
「AnimateDiffの処理に時間がかかり過ぎる・・・」
「AnimateDiffのGIF生成の速度を改善したい」
このような場合には、この記事の内容が参考になります。
この記事では、AnimateDiffの処理速度を改善する方法を解説しています。
本記事の内容
- AnimateDiffの起動ツール
- AnimateDiffの処理速度をUPする方法
- AnimateDiffの処理速度UPの効果
それでは、上記に沿って解説していきます。
AnimateDiffの起動ツール
AnimateDiffについては、次の記事で説明しています。

AnimateDiffを使えば、プロンプトでGIFアニメを生成できるようになります。
そして、AnimateDiffを動かすには以下のツールが利用可能です。
- コマンド(Pythonスクリプト)
- Gradio(専用GUI)
- web UI
オススメは、web UIです。
おそらく、多くの方が普段からweb UIを利用していることでしょう。

機能的にも、web UIを利用する方が優れています。
また、速度に関してもweb UIの方が速いです。
したがって、web UIでAnimateDiffを利用することをオススメしています。
ここで言うweb UIは、AUTOMATIC1111版web UIとなります。
これだけ推しているweb UIですが、さらにAnimateDiffの速度UPが可能です。
「2倍以上UP!!」とまでは行きませんが、確実に処理速度はUPします。
その方法を以下で説明します。
AnimateDiffの処理速度をUPする方法
AnimateDiffの処理速度をUPする方法とは、web UIの処理速度をUPする方法とも言えます。
もっと言うと、PyTorchの処理速度をUPする方法となります。
PyTorchの処理速度UPと言うと、xFormersを思い浮かべるかもしれません。

実は、PyTorch 2系では別の処理速度UPの方法があります。
それは、「–opt-sdp-attention」オプションを利用する方法です。

ただ、現在はPyTorch 2系でもxFormersを利用することができます。
しかし、AnimateDiffの拡張機能にxFormersは適用されません。
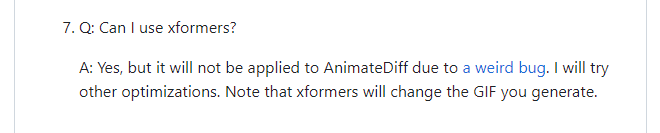
拡張機能の開発者が、公式ページで回答しています。
https://github.com/continue-revolution/sd-webui-animatediff
よって、残された道は「–opt-sdp-attention」を利用する選択肢のみとなります。
おそらく、速度だけで言えばxFormersよりは上だと思いますけどね。
(画質云々がどうなるのかは未検証)
具体的には、以下のコマンドがAnimateDiffの処理速度をUPする方法となります。
python launch.py --no-half-vae --opt-sdp-attention --opt-sdp-no-mem-attention
上記コマンドでweb UIを起動すれば、AnimateDiffの速度をUPできます。
以下では、実際にどれほど処理速度がUPしたのかを説明します。
AnimateDiffの処理速度UPの効果
効果を判定するために、以下のパターンで検証しています。
- なし
- 「–opt-sdp-attention」 + 「–opt-sdp-no-mem-attention」
- 「–opt-sdp-attention」 + 「–opt-sdp-no-mem-attention」 + 「–opt-channelslast」
「–opt-channelslast」については、環境次第のところがあると言われています。
おまけ程度に捉えてください。
本命は、パターン1とパターン2の比較です。
そして、GIFアニメは以下の2種類を生成します。
- 512 x 512の16フレーム
- 768 x 768の24フレーム
それぞれの種類毎に確認していきます。
なお、検証したマシン(Windows 11)のGPUは以下となります。
> nvidia-smi --query-gpu=name,memory.total,memory.free --format=csv,noheader NVIDIA GeForce RTX 3090, 24576 MiB, 18561 MiB
画像生成のためのプロンプトは、すべて同じモノを用いています。
512 x 512の16フレーム
まず、画像生成はデフォルト設定とします。
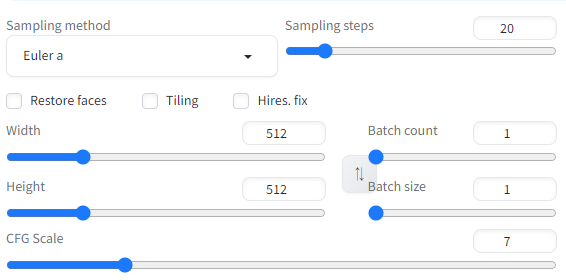
AnimateDiffの設定もデフォルトです。
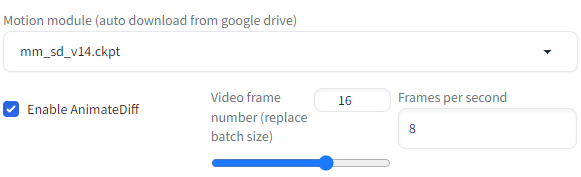
上記の設定で全パターンを10回実行した結果が以下となります。
1.なし
