
近年、スマートフォンやウェブアプリケーションにおいて、音声入力機能が広く使われるようになってきました。
しかし、多くのデバイスに搭載されている音声入力機能は、以下のような課題を抱えています。
- 認識精度が低い
- ユーザーにとって使いにくいインターフェース
- 限られた言語やドメインでしか使用できない
これらの課題により、ユーザーは音声入力機能を十分に活用できていないのが現状です。
Whisperを用いた高品質な音声入力
上記の課題を解決するために、「Whisper」を利用した音声入力機能の実装が有効です。

Whisperは、高い認識精度と多言語対応を特徴とする、最先端の音声認識モデルです。
しかし、Whisperを実際のアプリケーションに導入する際には、以下のような課題があります。
- モデルのサイズが大きく、メモリ消費量が多い
- GPUが必要となり、導入コストが高い
そこで、本記事では、これらの課題を解決するために、「Faster Whisper」を用いた音声入力機能の実装方法を紹介します。
Faster Whisperとは
Faster Whisperは、Whisperモデルを最適化し、CPUのみで高速に音声認識を行うことができるライブラリです。

主な特徴は以下の通りです。
- CPUのみで動作するため、導入コストが低い
- メモリ消費量が少なく、効率的な処理が可能
- Whisperと同等の認識精度を維持
Faster Whisperを利用することで、高品質な音声入力機能を、より手軽に実装することができます。
音声入力機能のアーキテクチャ
音声入力機能を実装するためのアーキテクチャは、主にクライアント側とサーバー側の2つの部分で構成されます。
クライアント側
クライアント側は、ユーザーが音声を入力するためのインターフェースを提供します。
主な役割は以下の通りです。
- マイクアイコンをクリックすると、音声の録音を開始する
- 録音が停止されると、録音された音声データをサーバー側に送信する
- サーバー側から返された音声認識結果を受け取り、テキスト入力要素に追加する
クライアント側は、HTML、CSS、JavaScriptを使用して実装されます。
サーバー側
サーバー側は、クライアント側から送信された音声データを受け取り、音声認識を行います。
主な役割は以下の通りです。
- クライアント側から送信された音声データを受け取る
- 受け取った音声データを一時的なファイルとして保存する
- 音声認識モデル(Faster Whisper)を使用して、音声をテキストに変換する
- 変換されたテキストをクライアント側に返す
サーバー側は、FastAPIを使用して実装されます。
API開発には、FastAPIが便利です。

