
無料の検索順位チェックツールと言えば?
GRCと答える人が多いです。
でも、私はSerposcopeと回答します。
どう考えてもSerposcopeに軍配が上がります。
GRCは、正直言って情弱用です。
みなさん、もっと冷静に考えてください。
「なぜ、令和の時代になってWebで結果を共有できないの?」
「なぜ、PCをつけたままじゃないと動かないの?」
「なぜ、無料だと全然使えないの?」
このように思いませんか?
ネットの多くの記事でGRCを勧めるから使っていませんか?
もしくは、「Serposcopeは使えない」という言葉を鵜呑みにしていませんか?
もし、そうなら、あなたは情弱です。
ただし、今は情弱であってもいいです。
この記事を読んで、情強になってください。
私は、上記の「なぜ」を自問して、Serposcopeにたどり着きました。
しかし、Serposcopeは使う人を選びます。
情弱が表面だけで使うと、「 Serposcope 使えない」となります。
Serposcopeは、本当はとても「できる子」なのです。
そして、 SerposcopeがGRCより格下に見られているこの状況が許せません。
そこで、Serposcopeを「できる子」にするためのノウハウをまとめました。
ベースは、Serposcopeの公式にあるFAQです。
このFAQをベースにノウハウをまとめています。
本記事の内容
- Serposcopeのデフォルトポートは何ですか?
- SQLで組み込みデータベースにアクセス/ダンプするには?
- 管理者パスワードをリセットするには?
- 実行ログはどこにありますか?
- Serposcopeが遅い場合、速くする方法は?
- 何個のキーワードをチェックできるのか?
- SerposcopeでMySQLを使うには?
- プロキシのブラックリスト/排除を回避するには?
- キャプチャの処理方法は?
- スコア(SCORE)はどのように基準でつけられているのか?
- Serposcopeをインストールしたが、何も起こらない
- Error java.net.BindException: address already in use
- Error java.io.FileNotFoundException: serposcope-2.0.0.jar (No such file or directory)
- Exception java.lang.UnsupportedClassVersionError : Unsupported major.minor version 52.0
それでは、情強への第一歩となるノウハウをご覧ください。
Serposcopeのデフォルトポートは何ですか?
Serposcopeは、7134番ポートで動作するウェブサービスを作成します。
ブラウザを使用して、次のURLにアクセスします。
http://127.0.0.1:7134/
ただし、これはローカルマシンのPCにインストールした場合です。
Linuxで構築したサーバーにインストールした場合は、IPの部分が異なります。
例えば、IPアドレスが123.567.890.123のサーバーがあったとします。
そのサーバににSerposcopeをインストールした場合は、以下のURLになります。
http://123.567.890.123:7134/
私は、VPSサーバーにSerposcopeをインストールしています。
そのため、自宅以外からでもSerposcopeにアクセス可能です。
ちなみに、VPSはさくらインターネット株式会社を利用しています。
さくらのVPSはサービス開始時から利用しています。
他のVPSもいろいろと試しましたが、やはりさくらのVPSが一番ですね。
SQLで組み込みデータベースにアクセス/ダンプするには?
データベースのバックアップとリストアは、管理パネルから行うことができます。
Serposcopeは、初期状態では「H2 Database」を使用しています。
http://www.h2database.com/html/main.html
また、MySQLを使用することもできます。
H2 Database以外のデータベースを利用する方法は、後で説明します。
データベースは、datadirに格納されています。
datadirの場所は、Serposcopeの設定ファイル(serposcope.conf)で確認できます。
この部分は、次の記事の「Serposcopeのデータディレクトリと重要なファイル」をご覧ください。

バックアップは、datadirに格納されている「db.mv.db」をコピーすることで可能です。
その場合は、Serposcopeを停止してください。
管理者パスワードをリセットするには?
パスワードを紛失した場合は、「password-reset.txt」というファイルを作成する必要があります。
そのファイルを作成する場所は、OSによって異なります。
Windows
通常は、「C:\ProgramData\serposcope\password-reset.txt」となります。
インストール場所が異なるなら、環境変数%ProgramData%を確認してください。
%ProgramData%により、「C:\ProgramData\serposcope」が判明します。
Debian/Ubuntu
これらのOSの場合は、以下です。
/var/lib/serposcope/password-reset.txt
Mac、CentOS、その他のUnixディストリビューション
ユーザー「bob」がSerposcopeを起動した場合は、以下のどちらかとなります。
- /Users/bob/serposcope/password-reset.txt
- /home/bob/serposcope/password-reset.txt
実行ログはどこにありますか?