Time taken: 31.29s Torch active/reserved: 13940/17258 MiB, Sys VRAM: 19784/24576 MiB (80.5%) Time taken: 33.82s Torch active/reserved: 13940/17258 MiB, Sys VRAM: 19773/24576 MiB (80.46%) Time taken: 33.84s Torch active/reserved: 13940/17260 MiB, Sys VRAM: 19783/24576 MiB (80.5%) Time taken: 31.59s Torch active/reserved: 13940/17258 MiB, Sys VRAM: 19769/24576 MiB (80.44%) Time taken: 31.54s Torch active/reserved: 13940/17260 MiB, Sys VRAM: 19702/24576 MiB (80.17%) Time taken: 31.29s Torch active/reserved: 13940/17258 MiB, Sys VRAM: 19696/24576 MiB (80.14%) Time taken: 31.59s Torch active/reserved: 13940/17260 MiB, Sys VRAM: 19750/24576 MiB (80.36%) Time taken: 31.32s Torch active/reserved: 13940/17260 MiB, Sys VRAM: 19683/24576 MiB (80.09%) Time taken: 31.13s Torch active/reserved: 13940/17260 MiB, Sys VRAM: 19682/24576 MiB (80.09%) Time taken: 31.35s Torch active/reserved: 13940/17258 MiB, Sys VRAM: 19711/24576 MiB (80.2%)
2.「–opt-sdp-attention」 + 「–opt-sdp-no-mem-attention」
Time taken: 27.47s Torch active/reserved: 8846/10396 MiB, Sys VRAM: 12762/24576 MiB (51.93%) Time taken: 28.13s Torch active/reserved: 8853/10090 MiB, Sys VRAM: 12464/24576 MiB (50.72%) Time taken: 27.73s Torch active/reserved: 8853/10090 MiB, Sys VRAM: 12464/24576 MiB (50.72%) Time taken: 27.80s Torch active/reserved: 8853/10090 MiB, Sys VRAM: 12464/24576 MiB (50.72%) Time taken: 27.49s Torch active/reserved: 8853/10090 MiB, Sys VRAM: 12464/24576 MiB (50.72%) Time taken: 27.61s Torch active/reserved: 8853/10090 MiB, Sys VRAM: 12464/24576 MiB (50.72%) Time taken: 27.58s Torch active/reserved: 8853/10090 MiB, Sys VRAM: 12464/24576 MiB (50.72%) Time taken: 27.47s Torch active/reserved: 8853/10090 MiB, Sys VRAM: 12464/24576 MiB (50.72%) Time taken: 27.40s Torch active/reserved: 8853/10090 MiB, Sys VRAM: 12464/24576 MiB (50.72%)
3.「–opt-sdp-attention」 + 「–opt-sdp-no-mem-attention」 + 「–opt-channelslast」
Time taken: 29.87s Torch active/reserved: 8844/10040 MiB, Sys VRAM: 12406/24576 MiB (50.48%) Time taken: 29.33s Torch active/reserved: 8844/10042 MiB, Sys VRAM: 12408/24576 MiB (50.49%) Time taken: 29.57s Torch active/reserved: 8844/10040 MiB, Sys VRAM: 12406/24576 MiB (50.48%) Time taken: 29.56s Torch active/reserved: 8844/10042 