
上場企業のWebサイトにおける文字コードを調査しました。
UTF-8の比率は、思ったよりもありました。
でも、その結果とともに残念な事実も判明。
本記事の内容
- 調査内容
- 調査結果『HTTPヘッダーの「Content-Type」』
- 調査結果『meta要素の「charset属性」』
- 調査結果『バイト文字列の「推定文字コード」』
- 調査の振り返り
それでは、上記に沿って解説していきます。
調査内容
対象とした上場企業は、3842社です。
(2021年4月21日時点での上場企業が対象)
これらの企業のWebサイトにおける文字コードを調べています。
そして、調べた文字コードは以下の3種類です。
- HTTPヘッダーの「Content-Type」
- meta要素の「charset属性」
- バイト文字列の「推定文字コード」
それぞれを下記で説明します。
HTTPヘッダーの「Content-Type」
一般的に、ブラウザはContent-Typeをもとに文字コードを認識しています。
HTTPヘッダーは、Chrome DevToolsなどで確認できます。
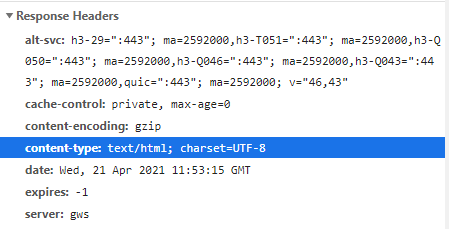
meta要素の「charset属性」
metaタグでの指定は、必須ではありません。
HTTPヘッダーの「Content-Type」がない場合に、この指定が必要となります。
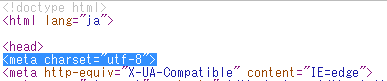
バイト文字列の「推定文字コード」
これは、おまけみたいなモノです。
対象となるページをバイト文字列として扱います。
そして、そのバイト文字列の文字コードを推定します。
つまり、プログラムが推定する文字コードと言えます。
具体的には、chardetで文字コードを推定します。
chardetについては、次の記事で解説しています。

では、それぞれの文字コード別に調査結果を確認していきましょう。
調査結果『HTTPヘッダーの「Content-Type」』
HTTPヘッダーの「Content-Type」の集計結果は、以下。
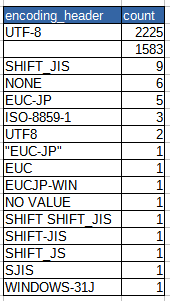
まず、これを見てどう思いますか?
個人的には、未設定の多さに目がいきました。
ただし、この結果は若干疑う必要があります。
Pythonを使って、HTTPヘッダーを取得しています。
その場合に、HTTPヘッダーの「Content-Type」を正確に取得できない場合があるのです。
複数のライブラリで試しましたが、すべて同じように中途半端にしか取得できません。
したがって、上記の1583件すべてが「Content-Type」未設定というわけではありません。
中には、以下のように本当に文字コードを設定していないケースもあります。
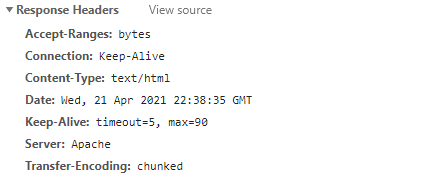
よって、ここの結果はその程度の認識で見てください。
あと、目についたのは以下。
- “EUC-JP”
- SHIFT SHIFT_JIS
- SHIFT_JS
HTTPヘッダーは、基本的にはユーザーには見えません。
だからと言って、少し酷すぎます。
調査結果『meta要素の「charset属性」』
meta要素の「charset属性」の集計結果は、以下。

文字コード比率の確認は、こっちの方がいいみたいです。
ほとんどのサイトでmeta要素の「charset属性」を設定しています。
そして、約94%のサイトが文字コードにUTF-8を採用しています。
UTF-8の普及度も、やっとここまで来たのですね。
でも、まだ残り6%はUTF-8ではないとも言えます。
内容を見ていくと、一つスゴイ文字コードがありますね。
以下のように実際に記述されています。