Serposcopeの管理画面 > logs からアクセスできます。
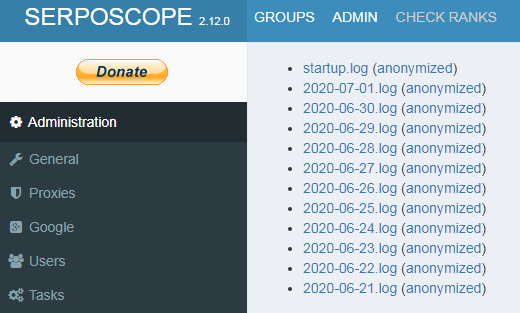
ログが保存される場所は、Serposcopeの設定ファイル(serposcope.conf)で確認可能です。
Debian/Ubuntuであれば、以下のように記述されています。
# log path serposcope.logdir=/var/log/serposcope
/var/log/serposcopeを確認します。
# ls -l total 224 -rw-r--r-- 1 serposcope nogroup 15395 Jun 21 20:28 2020-06-21.log -rw-r--r-- 1 serposcope nogroup 16451 Jun 22 20:28 2020-06-22.log -rw-r--r-- 1 serposcope nogroup 15936 Jun 23 20:28 2020-06-23.log -rw-r--r-- 1 serposcope nogroup 17512 Jun 24 22:01 2020-06-24.log -rw-r--r-- 1 serposcope nogroup 16114 Jun 25 20:28 2020-06-25.log -rw-r--r-- 1 serposcope nogroup 18286 Jun 26 20:28 2020-06-26.log -rw-r--r-- 1 serposcope nogroup 17034 Jun 27 20:28 2020-06-27.log -rw-r--r-- 1 serposcope nogroup 16812 Jun 28 20:28 2020-06-28.log -rw-r--r-- 1 serposcope nogroup 18591 Jun 29 20:28 2020-06-29.log -rw-r--r-- 1 serposcope nogroup 18033 Jun 30 20:29 2020-06-30.log -rw-r--r-- 1 serposcope nogroup 18354 Jul 1 08:29 2020-07-01.log -rw-r--r-- 1 serposcope nogroup 1153 May 30 14:25 startup.log
管理画面で見えているのと同じファイルが、存在していることを確認できます。
なお、ログは最大で11日分が保存されています。
明日になれば、「2020-07-01.log」が作成されます。
そして、「2020-06-21.log」は消えるということです。
Serposcopeが遅い場合、速くする方法は?
管理画面で行います。
大きく以下の4つの方法があります。
- 「Pause」を減らす/無効にする
- 「Number of pages」を小さくして、「Results per page」を大きくする
- プロキシ設定でプロキシを追加する
- マルチスレッドを有効にするために「Maximum threads」を指定する
Pause」を減らす/無効にする
「Pause」は、Googleへの各リクエストの間の秒単位での一時停止の範囲の設定です。
一時停止は最小値と最大値の間でランダムに設定されます。
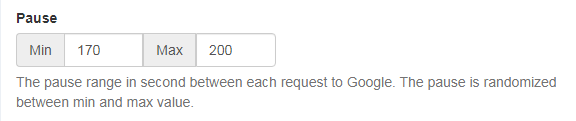
上記の設定であれば、一時停止の時間が170秒~200秒(この間でランダムに決まる)ということです。
これを減らせば、Serposcopeが速くなるのは当たり前ですね。
ただ、そうするとGoogleにボット扱いされてしまう可能性が高くなります。
「pause」の値とその影響について、以下のようにまとめられます。
| pause | 速度 | ボット判定の可能性 |
| 大きい | 遅い | 低い |
| 小さい | 速い | 高い |
「Number of pages」を小さくして、「Results per page」を大きくする
「Number of pages」は、検索ごとに取得するページ数です。
1回の検索での結果の総数は、「ページ数」×「1ページあたりの結果」になります。
「Results per page」は、1ページあたりの検索結果の数です。
1ページあたりの検索結果は、10~100件から選択します。
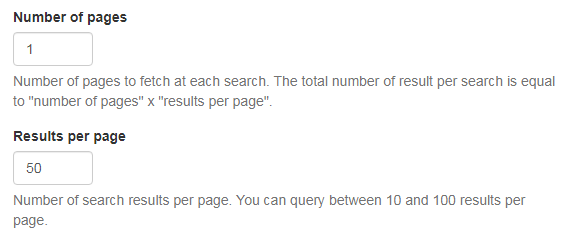
上記の設定では、1つのキーワードにつき50位までを取得することになります。
