
「誰がいつ話したのかを音声から自動的に識別したい」
「話者分離に対応した文字起こしを行いたい」
このような場合には、Whisper speaker diarizationがオススメです。
この記事では、Whisper speaker diarizationのインストールを解説しています。
本記事の内容
- Whisper speaker diarizationとは?
- Whisper speaker diarizationのシステム要件
- Whisper speaker diarizationのインストール
- Whisper speaker diarizationの動作確認
それでは、上記に沿って解説していきます。
Whisper speaker diarizationとは?
Whisper speaker diarizationとは、話者分離が可能なWebアプリのことです。
Whisper Speaker Diarization – a Hugging Face Space by vumichien
https://huggingface.co/spaces/vumichien/whisper-speaker-diarization
上記ページは、デモ画面になります。
ただし、ちゃんと動かないと思います。
人がいないときを狙えば、動かすことができるかもしれません。
利用方法は、「Whisper speaker diarizationの動作確認」で説明しています。
このWhisper speaker diarization自体は、以下の技術で構成されています。
- Whisper(OpenAI)
- ECAPA-TDNN(SpeechBrain)
Whisperによって、音声から文字起こしを実現しています。
そして、ECAPA-TDNNを用いて話者分離が可能になっています。
これらの技術を組わせて、Whisper speaker diarizationが開発されているということです。
Whisper自体が、強烈過ぎる機能を持っています。

その強烈な機能を活かして、開発されたアプリと言えます。
話者毎にテキストが抽出される様子は、初めて見ると感動します。
思わず、「おー」と声がでてしまうほどです。
Whisper speaker diarizationを利用すれば、会議の議事録などが作りやすいでしょうね。
いつ、誰が、どんなことを言ったのかが動画(音声)から、簡単に判明できます。
とにかく、まずはデモ画面でも動かしてみてください。
なお、私はHugging Face上で待つことができずに、すぐさまローカルマシンに環境を構築しました。
以上、Whisper speaker diarizationについて説明しました。
次は、Whisper speaker diarizationのシステム要件を説明します。
Whisper speaker diarizationのシステム要件
Whisper speaker diarizationには、現状では詳細な説明ページは存在していません。
そのため、明確なシステム要件がどこにも記載されていない状況になります。
ここでの内容は、実際にインストールする過程で把握できた内容です。
よって、漏れがあるかもしれないことを理解しておいてください。
そんな中で考慮すべきであるのは、以下となります。
- OS
- Pythonバージョン
- PyTorch
- FFmpeg
- fastText
それぞれを以下で説明します。
OS
サポートOSに関しては、以下を含むクロスプラットフォーム対応のはずです。
- Windows
- macOS
- Linux
少なくともWindowsで動くことは確認できました。
Hugging Faceは、おそらくLinuxです。
よって、macOS以外の動作確認はできていることになります。
ただ、macOSで動かない道理はないんですよね。
Pythonバージョン
現時点でのPython公式開発サイクルは、以下。
| バージョン | リリース日 | サポート期限 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
| 3.11 | 2022年10月25日 | 2027年10月 |
個人的には、PyThon 3.10が無難だと思います。
PyTorch
PyTorchのインストールは、事前に済ませておきましょう。

ただ、GPUが利用可能ならGPU版のインストールをオススメします。
WhisperをCPUだけ動かすのは、無理があります。

FFmpeg
Pythonライブラリに、FFmpegを必要とするモノが存在しています。
そのため、事前にインストールしておく必要があります。
FFmpegのインストールは、以下の記事を参考にしてください。


fastText
これが、最も厄介かもしれません。
fastTextは、もうメンテナンスされていない状態です。
そして、インストール時にビルドする必要があります。
macOSやLinuxだと、ビルド環境があれば次のコマンドでインストール可能です。
pip install fasttext
しかし、Windowsへのインストールは簡単なモノではありません。
基本的に、Windowsでは上記コマンドが失敗します。
このような場合には、ビルドされたバイナリを探しましょう。
個人的には、次のページを重宝しています。
Archived: Python Extension Packages for Windows – Christoph Gohlke
https://www.lfd.uci.edu/~gohlke/pythonlibs/
ただ、アクセス時点ではChromeにおいて危険なサイト扱いになっています。
SSL証明書の期限が切れて、放置されたままのようです。

