Claude Codeを大規模なコードベースで使うと、トークン消費が急激に膨らみます。
この問題に悩んでいる人は多いでしょう。
Redditのr/ClaudeAIコミュニティで、この課題に対する興味深い議論が行われていました。
本記事では、その議論から得られた知見をもとに、トークン消費を抑える具体的な手法を紹介します。
なぜClaude Codeはトークンを大量消費するのか
Claude Codeがコードベースを探索する際、内部ではgrepやglobといった基本的なツールに依存しています。
関連するコードを見つけるために、エージェントは以下のような処理を繰り返します。
まず、数十個のファイルをリストアップします。
次に、それらを一つずつ読み込んで関連性をチェックします。
さらに、ディレクトリを掘り下げるためにサブエージェントを起動することもあります。
この「リスト → 読み込み → フィルタリング → 繰り返し」というループが問題です。
これがトークン消費を爆発させる原因となっています。
特に15万行を超えるような大規模プロジェクトでは、この問題が顕著に現れます。
検索フェーズだけで5万トークン以上を消費してしまうケースも珍しくありません。
セマンティック検索による解決策
この問題に対して、あるRedditユーザーがGoで開発したCLIツールを公開していました。
キーワードの完全一致ではなく「意味」でコードを検索するアプローチです。
仕組みはこうです。
Ollama経由でローカルの埋め込みモデルを利用し、コードベース全体をセマンティックにインデックス化します。
Claude Codeがコードを探す際、このインデックスを参照します。
その結果、最初の試行で適切なファイルにたどり着けるようになります。
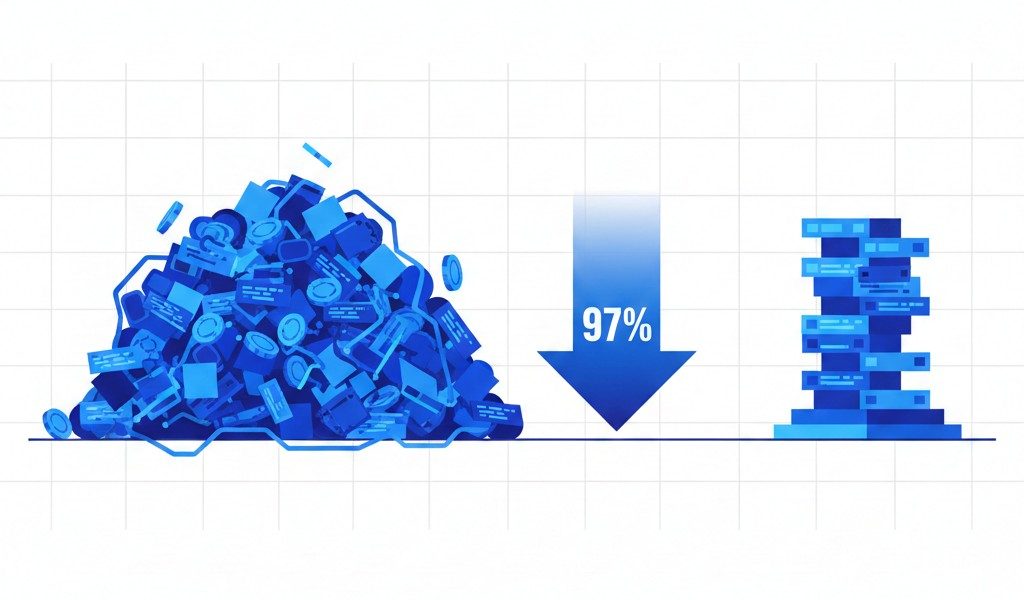
ベンチマーク結果は驚くべきものでした。
Excalidrawという15万行のプロジェクトで5つの開発タスクを実行。
その結果、検索フェーズの入力トークンが約5万1千から約1,300へと97%も減少したとのことです。
総コストも27.5%削減されました。
サブエージェントの起動回数はゼロになっています。
ただし、コミュニティからは重要な指摘もありました。
トークン削減の数値は印象的です。
しかし、コード品質への影響はどうなのか。
スニペットだけで判断させると、Claudeが「怠けて」全体像を把握しないまま作業を進めてしまう可能性があります。
実際に試したユーザーの中には、検索結果が期待した内容と異なるケースを報告する人もいました。
MDファイルによるシンプルなアプローチ
一方で、より手軽な方法を提案するユーザーもいました。
スクリプトの参照情報をMDファイルにまとめ、Claudeにそのファイルを参照させるというシンプルな手法です。
具体的には、scriptReferences.mdというファイルを作成します。
そこに各スクリプトの名前、名前空間、簡単な説明、ファイルパスを記録します。
Claudeに「スクリプトを探すときはこの参照ファイルをチェックして」と指示すれば、ほぼ瞬時に目的のファイルを見つけられるようになります。
この手法はさらに発展させることも可能です。
- 新機能の設計計画をMDファイルにまとめる
- フェーズごとに分割したMDファイルを作成する
- 現在のタスクに関連するすべてのリンクをまとめたreadme_this_current_task.mdを用意する
コンテキストをリセットして新しいセッションを開始しても、「readme_this_current_taskを読んで」と伝えるだけで済みます。
すぐに作業を再開できるわけです。
この方法のメリットは、追加のツールを導入する必要がないことです。
デメリットは、コードベースが変更されるたびに手動でMDファイルを更新する必要がある点でしょう。