でも、このサイトでは実害がありません。
HTTPヘッダーの「Content-Type」でUTF-8を設定しています。
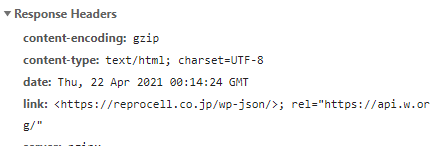
それでも、チグハグな印象をWebサイトに対して抱いてしまいます。
WordPressで構築しているのに、なぜこのようになるのか不思議です。
調査結果『バイト文字列の「推定文字コード」』
バイト文字列の「推定文字コード」の集計結果は、以下。
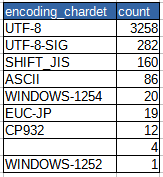
あくまで推定なので、本当のところはわかりません。
本来、この文字コードに出番はありません。
ただし、HTTPヘッダーとmeta要素で文字コードの指定ナシなら・・・
出番があります。
文字コードの推定に利用したchardetは、FireFoxと同じレベルのモノです。
よって、その精度をある程度は信用できます。
では、ブラウザが文字コードを推定するシーンが実際あるのでしょうか?
つまり、HTTPヘッダーとmeta要素で文字コードの指定ナシという状況です。
調べてみると、2社存在していました。
SSL対応していない時点で、個人的には心配してしまいます。

ASCIIと推定されたサイトをFireFoxで確認します。
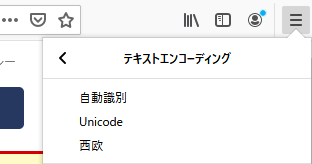
特定できていないようです。
言語に関しても、何語か特定できていませんでした。
CP932のサイトは、言語だけは以下のように特定できていました。

ちなみに、文字コードがUTF-8のサイトは以下のようになります。
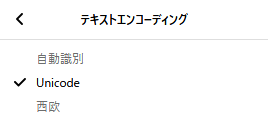
そして、Unicodeが選択されている場合、言語特定は行われません。

Unicode扱いなら、日本語でも英語でも関係ないですからね。
調査の振り返り
「思ったよりUTF-8対応のサイトが増えていた」
これが、率直な感想になります。
この調査結果は、これはこれでOKな結果です。
ただ、その結果と同時に残念な事実も判明しました。
いい加減なサイトが多いということです。
例えば、以下のサイトです。
株式会社クエスト
https://www.quest.co.jp/
HTTPヘッダー
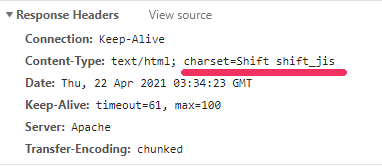
meta要素

意味がわかりますか?
文字コードが、それぞれで異なるのです。
それも「SHIFT SHIFT_JIS」という意味不明な値が設定されています。
とりあえず、文字化けせずにWebサイトは表示されています。
今のブラウザは賢いから、こういう矛盾もクリアするのでしょう。
でも、このような基本的なミスに気づけないというデメリットがあります。
さて、こんな初歩的なミスをしている株式会社クエストはどんな会社だと思いますか?
なんと、システム会社ではありませんか!?
辛辣な意見になりますが、敢えて書きます。
上場企業である以上は、批判も甘受すべきです。
(※市場からお金を集めている社会的責任がある)
こんな初歩のミスを放置している会社の商品・サービスを信用できますか?
私は、できません。
確かに、上記のミスは目には見えません。
でも、システムは目に見えない部分がほとんどです。
「ユーザーから目に見えないから、適当な仕事をしてもいい」
上記のミスを放置していることは、このように感じてしまうのです。
(気づけない体制であることもミスに含みます)
私は、プログラマーとしてはその逆の考えで仕事をしてきました。
ユーザーから目に見えないからこそ、丁寧な仕事をするという考えです。
そう考えないと、甘えて適当な仕事をしてしまいます。
ちょっと話がそれてしまいました。
言いたいことは、上場企業であっても酷くて残念なサイトが多いということです。
今は、Webサイトで会社を判断する人も多いと思います。
私がそれらの会社の株主なら、酷いWebサイトによる機会損失が気になります。
いや、そもそもそのような企業には投資をしませんね。

