
「ブラウザで見たままのスクリーンショットが欲しい」
このシンプルな要望に応えるのは、Seleniumです。
もちろん、文字化けや文字フォントの問題とは無縁です。
本記事では、キレイなスクリーンショットを取得する方法を解説します。
コピペで使えるコードも載せています。
本記事の内容
- Seleniumを準備する
- PythonでAmazonのスクリーンショットを取得する
- PythonでTwitterのスクリーンショットを取得する
それでは、上記に沿って解説していきます。
Seleniumを準備する
Pythonでスクリーンショットを撮るには、Seleniumを利用します。
そのため、Seleniumを利用できることが前提となります。
Seleniumのインストールに関しては、次の記事をご覧ください。

以上、Seleniumの準備について説明しました。
次は、スクリーンショットを撮っていきます。
PythonでAmazonトップのスクリーンショットを取得する
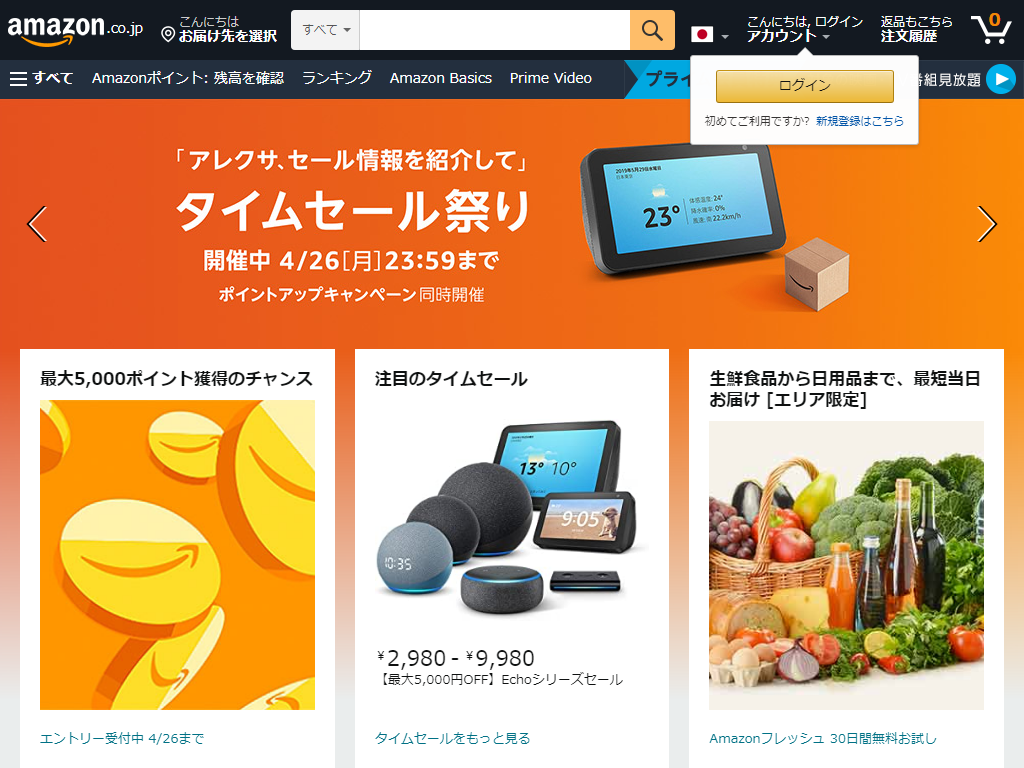
このスクリーンショットは、次のコードで取得しています。
screenshot_1.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
CHROMEDRIVER = "chromedriver.exeのパス"
URL = "https://www.amazon.co.jp/"
options = Options()
# スクロールバーを非表示にする
options.add_argument('--hide-scrollbars')
# シークレットモードでChromeを起動する
options.add_argument('--incognito')
# ブラウザを表示しない
options.add_argument('--headless')
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
# ウィンドウサイズ=画像サイズ
driver.set_window_size(1024, 768)
# 対象ページへアクセス
driver.get(URL)
# スクリーンショットを取得
driver.save_screenshot('result.png')
driver.quit()
次の箇所が理解できない場合は、上記で紹介した記事をご覧ください。
CHROMEDRIVER = "chromedriver.exeのパス"
プログラムの内容は、コメントで確認してください。
できる限りでコメントをつけています。
どうでしょうか?