ちゃんとした大学のサイトなのに、こんなことになるんですね。
話をfastTextに戻すと、ちゃんとバイナリが公開されています。

Windows(64bit)でPython 3.10の環境だと、下線のモノが該当します。
該当するパッケージを選択して、ダウンロードしましょう。
リンクをクリックしたら、ファイルのダウンロードが始まります。
ダウンロードできたら、次のコマンドでインストールします。
pip install fasttext-0.9.2-cp310-cp310-win_amd64.whl
上記サイトだと、macOSやLinux用のバイナリも用意されています。
ビルドせずに、これらを利用するのもありですね。
以上、Whisper speaker diarizationのシステム要件を説明しました。
次は、Whisper speaker diarizationのインストールを説明します。
Whisper speaker diarizationのインストール
Whisper speaker diarizationのインストールは、Python仮想環境の利用をオススメします。
Python仮想環境は、次の記事で解説しています。

検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
そして、システム要件であるGPU版PyTorchをインストール済という状況です。
このような状況において、次の手順でWhisper speaker diarizationのインストールを進めます。
- Whisper speaker diarizationの取得(Hugging Faceから)
- requirements.txtを使った一括インストール
それぞれを下記で説明します。
Whisper speaker diarizationの取得(Hugging Faceから)
Whisper speaker diarizationのファイル
https://huggingface.co/spaces/vumichien/whisper-speaker-diarization/tree/main
上記ページでファイルを確認できます。
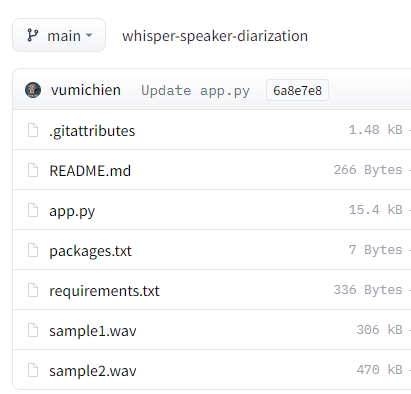
すべてを手動でダウンロードしてもOKです。
でも、ここでは次のツールを使います。

huggingface_hubを利用すると、自動的にファイルをダウンロードしてくれます。
huggingface_hubをインストールできたら、次のコードを実行します。
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="vumichien/whisper-speaker-diarization",
repo_type="space",
revision="main",
cache_dir="./")
上記コードを実行すると、ダウンロード処理が開始されます。
ダウンロードは、すぐに終わります。
処理が完了すると、ディレクトリ上に「spaces–vumichien–whisper-speaker-diarization」を確認できます。
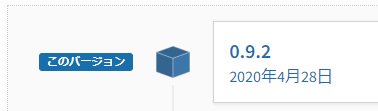
そして、「snapshots」以下にあるファイル・ディレクトリをコピーします。
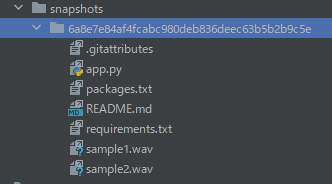
「6a8e7e84af4fcabc980deb836deec63b5b2b9c5e」は、リポジトリのバージョンです。
バージョンが更新されれば、この値も変わってきます。
この長たらしいディレクトリより下のモノをコピーしましょう。
コピーしたファイルは、コンテンツルートに保存します。
requirements.txtを使った一括インストール
コンテンツルートには、コピーしたrequirements.txtが存在しています。
requirements.txt
git+https://github.com/huggingface/transformers git+https://github.com/pyannote/pyannote-audio git+https://github.com/openai/whisper.git gradio==3.12 ffmpeg-python pandas==1.5.0 pytube==12.1.0 sacremoses sentencepiece tokenizers torch torchaudio tqdm==4.64.1 EasyNMT==2.0.2 tqdm nltk transformers pysrt psutil==5.9.2 requests gpuinfo
PyTorchはインストール済みのため、関連パッケージをコメントにしておきます。
#torch #torchaudio
変更後のrequirements.txtを利用して、必要なモノを一気にインストールします。
実行するのは、次のコマンドです。
pip install -r requirements.txt
処理完了までは、しばらく時間がかかります。
処理が完了したら、Whisper speaker diarizationのインストールは終了です。
以上、Whisper speaker diarizationのインストールを説明しました。
次は、Whisper speaker diarizationの動作確認を説明します。
Whisper speaker diarizationの動作確認
Whisper speaker diarizationの動作確認を行います。
コンテンツルートに配置したapp.pyを実行します。
初回実行時には、必要なファイルをダウンロードすることになります。