以上より、Serposcopeを速くする設定は次のようになります。
100件取得するのに時間がかかっているケースです。
| 変更前 | ⇒ | 変更後 |
| 2 | Number of pages | 1 |
| 50 | Results per page | 100 |
プロキシ設定でプロキシを追加する
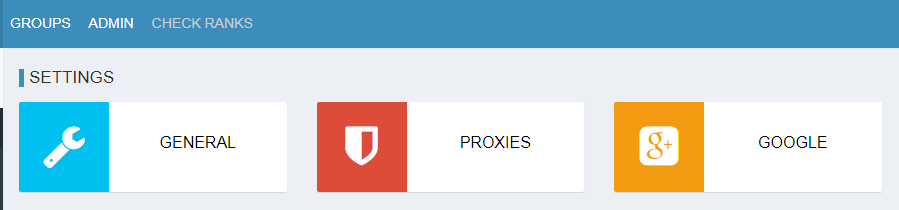
「PROXIES」から、プロキシを追加します。
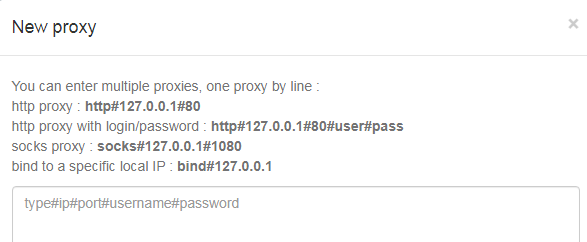
上記の形式で登録となります。
私自身は、プロキシは追加していません。
当初は、無料のプロキシを登録したことがあります。
しかし、無料のプロキシは不特定多数が利用しています。
そのため、Googleからボット扱いを受けていることがほとんどです。
つまり、無料のプロキシは使い物にならないということですね。
有償であれば、この機能も有効となるでしょう。
マルチスレッドを有効にするために「Maximum threads」を指定する
Maximum threadsは、スクレイピング時のGoogleへの並列接続数の最大値となります。
同じIPで並列にスクレイピングすることはありません。
つまり、プロキシを設定しないと「Maximum threads」に意味はありません。
そして、プロキシを5個追加したら、「Maximum threads」には「6」を設定する必要があるということです。
何個のキーワードをチェックできるのか?
特に制限はなく、10万キーワードでも問題のないことを検証済みです。
しかし、数千以上のキーワードをチェックする場合は注意が必要です。
H2 Databaseではなく、MySQLを利用する必要があります。
MySQLの利用する方法は、下記で説明しています。
SerposcopeでMySQLを使うには?
組み込みのデータベース(H2 Database)の代わりにMySQL を使うことが可能です。
Serposcopeの設定ファイル(serposcope.conf)でMySQLを利用するように設定します。
serposcope.db.url=jdbc:mysql://HOSTNAME/DATBASE?user=USER&password=PASS&allowMultiQueries=true
Serposcopeは自動的にテーブルを作成し、データベースに入力します。
管理パネルからのバックアップは、H2とMySQLの両方に対応しています。
これらのバックアップを利用して、MySQLからH2への移行や、その逆も可能です。
データベースは事前に作成しておきます。
この点は、WordPressも同じですね。
キーワードが増えてきて、Serposcopeが遅くなってきた場合に有効な手段となるでしょう。
それまでのデータも移行できるようですので。
プロキシのブラックリスト/排除を回避するには?
Serposcopeは、以下の場合に一時的にプロキシを削除します。
- Googleからブラックリストに登録されている
- Googleがキャプチャを表示していてキャプチャサービスが設定されていない
この場合にできることは以下。
- キャプチャサービスを設定する
- 「Pause」を増やす
- プロキシを増やし、フェイルオーバーIPを増やす。
- 「Number of pages」を小さくして、「Results per page」を大きくする
キャプチャサービスを設定する
プロキシ以前にキャプチャサービスは必須です。
特に、VPSなどのサーバーにインストールして利用する場合は。
「Pause」を増やす
Serposcopeを意図的に遅くします。
「Pause」を増やすことにより、Serposcopeを遅くすることができます。
詳細は、上記「Serposcopeが遅い場合、速くする方法は?」で説明しています。
プロキシを増やし、フェイルオーバーIPを増やす
プロキシ数を増やします。
単純に量でカバーするという作戦ですね。
なお、フェイルオーバーとは、自動的に切り替えを行うという意味です。
そのため、切り替え候補が多ければ多いほど良いのは当然でしょう。
「Number of pages」を小さくして、「Results per page」を大きくする
検索の効率性を向上させます。
そのため、1ページあたりの検索数を増やすことが必要です。
詳細は、上記「Serposcopeが遅い場合、速くする方法は?」で説明しています。
キャプチャの処理方法は?