なんてことないですよね。
でも、このコードだとスクリーンショットを取得できないケースがあります。
次は、そのケースについて確認しましょう。
PythonでTwitterのスクリーンショットを取得する
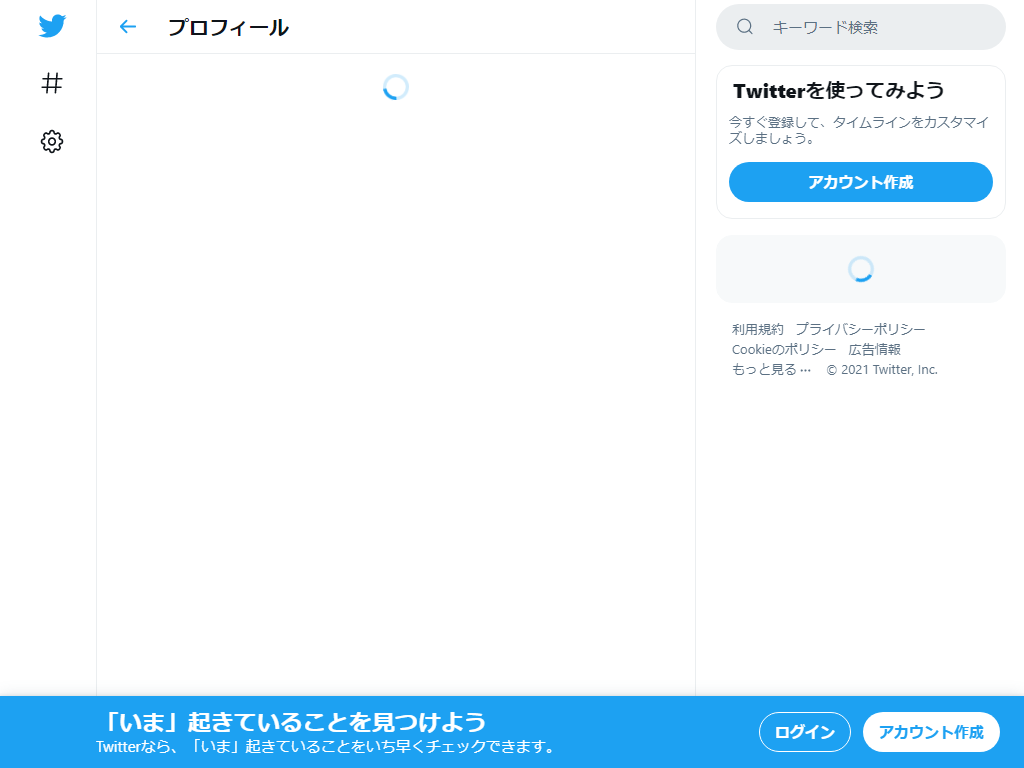
先ほどのプログラム(screenshot_1.py)における「URL」の値を変更します。
URL = "https://twitter.com/AmazonJP"
そのように変更して取得したスクリーンショットが、上の画像となります。
なぜ、このような空っぽの画面になるのでしょうか?
その理由は、タイミングにあります。
Twitterは、Ajaxにより動的にコンテンツを表示しています。
そのため、コンテンツが表示し終わるまでにしばらく時間がかかります。
screenshot_1.pyのプログラムでは、Ajax処理の途中でスクリーンショットを撮るのです。
だから、空っぽの画面のスクリーンショットを取得することになります。
このタイミングの問題を解決したコードは、以下。
screenshot_2.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
CHROMEDRIVER = "chromedriver.exeのパス"
URL = "https://twitter.com/AmazonJP"
options = Options()
options.add_argument('--hide-scrollbars')
options.add_argument('--incognito')
options.add_argument('--headless')
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
driver.set_window_size(1024, 768)
# 暗黙的に指定時間待つ(秒)
driver.implicitly_wait(10)
driver.get(URL)
try:
# articleタグを探す
element = driver.find_element_by_tag_name("article")
except NoSuchElementException:
