
「AUTOMATIC1111版web UIの画像生成処理をもっと速くしたい」
「PyTorch 2.0用のxFormersは存在しないの?」
このような場合には、この記事の内容が参考になります。
この記事では、PyTorch 2.0で動くweb UIの高速化について解説しています。
本記事の内容
- PyTorch 2.0で動くweb UIの高速化
- 高速化の動作検証
それでは、上記に沿って解説していきます。
PyTorch 2.0で動くweb UIの高速化
2023年3月中旬にPyTorch 2.0がリリースされました。
PyTorch 2系は、1系に比べて高速化されたと言われています。
PyTorch 2.0のインストールについては、次の記事で解説しています。

「AUTOMATIC1111版web UIがPyTorch 2系でも動くのか?」
このことが、多くの方にとって気になることでしょう。
上記の記事では、そのことを検証しています。
結論としては、問題なく動きます。
PyTorch 2.0の特徴として、後方互換性がアピールされています。
そのアピール通り、web UIが動くことは確認済みです。
ただし、現時点でPyTorch 2.0用のxFormersが公開されていません。
web UIの高速化と言えば、xFormers抜きでは語れませんからね。

そのため、公開されるまで待とうと考えていました。
しかし、どうやらその必要はないと言えます。
なぜなら、PyTorch 2系で動くweb UIにはxFormersが不要だからです。
その代わりに、「–opt-sdp-attention」を指定します。
このオプションは、デフォルトで利用可能です。
つまり、別途インストールするモノはありません。
以上、PyTorch 2.0で動くweb UIの高速化について説明しました。
次は、高速化の動作検証を説明します。
高速化の動作検証
web UIの起動には、多くのオプションを指定できます。
その中でも、PyTorch 2系のみで指定できるのは以下となります。
--opt-sdp-attention enable scaled dot product cross-attention layer optimization; requires PyTorch 2.*
--opt-sdp-no-mem-attention
enable scaled dot product cross-attention layer optimization without memory efficient attention, makes image
generation deterministic; requires PyTorch 2.*
そこで、今回は次のパターンで速度検証を行ってみます。
- PyTorch 1系 + 「–xformers」
- PyTorch 2系 + 「–opt-sdp-attention」
- PyTorch 2系 + 「–opt-sdp-attention」 + 「–opt-sdp-no-mem-attention」
条件としては、embeddingsやLoRAなどを未インストールのweb UIとします。
そして、モデルやプロンプトなどは全く同じモノを利用します。
| Stable Diffusion checkpoint | deliberate_v2.safetensors |
| prompt | a car |
| Sampling method | DPM++ SDE Karras |
| Sampling steps | 20 |
| Width | 500 |
| Height | 500 |
| CFG Scale | 7 |
| Batch count | 10 |
| Batch size | 1 |
単発だと結果がブレるかもしれませんので、10回画像生成を行います。
| パターン | 10回の合計 |
| 1 | 200/200 [00:25<00:00, 7.71it/s] |
| 2 | 200/200 [00:25<00:00, 7.81it/s] |
| 3 | 200/200 [00:25<00:00, 7.85it/s] |
この結果を見ると、「–opt-sdp-attention」を用いればxFormersは不要だと確認できます。
そして、「–opt-sdp-no-mem-attention」を併用すれば速度がUPするとわかります。
さらに、処理が重くなればその結果は変わってきます。
画像のサイズを2倍にする処理を加えます。
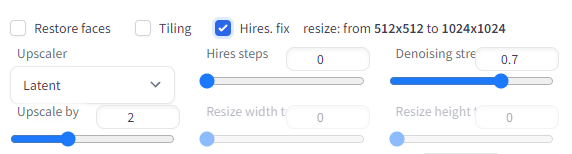
その結果は、以下。
| パターン | 10回の合計 |
| 1 | 400/400 [02:53<00:00, 2.31it/s] |
| 2 | 400/400 [02:35<00:00, 2.58it/s] |
| 3 | 400/400 [02:24<00:00, 2.76it/s] |
処理を重くすると、結構な差となります。
この結果を踏まえて、PyTorch 2.0で動くweb UIは次のコマンドで起動するようにします。
python launch.py --no-half-vae --opt-sdp-attention --opt-sdp-no-mem-attention --opt-channelslast
「–opt-channelslast」は、環境によって効果が異なると言われています。
速くなる場合もあれば、遅くなる場合もあると言われています。
ちなみに、上記コマンドで検証した結果は以下となります。
| 10回の合計 512 x 512 | 200/200 [00:24<00:00, 8.03it/s] |
| 10回の合計 2倍 resize: from 512×512 to 1024×1024 | 400/400 [02:26<00:00, 2.72it/s] |
なかなか面白い結果となっています。
効果の有無は、環境と言うより条件によって異なると言った方が適切かもしれません。
まだまだ、起動オプションによって処理速度は改善できそうです。
ただ、オプションの数が多すぎて全部検証するのは大変でしょうけどね・・・
```
-h, --help show this help message and exit
--data-dir DATA_DIR base path where all user data is stored
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of stable diffusion model; if specified, this checkpoint will be added to the list of
checkpoints and loaded
--ckpt-dir CKPT_DIR Path to directory with stable diffusion checkpoints
--vae-dir VAE_DIR Path to directory with VAE files
--gfpgan-dir GFPGAN_DIR
GFPGAN directory
--gfpgan-model GFPGAN_MODEL
GFPGAN model file name
--no-half do not switch the model to 16-bit floats
--no-half-vae do not switch the VAE model to 16-bit floats