通信
クライアント側とサーバー側は、HTTPを使用して通信を行います。
クライアント側は、録音された音声データをFormDataに追加し、POSTリクエストとしてサーバー側に送信します。
サーバー側は、音声認識結果をJSONフォーマットでクライアント側に返します。
以下は、クライアント側とサーバー側の通信の流れを示す図です。
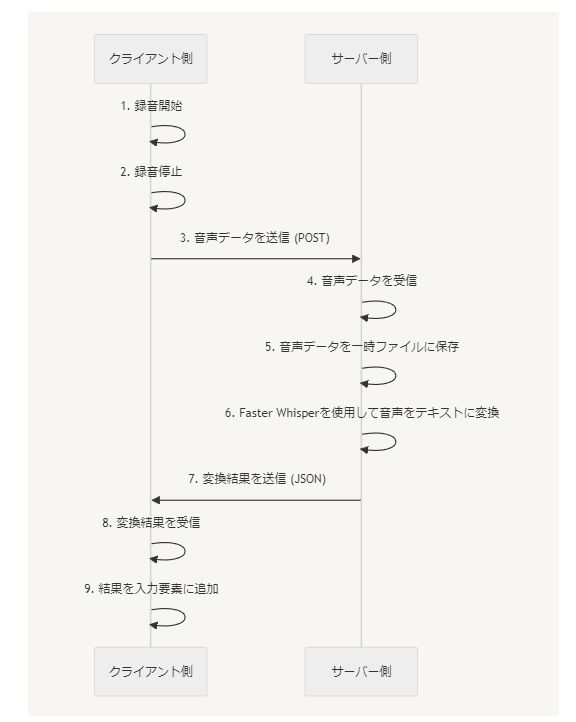
Mermaid記法
sequenceDiagram
participant Client as クライアント側
participant Server as サーバー側
Client->>Client: 1. 録音開始
Client->>Client: 2. 録音停止
Client->>Server: 3. 音声データを送信 (POST)
Server->>Server: 4. 音声データを受信
Server->>Server: 5. 音声データを一時ファイルに保存
Server->>Server: 6. Faster Whisperを使用して音声をテキストに変換
Server->>Client: 7. 変換結果を送信 (JSON)
Client->>Client: 8. 変換結果を受信
Client->>Client: 9. 結果を入力要素に追加
コード例
クライアント側
index.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>音声入力補助</title>
</head>
<body>
<div class="input-container">
<div class="input-wrapper">
<input type="text" id="textInput">
<i class="fas fa-microphone microphone-icon"></i>
</div>
</div>
<div class="input-container">
<div class="input-wrapper">
<textarea id="textareaInput" rows="5"></textarea>
<i class="fas fa-microphone microphone-icon"></i>
</div>
</div>
<script src="app.js" defer></script>
</body>
</html>
app.js
class AudioRecorder {
constructor(selector, apiUrl, cssUrl = 'https://example.com/styles.css', faUrl = 'https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css') {
this.selector = selector;
this.apiUrl = apiUrl;
this.cssUrl = cssUrl;
this.faUrl = faUrl;
this.loadStylesheet(this.cssUrl);
this.loadStylesheet(this.faUrl);
this.initialize();
}
loadStylesheet(url) {
const link = document.createElement('link');
link.href = url;
link.type = 'text/css';
link.rel = 'stylesheet';
document.head.appendChild(link);
}
// ... (その他のメソッドは省略) ...
}
new AudioRecorder('.microphone-icon', 'https://api.example.com/transcribe-audio/');
styles.css
.input-container {
display: flex;
align-items: center;
margin-bottom: 20px;
}
.input-wrapper input,
.input-wrapper textarea {
flex: 1;
padding: 10px;
font-size: 16px;
box-sizing: border-box;
}
.microphone-icon {
margin-left: 10px;
font-size: 20px;
cursor: pointer;
}
.recording {
color: red;
}
.processing {
color: orange;
}
サーバー側
server.py
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import JSONResponse
from faster_whisper import WhisperModel
import os
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["https://example.com"], # 許可するオリジンを指定
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# Whisperモデルの初期化
model_size = "small"
model = WhisperModel(model_size, device="cpu", compute_type="int8")
# 一時ファイルを保存するディレクトリのパス
tmp_dir = "./tmp/"
os.makedirs(tmp_dir, exist_ok=True) # ディレクトリが存在しない場合に作成
@app.post("/transcribe-audio/")
async def transcribe_audio(file: UploadFile = File(...)):
# 受け取ったファイルを一時的に指定のディレクトリに保存
temp_file_path = os.path.join(tmp_dir, f"temp_{file.filename}")
with open(temp_file_path, "wb") as buffer:
buffer.write(await file.read())
# Whisperモデルを使って音声をテキストに変換
segments, info = model.transcribe(temp_file_path, beam_size=5)
# テキスト変換結果の抽出
transcription = " ".join([seg.text for seg in segments])
# 一時ファイルの削除
os.remove(temp_file_path)
上記のコード例は、クライアント側とサーバー側のファイルを示しています。
クライアント側では、index.htmlファイルにマイクアイコンを表示するためのHTMLが記述されています。
app.jsファイルでは、AudioRecorderクラスが定義され、以下の機能を含みます。
- マイクアイコンのクリックイベントの処理
- 録音の開始・停止
- サーバーへの音声データの送信
JavaScriptでクラスを利用する方法は、以下の記事で説明しています。

styles.cssファイルには、マイクアイコンやテキスト入力要素のスタイルが定義されています。
このファイルは、jsから動的に読み込むようにしています。
サーバー側では、server.pyファイルにFastAPIを使用したAPIエンドポイントが定義されています。
/transcribe-audio/エンドポイントでは、以下の処理が行われます。
- クライアントから送信された音声データの受け取り
- Faster Whisperモデルを使用した音声からのテキスト化
- クライアントへの変換結果の返答
重要な点として、クライアント側のコードでは、APIエンドポイントのURLにHTTPSを使用しています。
https://api.example.com/transcribe-audio/
FastAPIで開発したアプリケーションのSSL化については、次の記事で説明しています。

また、マイクへのアクセスを行うには、ウェブサイト自体もSSL/TLSで暗号化されている必要があります。
まとめ
本記事では、高品質な音声入力機能をウェブアプリケーションに実装する方法について説明しました。
音声入力の現状と課題を述べ、それらを解決するためにFaster Whisperを用いた実装方法を提案しました。
提案したアーキテクチャは、クライアント側とサーバー側に分かれており、それぞれの役割と通信方法について説明しました。
また、実際のコード例を用いて、具体的な実装方法を示しました。
Faster Whisperを利用することで、高い認識精度を維持しつつ、導入コストを抑えた音声入力機能を実装することができます。
本記事で紹介した方法を参考に、自分のアプリケーションに音声入力機能を追加してみてください。
なお、セキュリティ上の理由から、音声入力機能のデモ画面は一般公開しておりません。
デモ画面の利用をご希望の方は、問い合わせフォームからご連絡ください。
個別にデモ画面の利用方法についてご案内いたします。


