
GoogleドライブのOCRは、無料で使える最高峰のモノです。
でも、この機能を自動化するのはほぼ不可能となります。
ここでの自動化とは、プログラムを使った自動化を指しています。
自動化が無理であるため、ブラウザで開いて作業をしないといけません。
このあたりのノウハウは、検索すればたくさん出てきます。
そこで、素直にAPIを利用しようと考えました。
APIとは、Google Cloud Vision API(以下 Vision API)のことです。
この記事では、Vision APIを使ったOCRについて解説していきます。
本記事の内容
- Vision APIとは?
- Vision APIでOCRした結果
- Vision APIでOCRを実行する準備
- 【サンプルコード】Vision APIを使ったOCRの実行
それでは、上記に沿って解説していきます。
Vision APIとは?
Vision APIについては、Googleの公式ページで詳しい説明があります。
「Vision API」で検索すれば、説明ページにすぐにたどり着けるでしょう。
もちろん、そのページを読むのがベストです。
しかし、説明が多すぎて理解しにくいという意見もあるでしょう。
ここでは、OCRに絞ってVision APIを説明します。
Vision APIの機能の一つに、「印刷テキストと手書き文字の検出」があります。
この機能を使って、最高レベルのOCRを自動化していきます。
「ちょっと待って!!Vision APIは、有料じゃないの!?」
このように思う方が、いるかもしれません。
それは、事実です。
でも、無料で使う方法があります。

上は、料金表からOCRに関係する部分をピックアップしたモノです。
ここで「最初の 1,000ユニット/月」に注目してください。
月に1000回の利用までは、無料です。
仮に1000回を超えても、1000回あたりで1.5ドルです。
正直、Vision APIの精度であれば全然安いと思います。
他の有償のOCRと比較しても、圧倒的にコストパフォーマンスは上回るでしょう。
以上、Vision APIについて説明しました。
次は、Vision APIでOCRした結果を見ていきましょう。
Vision APIでOCRした結果
Vision APIの精度を確認しましょう。
本来ならば、他の有料OCRの結果と比較したいところです。
しかし、有料OCRほど閉鎖的なのですよね。
オンラインデモなどで精度を検証できません。
おそらく、比較されると困るのでしょう。
このような閉鎖的な企業は、遅かれ早かれ淘汰されていきます。
話がそれましたが、Vision APIによるOCRの精度に話を戻しましょう。
比較ということであれば、GoogleドライブのOCRと比較します。
こっちの比較の方が、みなさんには馴染みがあるでしょう。
比較その1

Vision API
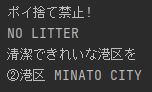
Googleドライブ
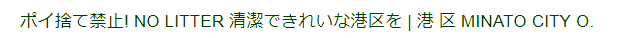
比較その2

Vision API
Googleドライブ

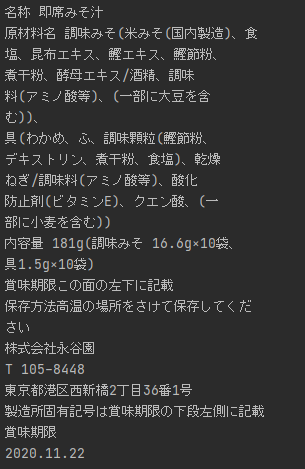
比較その3

Vision API

Googleドライブ

まとめ
すべての画像が、読み込み困難な画像になります。
でも、Vision APIとGoogleドライブはともにあっさりとテキストを認識しています。
結果を見ると、全く同じ解析エンジンを利用しているわけではなさそうです。
両方ともディープラーニングによるモノには間違いないでしょう。
AI OCRというヤツですね。
比較した結果は、精度自体に関しては引き分けと言えるでしょう。
ただ、Vision APIで改行を認識できているのはデカいです。
あと、Vision APIの場合は、文字サイズや文字位置などの情報も取得可能です。
以上、Vision APIでOCRした結果を説明しました。
次に、Vision APIでOCRを実行する準備を説明します。
Vision APIでOCRを実行する準備
次の記事で詳しく解説しています。

GoogleのAPIに慣れていなと、若干難しい内容かもしれません。
でも、スクショ多めで説明しているので何とかなるはずです。
準備が整ったら、実際にOCRを実行しましょう。
【サンプルコード】Vision APIを使ったOCRの実行
Vision APIを利用してOCRを行うサンプルコードです。
import io
from google.cloud import vision
from google.oauth2 import service_account
# 身元証明書のjson読み込み
credentials = service_account.Credentials.from_service_account_file('key.json')
client = vision.ImageAnnotatorClient(credentials=credentials)
# OCR対象の画像パス
input_file = "test.png"
with io.open(input_file, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(image=image)
# OCRした結果を表示
print(response.full_text_annotation.text)
準備さえ整っていれば、コピペで動きます。
実際にVision APIの凄さを感じてみてください。
以上、Vision APIを使ったOCRの実行について説明しました。

