メルカリをWebスクレイピングしていきます。
今回は、商品一覧ページのスクレイピングです。
商品一覧ページをスクレイピングすることにより、商品IDを抽出できます。
商品IDのリストが用意できれば、スクレイピングの8割は完了です。
その意味でも、今回はメルカリをスクレイピングする上での山場とも言えます。
本記事の内容
- ここまでの流れ【メルカリのスクレイピング】
- 商品一覧ページのスクレイピング仕様
- 商品一覧ページから商品IDを抽出する
それでは、上記に沿って解説していきます。
ここまでの流れ【メルカリのスクレイピング】
今回は、商品一覧ページのスクレイピングがメインです。
ただ、これはメルカリのスクレイピングにおいては一部分に過ぎません。
この記事は、メルカリのスクレイピングにおいては第3弾となります。
過去の同シリーズを挙げておきます。
第1弾

第2弾

段階を踏んで、メルカリをスクレイピングする方法について解説しています。
そのため、スクレイピングを学ぶ上でも役に立つ内容となっています。
また、第1弾の記事にある「【必須】Webスクレイピングに関する考え方」は必ず読んでください。
そこに書いてある内容を知らないと、犯罪者になってしまう可能性もゼロではありません。
スクレイピングとは、それぐらいの危機意識(リテラシー)を持って臨むべき技術とも言えます。
上記の第2弾までの内容により、メルカリにおける大カテゴリーのIDを抽出できています。
このIDが取得できていれば、商品一覧ページのURLが作成可能となります。
では、そのあたりの仕様から説明していきます。
商品一覧ページのスクレイピング仕様
商品一覧ページをスクレイピングする仕様について説明していきます。
大きく分けて、以下の3つ。
- 商品一覧ページのURL作成
- 改ページ対応
- 商品IDの抽出
下記で説明します。
商品一覧ページのURL作成
第2弾のサンプルコードを実行すると、以下の結果を得ることができました。
['1', '2', '3', '4', '5', '1328', '6', '7', '8', '9', '1027', '1318', '10']
これらは、大カテゴリーのID一覧です。
このカテゴリーIDがあれば、メルカリにおける商品一覧ページのURLを作成できます。
とりあえず、以下の二つをピックアップ。
レディースの商品一覧
https://www.mercari.com/jp/category/1
おもちゃ・ホビー・グッズの商品一覧
https://www.mercari.com/jp/category/1328
見ただけで、わかりますよね。
「https://www.mercari.com/jp/category/●」
「●」の部分に取得したカテゴリーIDを設定するだけです。
メルカリの場合は、大カテゴリーの数が13個とそれほど多くありません。
だから、商品一覧ページのURLを自動で作成することがあまり効果的には見えません。
しかし、カテゴリー数がもっと多くなってくると事情が異なってきます。
改ページ対応
メルカリの商品一覧ページでは、最大120個の商品が表示されています。
続きのデータを見る場合には、次のページへ遷移する必要があります。
メルカリは、この点ではスクレイピングがやりやすい部類に入ります。
実際にURLを持つページが存在するからです。
対して、TwitterやInstagramなどはそうではありません。
TwitterやInstagramでは、同一ページ内でスクロールする度にコンテンツが表示されます。
これがスクレイピングする上では鬼門なのです。
と言っても、対応方法はあります。
次の記事では、Seleniumを使ってスクロールを自動で行っています。
「スクロール→コンテンツ取得」を繰り返すイメージです。



