth」で検索して出てくる結果の上位は、以下となっています。
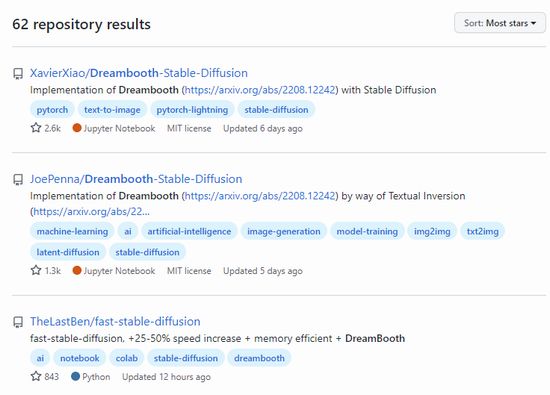
上位二つが群を抜いた評価です。
本家
https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
JoePenna版
https://github.com/JoePenna/Dreambooth-Stable-Diffusion
本家を改良したのが、JoePenna版になります。
本家のインストールについては、そこそこ日本語でも情報が多くなっています。
Google Colabへのインストールがほとんです。
しかし、本家はWindowsへのインストールができません。
実際は可能かもしれませんが、Windowsへのインストール事例は見たことがありません。
そして、実際にできませんでした。
それに対して、JoePenna版はWindowsへのインストールが可能です。
したがって、この記事ではJoePenna版を扱っています。
以上、Dreambooth-Stable-Diffusionについて説明しました。
次は、Dreambooth-Stable-Diffusionのシステム要件を説明します。
Dreambooth-Stable-Diffusionのシステム要件
JoePenna版Dreambooth-Stable-Diffusionのシステム要件は、かなり狭いです。
- GPUメモリ(VRAM)24GB
- PyTorch
GPUメモリが、24GB必要です。
個人用のマシンであれば、RTX 3090(Ti)一択になります。
RTX 4090は、まだまだ普及するのに時間がかかるでしょう。
あとは、クラウドを利用するという手段があります。
クラウドが利用できるなら、JoePenna版を利用する必要はないかもしれません。
もっと情報が出回っているDreambooth-Stable-Diffusionを利用可能ですからね。
それに対して、JoePenna版は本当に情報がありません。
特に日本語の情報が、壊滅的にありません。
また、もう一つのシステム要件はGPU版PyTorchとなります。
GPU版PyTorchのインストールは、次の記事で説明しています。

以上、Dreambooth-Stable-Diffusionのシステム要件を説明しました。
次は、Dreambooth-Stable-Diffusionのインストールを説明します。
Dreambooth-Stable-Diffusionのインストール
Dreambooth-Stable-Diffusionをインストールしていきます。
前提としては、すでにPyTorchはインストール済みとします。
まずは、GitHub上からリポジトリからのクローンです。
git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion
リポジトリルートに移動します。
cd Dreambooth-Stable-Diffusion
基本的には、コマンドでの作業はこのリポジトリルートで実行します。
インストールを続けていきますが、ここではcondaコマンドは利用しません。
condaとpipの併用は、個人的には避けています。
そのため、次のファイルをそのまま利用することはしません。
environment.yaml
name: ldm
channels:
- pytorch
- defaults
dependencies:
- python=3.8.10
- pip=20.3
- cudatoolkit=11.3
- pytorch=1.10.2
- torchvision=0.11.3
- numpy=1.22.3
- pip:
- albumentations==1.1.0
- opencv-python==4.2.0.34
- pudb==2019.2
- imageio==2.14.1
- imageio-ffmpeg==0.4.7
- pytorch-lightning==1.5.9
- omegaconf==2.1.1
- test-tube>=0.7.5
- streamlit>=0.73.1
- setuptools==59.5.0
- pillow==9.0.1
- einops==0.4.1
- torch-fidelity==0.3.0
- transformers==4.18.0
- torchmetrics==0.6.0
- kornia==0.6
- -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
- -e git+https://github.com/openai/CLIP.git@main#egg=clip
- -e .
このYAMLファイルをもとに、requirements.txtを作成します。
requirements.txt
numpy albumentations opencv-python pudb imageio imageio-ffmpeg pytorch-lightning==1.6.5 omegaconf test-tube streamlit setuptools pillow einops torch-fidelity transformers torchmetrics kornia -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers -e git+https://github.com/openai/CLIP.git@main#egg=clip
バージョンは指定せずに、最新をインストールしましょう。
ただし、PyTorch Lightningだけはバージョンを指定します。
最新版(2022年10月時点では1.7.7)のPyTorch Lightningをインストールすると、次のようなエラーが出ます。
AttributeError: module 'pytorch_lightning.loggers' has no attribute 'TestTubeLogger'. Did you mean: 'NeptuneLogger'?
PyTorch Lightningの公式ドキュメントには、次のように警告が記載されていました。
1.7.0以降では、TestTubeLoggerは取り除かれるということです。

