「Pythonで音声認識を気軽に試してみたい」
「音声のテキスト変換を簡単に検証したい」
「SpeechRecognitionを使うには何をインストールすればよいの?」
このように思っている方は、この記事をご覧ください。
ネット上では、SpeechRecognitionに関しては情報が錯そうしています。
記事によって、インストールするライブラリがバラバラです。
さらには、全く利用しないライブラリをインストールしている記事もあります。
つまり、真似してはいけない手順があちこちに存在している状況です。
検証であれば、最小限のライブラリしかインストールしたくありませんよね。
そこで、Pythonで音声認識をするための最小構成をまとめました。
SpeechRecognitionを利用することが前提です。
本記事の内容
- 最小構成でSpeechRecognitionを利用する
- ライブラリのインストール
- 【実証】音声のテキスト変換
最小構成でSpeechRecognitionを利用する
まずは、SpeechRecognitionについての説明です。
これを理解しておかないと、インストールすべきライブラリの判断ができません。
SpeechRecognitionとは?
公式
https://pypi.org/project/SpeechRecognition/
音声認識を実行するためのライブラリで、いくつかのエンジンとAPIをサポートしています。
そして、オンラインとオフラインの両方に対応します。
対応している音声認識エンジン/APIは以下。
- CMU Sphinx(オフラインで動作)
- Google Speech Recognition
- Google Cloud Speech API
- Wit.ai
- Microsoft Bing Voice Recognition
- Houndify API
- IBM Speech to Text
- Snowboy Hotword Detection(オフラインで動作)
SpeechRecognition単独で音声認識をしているのではありません。
エンジンやAPIを利用して、音声認識を実現しているということです。
では、どのエンジンやAPIを使えばいいのでしょうか?
検証で利用(もしくは個人利用)するケースに絞ります。
日本語対応は、前提です。
そして、無料も前提です。
| エンジン/API | 日本語対応 | 無料 | 備考 |
| CMU Sphinx | × | 〇 | |
| Google Speech Recognition | 〇 | 〇 | |
| Google Cloud Speech API | 〇 | × | |
| Wit.ai | 〇 | 〇 | 人工知能API |
| Microsoft Bing Voice Recognition | 〇 | × | |
| Houndify API | × | × | 音楽認識検索 |
| IBM Speech to Text | 〇 | × | |
| Snowboy Hotword Detection | × | 〇 | ホットワード検出 |
候補は、Google Speech RecognitionとWit.aiです。
ただ、Wit.aiは人工知能APIであり、ボットを作成するなどがメインです。
音声認識も可能のようですが、今回は候補から外します。
よって、Google Speech Recognitionを利用します。
これは、「Google Speech Private API」とも呼ばれています。
AndroidやGoogle Chromeに組み込まれているものですね。
SpeechRecognitionを動かすのに必要条件は?
Python 2.6, 2.7, or 3.3+
Pythonのバージョンです。
よほど古くない限りは、大丈夫です。
PyAudio 0.2.11+
マイクの音声を利用する場合には、必要です。
単純に音声ファイルを認識する場合でも、インストールしている記事が存在します。
その記事が検索で上位に出てくるから、それをコピーしたものが多いのかもしれません。
音声認識の検証であれば、PyAudioをインストールする必要はありません。
Google API Client Library for Python
Google Cloud Speech APIを利用する場合のみ、インストール必要です。
検証の場合は、インストール不要。
インストールするライブラリは?
検証レベルで動かす場合(マイク入力なし)であれば、SpeechRecognitionのみです。
つまり、音声ファイルをテキストに変換するだけなら、SpeechRecognitionのインストールだけで済みます。
ライブラリのインストール
SpeechRecognitionをインストールします。
pip install SpeechRecognition
以下のように表示されれば、インストール成功です。
Collecting SpeechRecognition