同じIPから、Googleに対して多くのリクエストをした場合にエラーが出ます。
ログには、「ERROR_CAPTCHA_NO_SOLVER」というメッセージが表示されています。
キャプチャを解決するために外部サービスを設定することができます。
- anti-captcha.com
- de-captcher.com
- deathbycaptcha.com
バージョン2.5.0からは、複数のサービスを同時に設定できるようになりました。
もしサービスが利用できなくなった場合、Serposcopeは自動的に別のプロバイダに切り替えます。
anti-captcha.com (Google captchas Recaptcha v2 / NoCaptchaに対応している唯一のプロバイダ)を含め、最低でも2つのプロバイダを設定することをお勧めします。
Serposcopeは近い将来、より多くのプロバイダを含める予定です。
上記で出てきた外部サービスに関しては、次の記事で詳しく解説しています。
結論として、Anti Captchaは必須です。
これはFAQにも記載されていますね。
また、以下の記事ではAnti Captchaと契約する方法を詳しく解説しています。

スコア(SCORE)はどのように基準でつけられているのか?
各ランク付けされたキーワードは、そのランクに関するスコアを増加させます。
最終的なスコアは、各キーワードのスコアの平均であり、スコアは1から100の間です。
rank #1 = 100 points rank #2 = 90 points rank #3 = 80 points rank #4-#5 = 70 points rank #6-#10 = 60 points rank #11-#20 = 40 points rank #21-#30 = 30 points rank #31-#50 = 20 points rank #51-#100 = 10 points rank #100+ = 5 points unranked = 0 points
実験的なものであり、変更される可能性があります。
Serposcopeでは、どんな提案も受け付けています。
Serposcopeをインストールしたが、何も起こらない
Serposcopeはポート7134で動作するWebサービスを作成します。
ブラウザを使用して、次のURLにアクセスします。
http://127.0.0.1:7134/
※VPSなどのサーバーにインストールしている場合は、適宜URLを変更
サービスにアクセスできない場合は、まずログフォルダにエラーメッセージがないかチェックしてください。
ログの場所は、「実行ログはどこにありますか?」をご覧ください。
チェックするログは、最新のログです。
最新のログは、2010-10-20.logという形式で現在の日で作成されています。
Windowsでは、最初のログがSerposcopeのdatadirのlogsフォルダにあることを確認してください。
そこには、commons-daemon.2010-10-20.logという名前の他のログがあります。
このログには、ほとんど情報がなく、Serposcopeのメインログではありません。
また、Serposcopeが以下の状態で全く起動しないことがあるかもしれません。
- Serposcopeにエラーメッセージがない
- ログにメッセージもない
この場合は、次のことが原因に考えられます。
- Javaがインストールされていない(Pathが通っていない)
- バージョンが1.8以上のJavaを利用していない
Error java.net.BindException: address already in use
このエラーが出る場合は、すでに7134 番ポートで待機しているソフトウェアがあります。
netstatコマンドを使ってソフトウェアの位置を特定してください。
serposcope.confでserposcope のデフォルトポートを変更することができます。
# listen port #serposcope.listenPort=
このエラーは、複数のSerposcopeインスタンスを一度に実行した場合にも発生する可能性があります。
Error java.io.FileNotFoundException: serposcope-2.0.0.jar (No such file or directory)
Serposcopeを実行中にserposcope.jarを削除するとこのエラーが発生します。
Exception java.lang.UnsupportedClassVersionError : Unsupported major.minor version 52.0
このエラーはJavaが最新でない場合に発生します。
Serposcopeには、バージョン1.8 以上のJavaが必要です。
Javaのバージョンを確認するには、次のコマンドを実行します。
admin@localhost:~$ java -version java version "1.8.0_66"

