
機械学習を基礎から学ぶ人に向けた記事です。
同時に「Pythonではじめる機械学習」の解説記事でもあります。
そのため、「Pythonではじめる機械学習」を手元に用意してください。
それがこの記事を理解するためには必須です。
解説というより、書籍の内容を補完するモノと言った方が正確ですね。
この記事では、有名過ぎるアイリスのクラス分類を扱います。
実際に、JupyterLabでアイリスのクラス分類を行います。
ページは、P13~P25です。
本記事の内容
- 「Pythonではじめる機械学習」について
- JupyterLabについて
- アイリスのクラス分類
- データの読み込み
- 訓練データとテストデータに分ける
- データを可視化して観察する
- モデル構築・学習(k-最近傍法)
- モデルの評価(k-最近傍法)
- アイリスのクラス分類のまとめ
まずは、「Pythonではじめる機械学習」やJupyterLabについての説明からです。
「Pythonではじめる機械学習」について
Amazonのカスタマーレビューの評価は高いです。
私がこの本を選んだ理由は、以下です。
これが、「Pythonではじめる機械学習」のまえがきに書いてあります。
「数学で入門者を苦しめない」と宣言してくれています。
私には、そのように解釈できました。
私は、過去に2度も機械学習を挫折しています。
だから、数学という壁を取っ払おうとしてくれる本書には期待大です。
それらについては、次の記事で説明しています。
興味がある方は、どうぞご覧下さい。

なお、「はじめに」をもとに必要なモノはすべてインストールしておいてください。
- scikit-learn
- JupyterLab(書籍にはJupyter Notebookと記載)
- NumPy
- SciPy
- matplotlib
- pandas
- mglearn
JupyterLabについて
データ分析では、Jupyter Notebookを使う人が多いです。
でも、どうせ学ぶなら、最新のツールで学びましょう。
私は、JupyterLabを使っています。
次の記事では、Jupyter NotebookではなくJupyterLabを使う理由を解説しています。