--no-progressbar-hiding
do not hide progressbar in gradio UI (we hide it because it slows down ML if you have hardware acceleration in
browser)
--max-batch-count MAX_BATCH_COUNT
maximum batch count value for the UI
--embeddings-dir EMBEDDINGS_DIR
embeddings directory for textual inversion (default: embeddings)
--textual-inversion-templates-dir TEXTUAL_INVERSION_TEMPLATES_DIR
directory with textual inversion templates
--hypernetwork-dir HYPERNETWORK_DIR
hypernetwork directory
--localizations-dir LOCALIZATIONS_DIR
localizations directory
--allow-code allow custom script execution from webui
--medvram enable stable diffusion model optimizations for sacrificing a little speed for low VRM usage
--lowvram enable stable diffusion model optimizations for sacrificing a lot of speed for very low VRM usage
--lowram load stable diffusion checkpoint weights to VRAM instead of RAM
--always-batch-cond-uncond
disables cond/uncond batching that is enabled to save memory with --medvram or --lowvram
--unload-gfpgan does not do anything.
--precision {full,autocast}
evaluate at this precision
--upcast-sampling upcast sampling. No effect with --no-half. Usually produces similar results to --no-half with better
performance while using less memory.
--share use share=True for gradio and make the UI accessible through their site
--ngrok NGROK ngrok authtoken, alternative to gradio --share
--ngrok-region NGROK_REGION
The region in which ngrok should start.
--enable-insecure-extension-access
enable extensions tab regardless of other options
--codeformer-models-path CODEFORMER_MODELS_PATH
Path to directory with codeformer model file(s).
--gfpgan-models-path GFPGAN_MODELS_PATH
Path to directory with GFPGAN model file(s).
--esrgan-models-path ESRGAN_MODELS_PATH
Path to directory with ESRGAN model file(s).
--bsrgan-models-path BSRGAN_MODELS_PATH
Path to directory with BSRGAN model file(s).
--realesrgan-models-path REALESRGAN_MODELS_PATH
Path to directory with RealESRGAN model file(s).
--clip-models-path CLIP_MODELS_PATH
Path to directory with CLIP model file(s).
--xformers enable xformers for cross attention layers
--force-enable-xformers
enable xformers for cross attention layers regardless of whether the checking code thinks you can run it; do
not make bug reports if this fails to work
--xformers-flash-attention
enable xformers with Flash Attention to improve reproducibility (supported for SD2.x or variant only)
--deepdanbooru does not do anything
--opt-split-attention
force-enables Doggettx's cross-attention layer optimization. By default, it's on for torch cuda.
--opt-sub-quad-attention
enable memory efficient sub-quadratic cross-attention layer optimization
--sub-quad-q-chunk-size SUB_QUAD_Q_CHUNK_SIZE
query chunk size for the sub-quadratic cross-attention layer optimization to use
--sub-quad-kv-chunk-size SUB_QUAD_KV_CHUNK_SIZE
kv chunk size for the sub-quadratic cross-attention layer optimization to use
--sub-quad-chunk-threshold SUB_QUAD_CHUNK_THRESHOLD
the percentage of VRAM threshold for the sub-quadratic cross-attention layer optimization to use chunking
--opt-split-attention-invokeai
force-enables InvokeAI's cross-attention layer optimization. By default, it's on when cuda is unavailable.