大規模なプロジェクトでは、ドキュメントと実際のコードの乖離が起きやすくなります。
grepとセマンティック検索の併用という選択肢
Cursorの開発チームも、同様の課題に取り組んできた経験を公開しています。
彼らの結論は明確でした。
grepとセマンティック検索の両方を使うことが最良の結果をもたらす、というものです。
grepは正確なパターンを見つけるのに優れています。
関数名やクラス名など、明確な文字列を検索する場合は非常に効率的です。
一方、セマンティック検索は概念的に類似したコードを見つけるのに適しています。
「認証処理はどこにある?」といった曖昧なクエリに対して力を発揮します。
興味深い意見もありました。
Claude Codeの「原始的な」grep中心のアプローチが、実際のコーディング支援では予想以上に効果的だという声です。
セマンティック検索が万能というわけではないのです。
ファイルコメントによる補助
もう一つ紹介されていたテクニックがあります。
各ファイルの先頭にコメントを追加する方法です。
ファイルの目的や役割を簡潔に記述しておくと、Claudeがコードベースを理解する手助けになります。
あるユーザーは、この冗長に見えるコメントが実は非常に有効だと報告していました。
特に、変更の「理由」を記録しておくと効果的です。
Claudeが同じ問題を行ったり来たりする現象を防げるとのことです。
具体的には、バグAを修正したらバグBが発生し、バグBを直したらバグAが再発するという悪循環があります。
コメントで「なぜこの変更をしたか」を残しておくと、この悪循環を断ち切れます。
実践的な活用に向けて
これらの手法を実践する際、いくつかの点を考慮する必要があります。
セマンティック検索ツールを導入する場合、埋め込みモデルの品質がそのまま検索精度に直結します。
ローカルで動作するモデルは手軽です。
しかし、商用の埋め込みAPIと比較すると精度が劣る場合もあるようです。
また、ファイル変更時に再インデックスが必要になります。
デーモンモードで自動的に再インデックスする機能があると便利でしょう。
MDファイルによる管理は、小〜中規模のプロジェクトでは十分に機能します。
ただし、プロジェクトが成長するにつれて、ドキュメントの維持管理コストも増加していきます。
LLM自身にドキュメントを生成・更新させるワークフローを構築すれば、この負担を軽減できます。
どのアプローチを選ぶにせよ、トークン削減だけを追求するのは危険です。
Claudeに十分なコンテキストを与えないと、表面的な理解に基づいた低品質なコードを生成してしまう可能性があります。
コスト削減と品質維持のバランスを常に意識してください。
まとめ
Claude Codeのトークン消費問題に対しては、複数のアプローチが存在します。
ローカルセマンティック検索ツールは、大規模コードベースで劇的なトークン削減効果を発揮する可能性を秘めています。
一方で、精度の問題やコード品質への影響については、まだ十分な検証が必要です。
MDファイルによるスクリプト参照管理は、追加ツールなしで導入できます。
即座に効果を実感できるシンプルな手法です。
ただし、ドキュメントの維持管理という継続的なコストが発生します。
理想的には、grepとセマンティック検索を組み合わせることでしょう。
状況に応じて使い分けるのです。
正確なパターンマッチングが必要な場面ではgrepを、概念的な検索が必要な場面ではセマンティック検索を活用する。
この柔軟なアプローチが、最も実用的な解決策になりそうです。
AIコーディング支援ツールの進化は目覚ましいものがあります。
数ヶ月後には今回紹介した手法が不要になるかもしれません。
それでも、現時点でトークンコストに悩んでいる開発者にとって、これらの知見は参考になるはずです。
コミュニティで共有された知恵を活用して、より効率的な開発ワークフローを構築してみてください。