MiB, Sys VRAM: 12408/24576 MiB (50.49%) Time taken: 29.45s Torch active/reserved: 8844/10040 MiB, Sys VRAM: 12406/24576 MiB (50.48%) Time taken: 29.34s Torch active/reserved: 8844/10040 MiB, Sys VRAM: 12406/24576 MiB (50.48%) Time taken: 29.50s Torch active/reserved: 8844/10040 MiB, Sys VRAM: 12406/24576 MiB (50.48%) Time taken: 29.40s Torch active/reserved: 8844/10042 MiB, Sys VRAM: 12408/24576 MiB (50.49%) Time taken: 29.96s Torch active/reserved: 8844/10042 MiB, Sys VRAM: 12408/24576 MiB (50.49%) Time taken: 29.29s Torch active/reserved: 8844/10042 MiB, Sys VRAM: 12408/24576 MiB (50.49%)
パターン2の「–opt-sdp-attention」 + 「–opt-sdp-no-mem-attention」が、最速ですね。
パターン1と比べると、4秒程度は速度がUPできています。
でも、次のように感じる人もいるかもしれません。
「4秒程度なら、別に今のままでもいいかなぁ」
ただ、4秒程度と言っても10回繰り返せば40秒ですからね。
768 x 768の24フレーム
次は、画像を大きくしましょう。
あと、Sampling stepsとCFG Scaleも値を増やします。
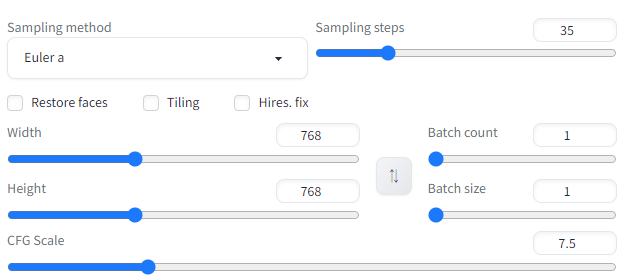
フレーム数も増やします。
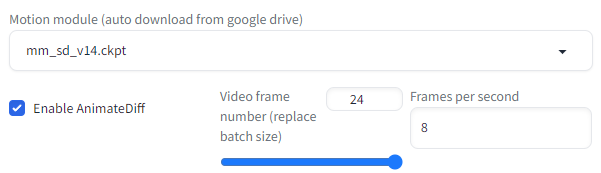
GPUメモリの限界に挑む設定となります。
この設定だと、かなりの時間がかかります。
よって、それぞれの試行数は3回としています。
3回でも十分に違いのわかる結果となっています。
1.なし
Time taken: 3m 41.27s Torch active/reserved: 18802/23202 MiB, Sys VRAM: 24576/24576 MiB (100.0%) Time taken: 3m 30.40s Torch active/reserved: 18805/23190 MiB, Sys VRAM: 24576/24576 MiB (100.0%) Time taken: 3m 45.84s Torch active/reserved: 18834/23190 MiB, Sys VRAM: 24576/24576 MiB (100.0%)
2.「–opt-sdp-attention」 + 「–opt-sdp-no-mem-attention」
Time taken: 2m 58.77s Torch active/reserved: 18813/22882 MiB, Sys VRAM: 24576/24576 MiB (100.0%) Time taken: 2m 46.00s Torch active/reserved: 18839/23426 MiB, Sys VRAM: 24576/24576 MiB (100.0%) Time taken: 2m 49.69s Torch active/reserved: 18834/22888 MiB, Sys VRAM: 24576/24576 MiB (100.0%)
3.「–opt-sdp-attention」 + 「–opt-sdp-no-mem-attention」 + 「–opt-channelslast」
Time taken: 2m 58.65s Torch active/reserved: 18805/22336 MiB, Sys VRAM: 24576/24576 MiB (100.0%) Time taken: 2m 55.04s Torch active/reserved: 18807/23418 MiB, Sys VRAM: 24576/24576 MiB (100.0%) Time taken: 2m 55.52s Torch active/reserved: 18804/22336 MiB, Sys VRAM: 24576/24576 MiB (100.0%)
いかがでしょうか?
処理速度UPの効果を実感できる結果ではないでしょうか?
パターン2はパターン1よりも、40秒近く時間短縮になっています。
「512 x 512の16フレーム」で短縮できた4秒の10倍ということですね。
つまり、処理が重くなればなるほど、より速度UPの効果が発揮されると言えます。

