
「機械学習によるデータ分析に興味はあるけど、難しそう・・・」
「データ分析にあまりコストをかけることはできない・・・」
このような場合には、この記事の内容が参考になります。
この記事では、誰でも簡単にできる機械学習によるデータ分析について解説しています。
本記事の内容
- 誰でも簡単にできる機械学習によるデータ分析
- ChatGPT + Noteableによるデータ分析の実践
それでは、上記に沿って解説していきます。
誰でも簡単にできる機械学習によるデータ分析
機械学習によるデータ分析は、もうプロだけのモノではありません。
誇大広告ではなく、本当に誰でもできるようになりました。
ここで言う誰でもは、データサイエンティストやエンジニア以外でもと言う意味です。
難しいアルゴリズムを理解する必要はありません。
また、Pythonのコードを書く必要もありません。
正直、もうこのような本を読む必要がないかもしれません。
もちろん、機械学習やデータ分析に全く無知では厳しいかもしれません。
しかし、それでも何とかなる可能性すらあると言えます。
そんな可能性すら抱かせてくれるのが、ChatGPTです。
正確には、ChatGPTとそのプラグインであるNoteableになります。
Noteableについては、次の記事で説明しています。
誰でも簡単にできる機械学習によるデータ分析では、Noteableの利用が必須です。
そのため、Noteableを利用できるようにしておきます。
以下では、誰でも簡単に機械学習によるデータ分析ができることを説明します。
説明と言うよりは、実践したログに近いです。
ChatGPT + Noteableによるデータ分析の実践
誰でも簡単に試せるように、データはオープンなモノを利用します。
機械学習によるデータ分析と言えば、ボストンの住宅価格データセットですね。
Noteableのプラグインが有効であることを確認して、次のようにプロンプトを入力します。
scikit-learnを利用して、ボストンの住宅価格データセットを読み込んでください。
次のように返答が表示されます。
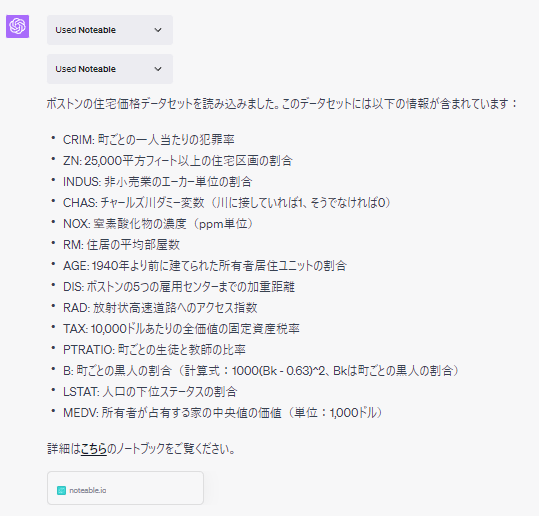
ChatGPTからNoteableに対して、次の名称でノートブックを作成するようにリクエストされました。
このことは、一つ目の「Used Noteable」をクリックして確認できます。
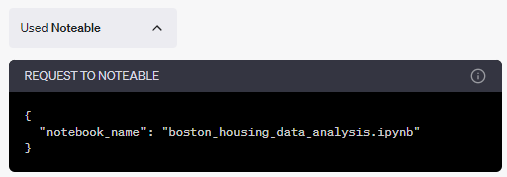
そして、二つ目の「Used Noteable」ではPythonコードが含まれていることを確認できます。
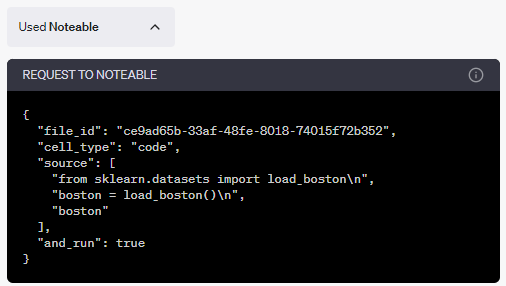
このPythonコードは、ChatGPTが考えたコードです。
このコードをNoteableに渡していることを確認できます。
そして、その渡されたコードの実施状況はNoteable上で確認可能です。
「こちら」リンクをクリックします。
Noteableのページが開いて、作成指示した名称のノートブックを確認できます。
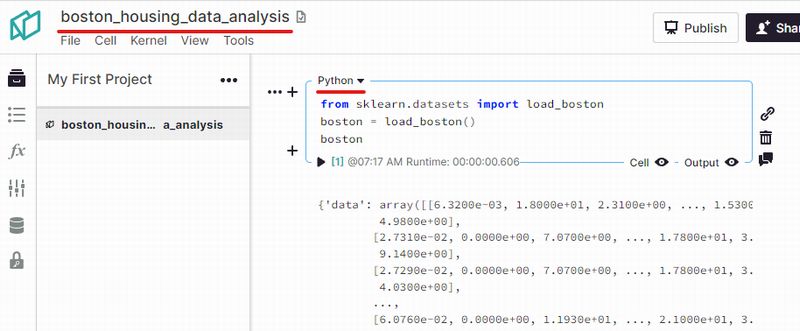
そして、Pythonコードが実行されていることを確認可能です。
あと、コードを実行した結果も。
ChatGPTとNoteableに関係において、このような処理が行われています。
とりあえず、この関係を頭に入れておいてください。
これ以降は、ChatGPTだけで説明を進めます。
では、さっそくChatGPTに機械学習をさせましょう。
単刀直入に次のプロンプトを入力します。
最も精度の高い予測モデルを教えてください。
こんなプロンプトにもChatGPTはちゃんと返答してくれます。