print("探した要素は存在しない")
finally:
driver.save_screenshot('result.png')
driver.quit()
この変更したプログラムを実行すると、次のスクリーンショットを取得できます。
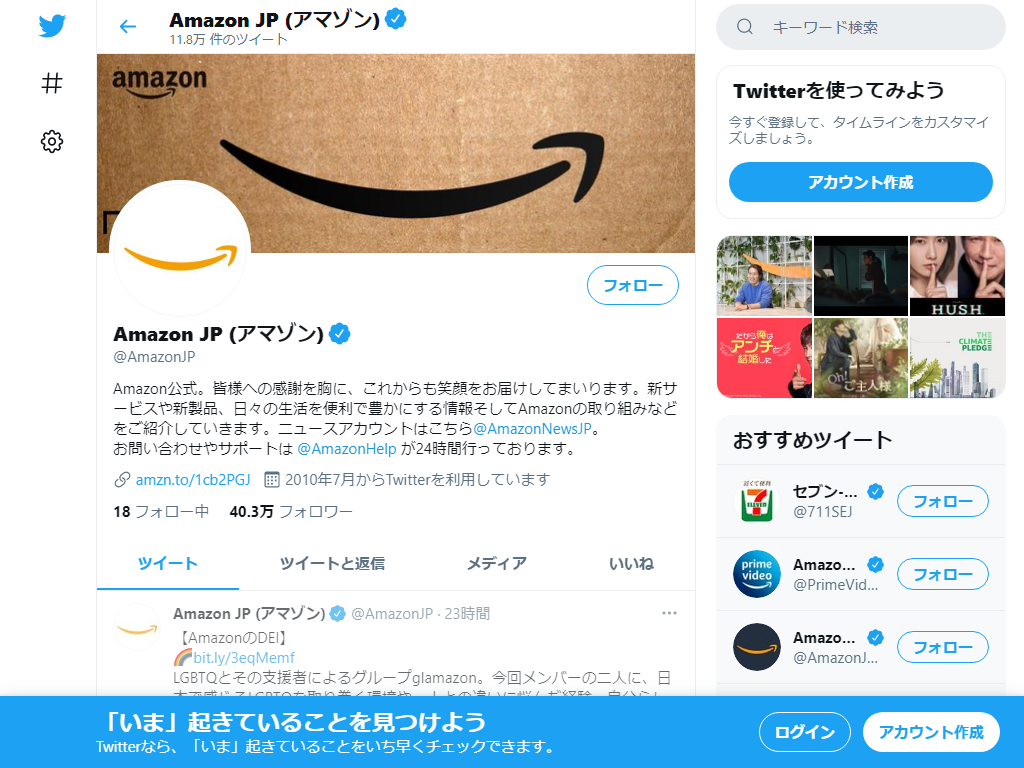
追記した箇所には、コメントをつけています。
ポイントは、以下の部分です。
# 暗黙的に指定時間待つ(秒) driver.implicitly_wait(10)
# articleタグを探す
element = driver.find_element_by_tag_name("article")
これらは、二つで一つです。
セットで使うと覚えておいてください。
find_element_by_tag_nameに限らず、find_element_〇が対象となります。
機能としては、implicitly_waitに指定した時間だけ要素を探します。
要素が見つかった時点で、次の処理へ進みます。
もし見つからなかったら、エラーとなります。
エラーになるのは嫌なので、例外処理を対応しています。
また、implicitly_waitを設定するだけでは待機しません。
find_element_〇を実行することにより、最大で10秒間は探します。
調査した限りでは、2秒以内にはarticleタグが見つかっています。
なお、articleタグは以下の要素になります。
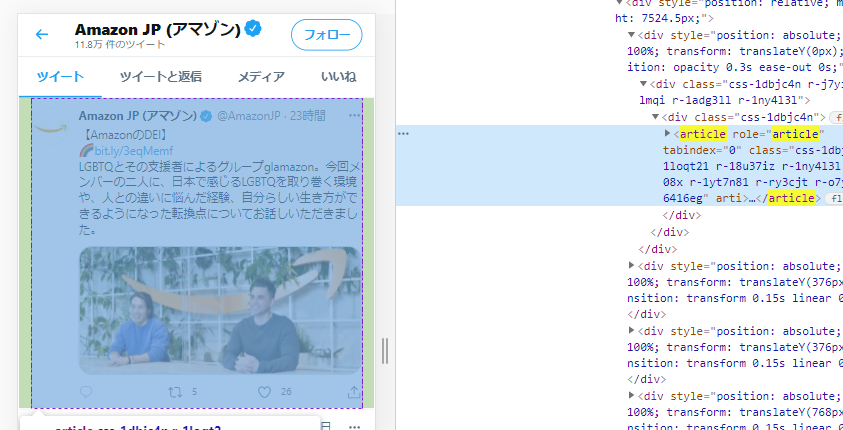
articleタグが見つかった時点で、コンテンツ表示は完了しているとみなしています。
仮にarticleタグが見つからなかった場合、10秒間は待機することになります。
10秒経てば、さすがにコンテンツ表示は完了しています。
だから、見つかる・見つからないに関わらず、スクリーンショットは上手く撮れます。
ただし、見つからない場合は10秒間待たないといけません。
まあ、10秒ぐらいはデフォルトで待機するのもアリとは思いますけどね。
以上、PythonでTwitterのスクリーンショットを取得するための説明でした。
追記 2021年11月29日
この記事は、Selenium 3を利用した場合の内容となります。
Selenium 4の場合は、次の記事を参考にしてみてください。