--opt-split-attention-v1
enable older version of split attention optimization that does not consume all the VRAM it can find
--opt-sdp-attention enable scaled dot product cross-attention layer optimization; requires PyTorch 2.*
--opt-sdp-no-mem-attention
enable scaled dot product cross-attention layer optimization without memory efficient attention, makes image
generation deterministic; requires PyTorch 2.*
--disable-opt-split-attention
force-disables cross-attention layer optimization
--disable-nan-check do not check if produced images/latent spaces have nans; useful for running without a checkpoint in CI
--use-cpu USE_CPU [USE_CPU ...]
use CPU as torch device for specified modules
--listen launch gradio with 0.0.0.0 as server name, allowing to respond to network requests
--port PORT launch gradio with given server port, you need root/admin rights for ports < 1024, defaults to 7860 if
available
--show-negative-prompt
does not do anything
--ui-config-file UI_CONFIG_FILE
filename to use for ui configuration
--hide-ui-dir-config hide directory configuration from webui
--freeze-settings disable editing settings
--ui-settings-file UI_SETTINGS_FILE
filename to use for ui settings
--gradio-debug launch gradio with --debug option
--gradio-auth GRADIO_AUTH
set gradio authentication like "username:password"; or comma-delimit multiple like "u1:p1,u2:p2,u3:p3"
--gradio-auth-path GRADIO_AUTH_PATH
set gradio authentication file path ex. "/path/to/auth/file" same auth format as --gradio-auth
--gradio-img2img-tool GRADIO_IMG2IMG_TOOL
does not do anything
--gradio-inpaint-tool GRADIO_INPAINT_TOOL
does not do anything
--opt-channelslast change memory type for stable diffusion to channels last
--styles-file STYLES_FILE
filename to use for styles
--autolaunch open the webui URL in the system's default browser upon launch
--theme THEME launches the UI with light or dark theme
--use-textbox-seed use textbox for seeds in UI (no up/down, but possible to input long seeds)
--disable-console-progressbars
do not output progressbars to console
--enable-console-prompts
print prompts to console when generating with txt2img and img2img
--vae-path VAE_PATH Checkpoint to use as VAE; setting this argument disables all settings related to VAE
--disable-safe-unpickle
disable checking pytorch models for malicious code
--api use api=True to launch the API together with the webui (use --nowebui instead for only the API)
--api-auth API_AUTH Set authentication for API like "username:password"; or comma-delimit multiple like "u1:p1,u2:p2,u3:p3"
--api-log use api-log=True to enable logging of all API requests
--nowebui use api=True to launch the API instead of the webui
--ui-debug-mode Don't load model to quickly launch UI
--device-id DEVICE_ID
Select the default CUDA device to use (export CUDA_VISIBLE_DEVICES=0,1,etc might be needed before)
--administrator Administrator rights
--cors-allow-origins CORS_ALLOW_ORIGINS
Allowed CORS origin(s) in the form of a comma-separated list (no spaces)
--cors-allow-origins-regex CORS_ALLOW_ORIGINS_REGEX
Allowed CORS origin(s) in the form of a single regular expression
--tls-keyfile TLS_KEYFILE
Partially enables TLS, requires --tls-certfile to fully function
--tls-certfile TLS_CERTFILE
Partially enables TLS, requires --tls-keyfile to fully function
--server-name SERVER_NAME
Sets hostname of server
--gradio-queue Uses gradio queue; experimental option; breaks restart UI button
--skip-version-check Do not check versions of torch and xformers
--no-hashing disable sha256 hashing of checkpoints to help loading performance
--no-download-sd-model
don't download SD1.5 model even if no model is found in --ckpt-dir
--ldsr-models-path LDSR_MODELS_PATH
Path to directory with LDSR model file(s).
--lora-dir LORA_DIR Path to directory with Lora networks.
--scunet-models-path SCUNET_MODELS_PATH
Path to directory with ScuNET model file(s).
--swinir-models-path SWINIR_MODELS_PATH
Path to directory with SwinIR model file(s).
```
以上、高速化の動作検証を説明しました。