ChatGPTの回答は、勉強になりますね。
人間の場合、ここまで丁寧に回答をしてくれるかどうか微妙です。
アルゴリズムについて、オススメを聞いてみます。
どのアルゴリズムがオススメですか?
理由を含めて、選択肢を提示してくれています。

チマチマするのは面倒なんで一気にやらせましょう。
上記4つをすべて試してください。
AI相手だと平気で無茶な指示を出せるのですよね。
この指示にはさすがに少し時間がかかります。
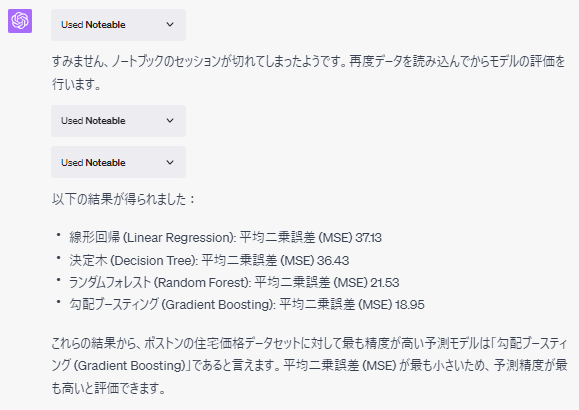
セッションが切れたようですが、自動で対応したようです。
このような動きは、人工知能という感じがします。
肝心の結果は、以下となっています。
- 線形回帰 (Linear Regression): 平均二乗誤差 (MSE) 37.13
- 決定木 (Decision Tree): 平均二乗誤差 (MSE) 36.43
- ランダムフォレスト (Random Forest): 平均二乗誤差 (MSE) 21.53
- 勾配ブースティング (Gradient Boosting): 平均二乗誤差 (MSE) 18.95
RMSEで表記してもらいましょう。
RMSEで表示してください。
- 線形回帰 (Linear Regression): 平均二乗根誤差 (RMSE) 5.83
- 決定木 (Decision Tree): 平均二乗根誤差 (RMSE) 5.86
- ランダムフォレスト (Random Forest): 平均二乗根誤差 (RMSE) 4.44
- 勾配ブースティング (Gradient Boosting): 平均二乗根誤差 (RMSE) 4.20
次に、モデルの最適化をお願いしてみましょう。
具体的なことは言わず、ざっくりとした物言いで。
最適化できませんか?
ここでも、ChatGPTは丁寧かつ勉強になる回答をくれています。

実施する最適化は、ハイパーパラメータチューニングであることを定義しています。
一般的には、次の二つが一般的に行われているハイパーパラメータチューニングということです。
- グリッドサーチ(Grid Search)
- ランダムサーチ(Random Search)
そして、ハイパーパラメータチューニングに時間がかかることを教えてくれてます。
「よろしいですか?」と、確認までしてくれるのですね。
もちろん、ここはOK。
よろしいです。
そうすると、次のように表示されます。
先に言っておくと、お知らせはしてくれません。
そのため、Noteableのノートブックで進捗を確認することをオススメします。
処理が終わったようであれば、次のように確認します。
終わりましたか?
終わっていれば、次のように表示されます。

ハイパーパラメータチューニングの結果は、精度が下がっています。
そのことについて聞いてみます。
ハイパーパラメータチューニングした方が、RMSEが下がっているのですか?
これも冷静かつ丁寧に回答してくれます。
人間同士なら、ちょっとした言い合いにもなりかねません。

折角提案してくれているので、「ベイズ最適化」をやってもらいましょう。
AIが相手なら、遠慮なく指示できますね。
ベイズ最適化を試してください。
ただ、セッションはしばしば切れるようです。
ベイズ最適化は、結構時間がかかります。
終わりましたか?
処理中に確認したら、次のように回答されます。

処理完了後(6分12秒の処理時間)に確認したら、次のように表示されます。

かなり改善されましたね。
こんなふうにChatGPTが相手であれば、ガンガンと指示を出せます。
自分で実行する場合でも、ここまで軽やかには動けません・・・
しかし、AIが相手だと遠慮も躊躇もありません。
以上、ChatGPT + Noteableによるデータ分析の実践を説明しました。