では、requirements.txtを利用してパッケージをまとめてインストールします。
コマンドは、以下を実行するだけです。
pip install -r requirements.txt
あと、以下も忘れずに実行しておきましょう。
pip install -e .
これを実行しておかないと、次のようなエラーがそこら中で出まくります。
ModuleNotFoundError: No module named 'ldm'
以上、Dreambooth-Stable-Diffusionのインストールを説明しました。
次は、Dreambooth-Stable-Diffusionの設定を説明します。
Dreambooth-Stable-Diffusionの設定
Dreambooth-Stable-Diffusionを動かすには、準備が必要です。
その設定は、次の手順に分けられます。
- チェックポイントファイルの設置
- 入力画像の設置
- 正則化画像の設置
- main.pyの修正
それぞれを以下で説明します。
チェックポイントファイルの設置
リポジトリルートに「ckpt」ディレクトリを作成します。
mkdir ckpt
そして、ckptは次のページからダウンロードします。
CompVis/stable-diffusion-v-1-4-original · Hugging Face
https://huggingface.co/CompVis/stable-diffusion-v-1-4-original

「sd-v1-4-full-ema.ckpt」を選択。
ダウンロードには、しばらく時間がかかります。
ダウンロードできたら、先ほど作成した「ckpt」に移動させましょう。
入力画像の設置
ここで言う入力画像とは、学習させたい画像のことです。
今回は、ある男性を学習させます。
それは、フリー素材で有名な方です。
この男性の写真をとりあえず10枚ほどダウンロードします。

ただ、このままでは学習させることはできません。
512 x 512のサイズに変更する必要があります。
画像編集ツールで切り抜くのも良いですが、自動でやりましょう。

CodeFormerを利用して、一気に512 x 512の画像に変換します。

ただし、顔を中心に切り抜かれています。
今回は、顔以外に学習させたい特徴はありません。
そのため、これで問題ないでしょう。
では、この入力画像を保存するディレクトリを用意します。
リポジトリルートに作成しましょう。
mkdir training_images
入力画像は、連番になるようにファイル名を変更しておきます。
正則化画像の設置
正則化とは、過学習を防ぐための手法のことです。
過学習を防ぐために、他の男性の画像を用意します。
まずは、 リポジトリルートに保存用のディレクトリを作成しましょう。
mkdir regularization_images
男性の画像をなるべく多く用意します。
ちゃんと集めるとなると、そこそこ大変です。
しかし、リポジトリの開発者が用意してくれています。
それを使わせてもらいましょう。
https://github.com/JoePenna/Stable-Diffusion-Regularization-Images
今回は、「man_unsplash」の画像を利用します。
画像の一括ダウンロードは、コマンドで実行できます。
リポジトリルート上で、以下コマンドを実行します。
git clone https://github.com/djbielejeski/Stable-Diffusion-Regularization-Images-man_unsplash.git mkdir -p regularization_images/man_unsplash mv -v Stable-Diffusion-Regularization-Images-man_unsplash/man_unsplash/*.* regularization_images/man_unsplash
正則化画像は、以下のように確認できるはずです。
処理完了後は、「Stable-Diffusion-Regularization-Images-man_unsplash」を削除しておきます。
main.pyの修正
GPUの数を検出している箇所が、コード上にあります。
修正しないと、次のようなエラーが出ます。
AttributeError: 'int' object has no attribute 'strip'
そのため、main.pyを修正しておきます。
修正前