Downloading https://files.pythonhosted.org/packages/26/e1/7f5678cd94ec1234269d23756dbdaa4c8cfaed973412f88ae8adf7893a50/SpeechRecognition-3.8.1-py2.py3-none-any.whl (32.8MB)
100% |████████████████████████████████| 32.8MB 819kB/s
Installing collected packages: SpeechRecognition
Successfully installed SpeechRecognition-3.8.1
無駄なライブラリは、インストールしません。
必要な都度、ライブラリはインストールしましょう。
【実証】音声のテキスト変換
テキスト化する音声ファイルを用意します。
今回は、次のテキストを読んでいる音声ファイルを用意。
ベーステキスト
Pythonで音声からテキストへ変換。 このことを簡単に検証してみる。 そのためには、SpeechRecognitionのインストールだけでよい。 他の記事では、pyaudioなど無駄なライブラリもインストールしている。
音声ファイル「sample.wav」をスクリプト(実証コード)と同じフォルダに設置。
そして、実証コードを動かして、音声認識の結果とベーステキストを比較します。
それに加えて、他の音声認識エンジンによる音声認識も行っています。
日本語対応していて、デモページが用意されているもので検証しています。
- Google Cloud Speech API
- IBM Speech to Text
では、まずはSpeechRecognitionを実証コードで動かしてみます。
SpeechRecognition(音声認識エンジンはGoogle Speech Recognitionを利用)の認識結果
実証コード
import speech_recognition as sr
r = sr.Recognizer()
with sr.AudioFile("sample.wav") as source:
audio = r.record(source)
text = r.recognize_google(audio, language='ja-JP')
print(text)
上記の実行結果
難関は2か所。
SpeechRecognitionとpyaudio。
SpeechRecognitionは、適切に認識しています。
しかし、pyaudioは難しいですね。
そもそも、pyaudio自体が造語です。
音声の時点で「ペイディオ」と発音しています。
だから、これは他の音声認識エンジンでも同じような結果だと思います。
Google Cloud Speech API(サイトのデモ利用)の認識結果
デモページ
https://cloud.google.com/speech-to-text?hl=ja
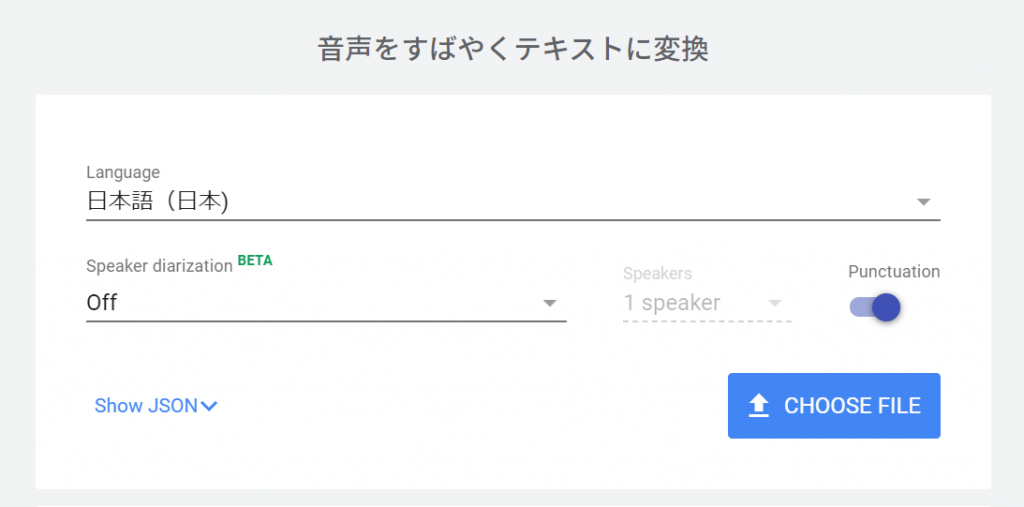
「ではフリオ」と「治りを」だけの違いです。
僅差で、SpeechRecognitionの勝利。
IBM Speech to Text(サイトのデモ利用)の認識結果
デモページ
https://speech-to-text-demo.ng.bluemix.net/
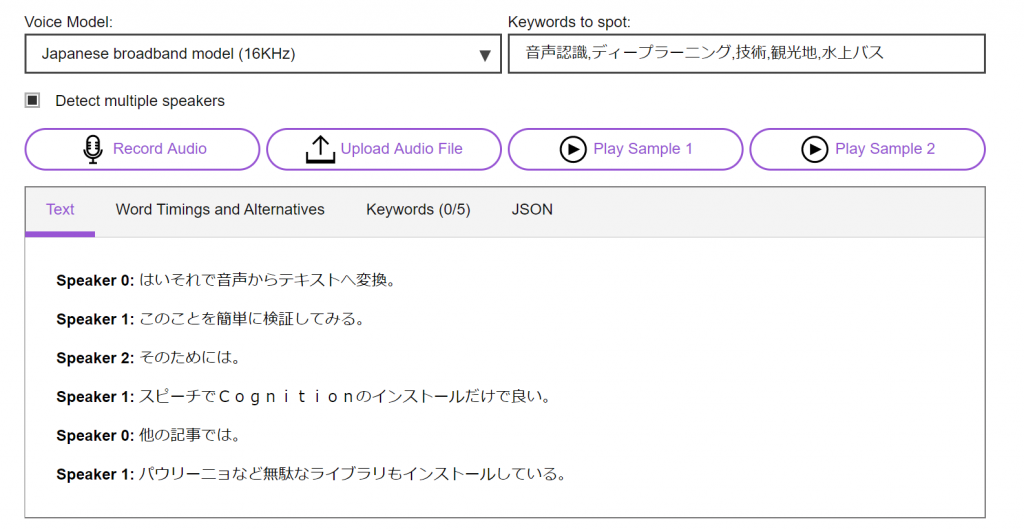
Speaker 1: このことを簡単に検証してみる。
Speaker 2: そのためには。
Speaker 1: スピーチでCognitionのインストールだけで良い。
Speaker 0: 他の記事では。
Speaker 1: パウリーニョなど無駄なライブラリもインストールしている。
これは、ヤバい結果となりました。
Googleチームの圧勝ですね。
まとめ
Pythonで音声からテキストへ変換する方法を説明してきました。
無駄なライブラリをインストールすることなく、最小構成で検証できることを前提にしています。
結果的には、SpeechRecognitionのインストールだけで済みました。
そして、実際にコードを動かしてみました。
その結果は、スバラシイの一言です。
他の音声認識エンジンも試しましたが、それらにも全く劣っていません。
むしろ、勝っているぐらいです。
それに比べて、IBMの音声認識は酷い結果となりました。
まあ、Googleスゲーという結果でもありますね。
最後にまとめます。
SpeechRecognitionが、使えるのはわかりました。
検証成功と言えます。
これだけの成果を得られましたので。
ただ、Google Speech Recognitionがどれだけ利用できるのかが問題です。
具体的には以下。
- 一度にどれだけの認識ができるのか?
- 利用制限はあるのか?
- 利用制限がある場合、どれくらい(データ量?呼び出し回数?)の制限なのか?
上記の問題がクリアできれば、SpeechRecognitionはかなり使えます。
そのためには、まずは上記問題の検証です。
検証内容は、別途記事にまとめます。
【追記】上記の問題を検証した結果は↓