次のように表示されたら、Whisper speaker diarizationの起動に成功しています。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
では、Chromeなどのブラウザで「http://127.0.0.1:7860」にアクセスします。
Hugging Face上のデモと同じ画面を確認できます。
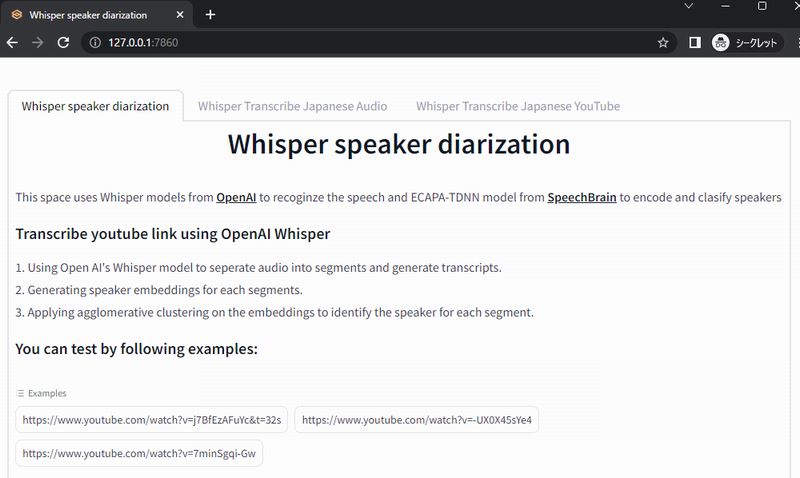
今回は、メイン機能であるWhisper speaker diarizationを試しましょう。
まず、複数人が話している動画をアップロードする必要があります。
用意されている「Example」を利用します。
URLが入力された状態で「Download YouTube video」をクリック。
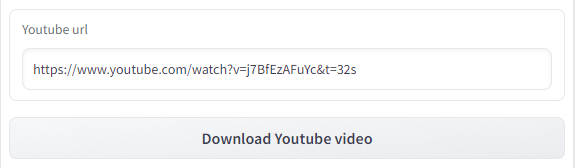
しばらくすると、動画がアップロードされた状態になります。

この状態で、以下の条件を設定。
選択した動画では、2人が日本語を話しています。
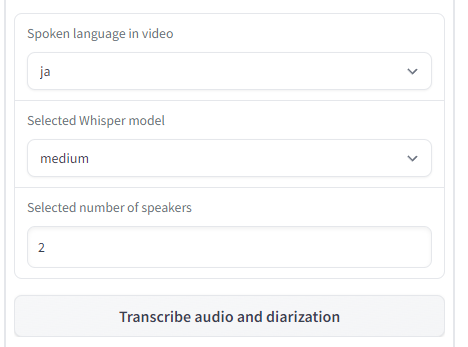
Whisperのモデルは、「medium」を選択。
条件を設定できたら、「Transcribe audio and diarization」ボタンをクリック。
しばらく待たされます。
モデルが存在していないと、ダウンロードから行うことになります。

動作しているのか心配な場合は、GPUの利用状況を確認してみましょう。
Windowsなら、タスクマネージャーで確認できます。
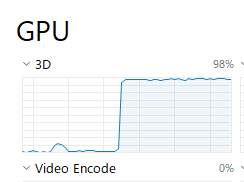
エラーが出ない限りは、根気強く待ちましょう。
GeForce RTX 3090でゴリゴリ動かしても、2分程度はかかっています。
そして、処理が上手くいくと次のように表示されます。

話者毎に文字起こしが実施されています。
これにより、いつ誰がどんな内容を話したのかがわかります。
以上、Whisper speaker diarizationの動作確認を説明しました。