修正後

一般的な家庭用PCであれば、GPUは1個のはずです。
そのため、「1」と設定しています。
複数ある場合は、コードを適切に修正するようにした方がよいでしょうね。
ここでは、ベタに「1」と設定する対応で済ませます。
以上、Dreambooth-Stable-Diffusionの設定を説明しました。
次は、Dreambooth-Stable-Diffusionの学習を説明します。
Dreambooth-Stable-Diffusionの学習
Dreambooth-Stable-Diffusionの学習を行います。
ただし、本当に学習させようとするとかなりの時間を要することになるでしょう。
そこで、今回はステップ数を「100」にして実行します。
「2000」が良いとか、「800」が良いとかいろんな意見があるようです。
長すぎると過学習を起こしてしまう可能性があると言えます。
このあたりは、正則化画像の枚数とも関係してきます。
とりあえず、まずはDreambooth-Stable-Diffusionが動作させることが重要です。
そのためのコマンドは、以下となります。
python main.py ` --no-test ` --base configs/stable-diffusion/v1-finetune_unfrozen.yaml ` -t ` --actual_resume ckpt/sd-v1-4-full-ema.ckpt ` --reg_data_root regularization_images/man_unsplash ` -n test_project ` --gpus 1, ` --data_root training_images ` --class_word man ` --token freeman ` --max_training_steps 100
各オプションの説明は、ヘルプの内容をご覧ください。
ヘルプは、「python main.py -h」で表示できます。
-n [NAME], --name [NAME]
postfix for logdir
-b [base_config.yaml ...], --base [base_config.yaml ...]
paths to base configs. Loaded from left-to-right. Parameters can be overwritten or added with command-line options of the form `--key value`.
-t [TRAIN], --train [TRAIN]
train
--no-test [NO_TEST] disable test
--max_training_steps MAX_TRAINING_STEPS
Number of training steps to run
--token TOKEN Unique token you want to represent your trained model. Ex: firstNameLastName.
--actual_resume ACTUAL_RESUME
Path to model to actually resume from
--data_root DATA_ROOT
Path to directory with training images
--reg_data_root REG_DATA_ROOT
Path to directory with regularization images
--class_word CLASS_WORD
Match class_word to the category of images you want to train. Example: 'man', 'woman', or 'dog'.
--gpus GPUS Number of GPUs to train on (int) or which GPUs to train on (list or str) applied per node Default: ``None``.
説明が必要なモノは、次のオプションになります。
- gpus
- class_word
- token
gpus
他の事例によると、次のように指定しているパターンが多いです。
公式手順にもそのように記載されています。
--gpus 0,
しかし、Windowsの場合では次のエラーが出てしまいます。
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper__index_select)
対処療法的に、「1」と設定しています。
「1」と設定すれば、Windowsでも動くという報告をちらほら見かけます。
そして、実際に動くのです。
class_word
正則化画像のカテゴリーに該当します。
今回は、「man」と指定しています。
Stable-Diffusion上の「man」というキーワードに学習を加えたということですね。
token
「学習済みモデルを表す一意なトークン」
ヘルプの説明を直訳すると、上記のように表現します。
今回は、「freeman」と指定しています。
この「freeman」がテキストに含まれている場合、学習させたモデルが採用されます。
ただし、それはclass_wordで指定した値とセットの場合に限られます。
ちょっと何言っているかわからないかもしれませんね。
プロンプトで表現した方が、理解しやすいでしょう。
次のプロンプトでは、学習済みモデルは採用されません。
a man in the room
学習済みモデルが採用されるには、次のようなプロンプトにします。
a freeman man in the room
tokenとclass_wordを並べる必要があるということです。
まとめ
コマンドを実行すると、コンソールにはいろいろと表示されます。
不安になりつつも、次のような表示が出れば一安心です。
Epoch 0: 4%|▋ | 43/1010 [01:05<24:35, 1.53s/it, loss=0.278, v_num=0, train/loss_simple_step=0.0417, train/loss_vlb_step=0.00015, train/loss_step=0.0417, global_step=42.00]
今回は、ステップ数を「100」に設定しています。
そのため、数分で処理が終わります。
This is global step 100. Epoch 0: 10%| | 100/1010 [02:36<23:45, 1.57s/it, loss=0.273, v_num=0, train/loss_simple_step=0.0177, train/loss_vlb_step=7.47e-5, train/loss_step=0.0177, global_step=99.00, train/loss_si Training complete. max_training_steps reached or we blew up.
結果は、「logs」ディレクトリに保存されています。
リポジトリルートに「logs」ディレクトリが新たに作成されています。
学習済みモデルを利用するには、「last.ckpt」を指定することになります。
以上、Dreambooth-Stable-Diffusionの学習を説明しました。
最後に、Dreambooth-Stable-Diffusionの推論を説明します。
Dreambooth-Stable-Diffusionの推論
Dreambooth-Stable-Diffusionの推論を行います。
Dreambooth-Stable-Diffusionの学習まで終われば、あとはもう簡単です。
さすがに100ステップでは、推論する価値がないでしょう。
そのため、800ステップで再度学習させました。
その学習済みモデルをもとに、推論を行います。
ヘルプは、次のようにして確認できます。
> python scripts/stable_txt2img.py -h
usage: stable_txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG]
[--ckpt CKPT] [--seed SEED] [--precision {full,autocast}] [--embedding_path EMBEDDING_PATH]
options:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
--embedding_path EMBEDDING_PATH
Path to a pre-trained embedding manager checkpoint
実際に用いたコマンドは、以下。
まずは、「freeman」を含めずに実行します。
python scripts/stable_txt2img.py ` --ddim_eta 0.0 ` --n_samples 1 ` --n_iter 4 ` --scale 7.5 ` --ddim_steps 100 ` --ckpt logs/training_images2022-10-15T15-20-55_test_project/checkpoints/last.ckpt ` --prompt "portrait photograph of man 35mm film vintage glass"
上記を実行すると、推論が始まります。
学習に比べると、すぐに終わります。
次のように表示されて、処理が完了します。
Your samples are ready and waiting for you here: outputs/txt2img-samples
入力したプロンプトをファイル名にして、画像が作成されます。
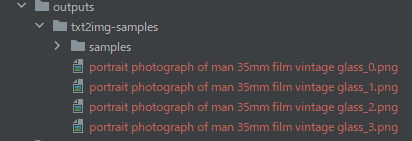
普通に「man」ですね。

では、今度は「freeman」を「man」の前に付加してみましょう。
プロンプトのみを変更して、実行した結果は以下。

同じ場所に保存されています。
そして、結果は見事にフリー素材の人になりました。

さらに精度を上げる余地があります。
入力画像を増やしたり、学習時のステップ数を増やすことです。
以上、Dreambooth-Stable-Diffusionの推論を説明しました。