上記で紹介しているサイトと比べると、メルカリでの改ページ対応は簡単です。
しかし、簡単と言えどもそれなりに複雑な対応を行います。
「https://www.mercari.com/jp/category/1354?page=2」
上記URLを作成して、遷移する方法は一般的です。
今回は、改ページ用のURLを作成する方法は採用しません。
では、どうするのか?
商品一覧ページにある次のボタン(リンク)をクリックします。
もちろん、この場合もプログラム(Selenium)によりクリックして遷移します。
これは、念には念を入れての対応となります。
Instagramでは、URLを指定して遷移するとロボット(プログラム)だと判定されることがあります。
つまり、画面のリンクやボタンを押して遷移しないと不正だと判定されることがあるのです。
メルカリがそこまでのスクレイピング対策をしているかどうかはわかりません。
ただ、事前に打てる手は打っておくというスタンスです。
商品IDの抽出
調査したところ、現時点(2021年2月5日)では特にクセのあるページではありません。
第2弾で説明したカテゴリー一覧ページのような嫌がらせはしてきません。
しかし、いつ同じようなスクレイピング対策をしてくるかは、わかりません。
もしかしたら、日々タグ要素のclass名が変更する可能性も捨てきれません。
さらには、IP単位でclass名を変更している可能性もゼロではありません。
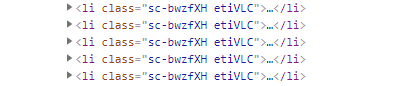
上記は、商品一覧を形成するタグの一部です。
このclass名の値が、不変かどうかが疑わしいということですね。
そのため、安全策を取ってclass名に依存する形のスクレイピングは避けておきます。
商品一覧ページから商品IDを抽出する
商品一覧ページから商品IDを抽出するコードは、以下。
現時点(2021年2月5日)では元気に動いています。
サンプルコード
import bs4
import traceback
import re
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
# ドライバーのフルパス
CHROMEDRIVER = "chromedriver.exeのフルパス"
# 改ページ(最大)
PAGE_MAX = 3
# 遷移間隔(秒)
INTERVAL_TIME = 3
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
# options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
page_source = driver.page_source
return page_source
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
# print(soup)
try:
info = []
grid = soup.find(attrs={"data-test": "grid-layout"})
if grid:
elems = grid.find_all("li")
for elem in elems:
a_tag = elem.find("a")
if a_tag:
href = a_tag.attrs['href']
match = re.findall("\/jp\/items\/(.*)\/", href)
if len(match) > 0:
item_id = match[0]
info.append(item_id)
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# 次のページへ遷移
def next_btn_click(driver):
try:
# 次へボタン
elem_btn = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.XPATH, '//a[@data-test="pagination-control-right-single-arrow"]'))
)
actions = ActionChains(driver)
actions.move_to_element(elem_btn)
actions.click(elem_btn)
actions.perform()
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
return True
except Exception as e:
print("Exception\n" + traceback.format_exc())
return False
if __name__ == "__main__":
# 対象ページURL
page = "https://www.mercari.com/jp/category/1"
# ブラウザのdriver取得
driver = get_driver()
# ページのソース取得
source = get_source_from_page(driver, page)
result_flg = True
# ページカウンター制御
page_counter = 0
while result_flg:
page_counter = page_counter + 1
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存
print(data)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 改ページ処理
result_flg = next_btn_click(driver)
source = driver.page_source
# 閉じる
driver.quit()
大きくは、第2弾のプログラムとは変わっていません。
ただ、改ページ処理の部分が第2弾ではありませんでした。
まずは、起点となるページへアクセス。
本当は、この部分からfor文で回そうと思いました。
# 対象ページURL
page = "https://www.mercari.com/jp/category/1"
ループは、13個取得できたカテゴリーID分だけ。
しかし、その部分まで説明すると肝心のスクレイピングの説明がブレてしまいます。
どちらかと言うと、それはPythonプログラムの説明になってしまいます。
では、必要と思われる箇所を説明しておきます。
今回のプログラムでは以下を設定変更可能としています。
# ドライバーのフルパス CHROMEDRIVER = "chromedriver.exeのフルパス" # 改ページ(最大) PAGE_MAX = 3 # 遷移間隔(秒) INTERVAL_TIME = 3
CHROMEDRIVERに関しては、第1弾・第2弾の記事をご覧ください。
PAGE_MAXとINTERVAL_TIMEに関しては、説明しておきます。
PAGE_MAX
スクレイピングするページの最大数です。
現状では、「3」を設定しています。
3ページだけスクレイピングするということです。
実際に対象カテゴリーのデータをすべてスクレイピングするなら、「99999」などの大きい数字にします。
もしくは、以下のコード部分を除去します。
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
この制御は、テスト稼働のために設けています。
いきなり動かして、対象カテゴリーの全ページにアクセスするのは怖すぎます。
INTERVAL_TIME
コメントの通りに、遷移の間隔時間の指定となります。
ページ間の遷移に3秒を設けておけば、とりあえずは安全でしょう。
コードは、以下の箇所になります。
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
人間が手で動かす場合でも、3秒は遅いのではないでしょうかね。
この部分は、主観よるところが大きいので各自に判断を任せます。
今回のメルカリであれば、1ページに120個の商品が表示されています。
仮に3秒に1アクセスだとしたら、1分間に20アクセス可能です。
結果的には、1分間に2400個の商品IDを抽出できます。
そう考えると、3秒でも十分かもしれませんね。
なお、私が実際にスクレイピングする際は1秒指定にします。
1秒の間隔を設けて、アクセス禁止にされたことは過去にありません。
世の中の酷いプログラムなんて、1ミリ秒に1回とか普通にあり得ます。
つまり、時間間隔を一切設けないということです。
このような場合は、対象サイトからIP単位でアクセス禁止のペナルティを受けてしまいます。
実行結果
サンプルコードを実行した結果は、以下。
最初と最後だけを表示。
['m50918799282', 'm73773136162', 'm38044269702', 'm64368393092', 'm62524801137', 'm53130284232', ~ 'm86730511132', 'm99189037585', 'm74713790806', 'm74530402541', 'm85223463414', 'm78013511733']
レディースに登録されている商品IDを360個(120個×3P)抽出できました。
簡単ですね。
まとめ
基本的には、「商品一覧ページのスクレイピング仕様」をベースにプログラミングしています。
その内容とコード上のコメントをよく見てください。
あと説明が必要なのは、下記のコーディング部分ですね。
# データ保存
print(data)
スクレイピングは、いつプログラムが停止するかはわかりません。
それこそアクセス禁止を食らう可能性もあるわけですから。
そのような場合に備えて、1ページ毎にスクレイピングしたデータを保存しておきましょう。
そのタイミングは、上記で示した部分です。
各種ファイルに書き込んでいくのも一つの選択肢です。
個人的には、MongoDBに登録するのがおススメです。
MongoDBなら、jsonデータのままでも登録できます。
それに、キーの持ち方次第で二重登録も簡単に防げます。
次のようなカラムを持つテーブルを用意する感じです。
- カテゴリーID
- 商品ID
上記の複合キーにすれば、ユニーク制約を付けることが可能です。
もしくは、単純に商品IDにキーを張ってもいいですね。
WindowsへのMongoDBのインストールに関しては、次の記事で説明しています。

LinuxへのMongoDBのインストールに関しては、コマンドだけで一撃です。
もちろん、MariaDB(MySQL)の利用でも全然OKです。