そして、JupyterLabの使い方に関しては以下の記事をご覧下さい。

Jupyter NotebookとJupyterLabは、同じところが開発しています。
その開発元が、「Jupyter Notebookの開発はストップしたから、今後はJupyterLabを使え」と言っています。
そのため、この記事を読んでいる方はJupyterLabを使いましょう。
では、準備が整ったら、アイリスのクラス分類を見ていきましょう。
アイリスのクラス分類
アイリスの分類を機械学習で行います。
機械学習はデータが命ということで、まずはデータから確認です。
収集されたデータは以下(センチメートル単位)。
- ガクの長さ
- ガクの幅
- 花弁の長さ
- 花弁の幅
次に、ゴールですね。
ゴールは、データから分類わけすることです。
分類候補は以下。
- setosa(ヒオウギアヤメ)
- versicolor(ブルーフラッグ)
- virginica(該当する和名は見つかりませんでした)
すでに分類わけされた測定結果もあります。
だから、データと結果(ゴール)の関連付けデータがあるということです。
教師あり学習問題になりますね。
また、分類にわけることから、クラス分類問題になります。
とりあえず、今はこれぐらいの理解でいいと思います。
いざ、コーディング!!
データの読み込み
これだけで必要なデータを取得できます。
from sklearn.datasets import load_iris iris_dataset = load_iris()
便利ですよね。
scikit-learnをインストールした時点で、サンプルデータも取得しているわけです。
データの内容に関しては、「Pythonではじめる機械学習」に何やかんやと書いています。
でも、iris_datasetの中で大事なモノは2つです。
| iris_dataset[‘data’] | 収集されたデータ |
| iris_dataset[‘target’] | 分類結果 |
150個の組み合わせがあります。
訓練データとテストデータに分ける
元データを訓練データとテストデータに分けます。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'],random_state=0)
魔法のような関数です。
これだけで元データを次のように分割します。
| 訓練データ | 75% |
| テストデータ | 25% |
データを可視化して観察する
データを可視化するとは、グラフで表現することです。
その中でも、散布図は効果的になります。
pandasの機能を使って散布図を表現します。
そのため、X_trainをNumpy配列からデータフレームに変換する必要があります。
そのコードが以下。
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
columnsを指定することにより、カラム名に名前をつけます。
iris_dataframe.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
| 0 | 5.9 | 3.0 | 4.2 | 1.5 |
| 1 | 5.8 | 2.6 | 4.0 | 1.2 |
| 2 | 6.8 | 3.0 | 5.5 | 2.1 |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 |
| 4 | 6.9 | 3.1 | 5.1 | 2.3 |
散布図は以下のコードが記述されています。
grr = pd.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
でも、これは動きません。
次のようなエラーが出ます。
AttributeError: module 'pandas' has no attribute 'scatter_matrix'
pandasのバージョンが新しいほど動かないでしょう。
動くコードは以下。
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
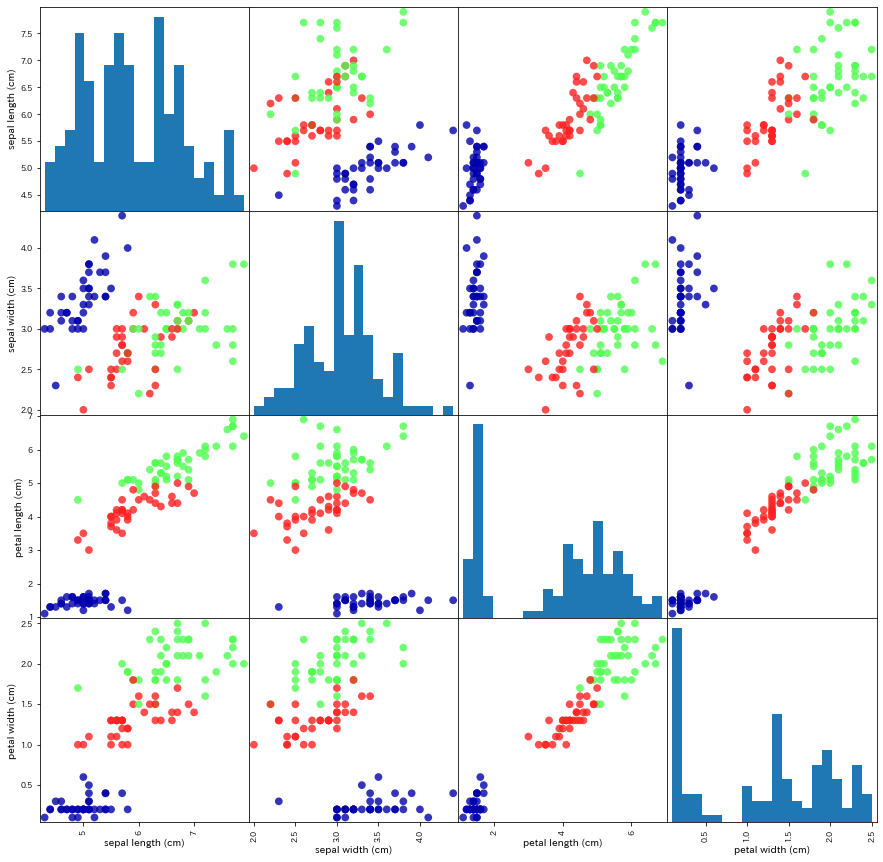
「分離していることがわかる」ようです。
機械学習の入門者には、この表現は厳しすぎませんか?
おそらく、ポイントは2点。
- 各色(アイリスの分類)がまとまっているか?
- それぞれのまとまりが分離しているか?
上記2点を満たすなら、機械学習モデルを訓練できるということです。
モデル構築・学習(k-最近傍法)
そもそも、クラス分類には様々なアルゴリズムが用意されています。
私は、アルゴリズムには興味はありません。
というより、興味を持たないようにしています。
機械学習の初心者のうちは、よく使われるアルゴリズムを使っておけばよいと思います。
「k-最近傍法でクラス分類をするんだぁ、へぇ~」ぐらいのノリで。
そうじゃないと、数学(数式)の迷宮に入り込んでしまいます。
だから、入門者のうちは、使い方を覚えることに重点をおきましょう。
構築
以下のコードでモデルを構築しています。
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=1)
学習
構築したモデルに訓練データを食わせます。
以下が学習するコードです。
knn.fit(X_train, y_train)
実行した返答は以下。
どのようなパラメータで学習させたかがわかります。
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=1, p=2, weights='uniform')
モデルの評価(k-最近傍法)
「Pythonではじめる機械学習」では、モデル構築・学習の後すぐに予測を行っています。
普通は、先にモデルの評価を行います。
学習したモデルが、本当に使えるかどうかを判定するのが先です。
よって、この記事でも先にモデルの評価から行います。
モデルの評価には、テストデータを用います。
コードは以下。
knn.score(X_test, y_test)
0.9736842105263158
97%の確率で正確な予測ができたことを示しています。
サンプルデータとは言え、スゴイ精度です。
アイリスのクラス分類のまとめ
「Pythonではじめる機械学習」における、「1.7.5 予測を行う」は不要だと思います。
確かに、学習させたモデルで予測することは面白いです。
「予測できる!!すげー」となりますが、1度にいろいろ詰め込み過ぎでしょう。
だからかどうかわかりませんが、「1.8 まとめと今後の展望」には最小コードを載せています。
それを参考にした最小コードを載せておきます。
import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split iris_dataset = load_iris() X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'],random_state=0) iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names) from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=1) knn.fit(X_train, y_train) print(knn.score(X_test, y_test))
たった、これだけのコードで機械学習ができるのです。
そう思えば、「機械学習の勉強はイケルかも」と思いませんか?

