
「Whisperを高速化する方法は?」
「Whisperのlarge-v3をなるべく速く動かしたい」
このような場合には、Faster Whisperがオススメです。
この記事では、Faster Whisperについて解説しています。
本記事の内容
- Faster Whisperとは?
- Faster Whisperのシステム要件
- Faster Whisperのインストール
- Faster Whisperの動作確認
それでは、上記に沿って解説していきます。
Faster Whisperとは?
Faster Whisperは、OpenAIのWhisperモデルの再実装です。
CTranslate2という高速なトランスフォーマーモデル用の推論エンジンを使用しています。
この実装は、同じ精度でOpenAIのWhisperより最大4倍高速で、メモリ使用量も少なくなっています。
さらに、CPUおよびGPU上で8ビット量子化を使用することで効率を向上させることができます。
結果の比較表は、以下。
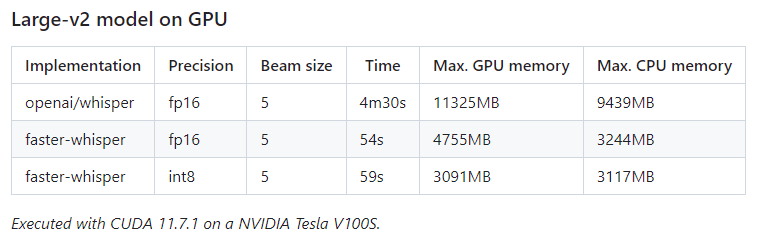
OpenAIのWhisperと比べると、GPU・CPUの使用効率が全く違いますね。
処理時間も一気に短くなっています。
これこそが、オープンソースであることの意味だと思います。
世界中の天才たちが、競って機能改善を実施してくれます。
Whisper自体については、次の記事で説明しています。

Faster Whisperのシステム要件
Faster Whisperのシステム要件は、以下だけです。
- Python 3.8以降
ただし、GPUでFaster Whisperを利用するには以下の要件も必要になります。
- cuBLAS for CUDA 11
- cuDNN 8 for CUDA 11
とりあえず、CUDA 11のインストールが必要です。
CUDAのインストールは、次の記事が参考になります。

CUDAをインストールできたら、cuBLASも同時にインストール済みとなります。
つまり、CUDAの中にcuBLASが含まれているということです。
cuDNNが、cuBLASに比べると少し面倒になるかもしれません。
と言っても、ファイルをコピーするだけですけどね。
cuDNNのインストールは、次の記事で解説しています。

コピーできたら、cuDNNのインストールは完了です。
ここまで準備できたら、Faster Whisperのシステム要件はクリアと言えます。
Faster Whisperのインストール
Faster Whisperは、次のコマンドを実行するだけです。
pip install faster-whisper
上記コマンドにより、以下で確認できるライブラリがインストールされます。
> pip list Package Version ------------------ ---------- av 10.0.0 certifi 2023.11.17 charset-normalizer 3.3.2 colorama 0.4.6 coloredlogs 15.0.1 ctranslate2 3.23.0 faster-whisper 0.10.0 filelock 3.13.1 flatbuffers 23.5.26 fsspec 2023.12.2 huggingface-hub 0.19.4 humanfriendly 10.0 idna 3.6 mpmath 1.3.0 numpy 1.26.2 onnxruntime 1.16.3 packaging 23.2 pip 23.3.2 protobuf 4.25.1 pyreadline3 3.4.1 PyYAML 6.0.1 requests 2.31.0 setuptools 69.0.2 sympy 1.12 tokenizers 0.15.0 tqdm 4.66.1 typing_extensions 4.9.0 urllib3 2.1.0 wheel 0.38.4
Faster Whisperの動作確認
Faster Whisperの動作確認をするために、音声ファイルを用意しましょう。
ここでは、音声合成したファイルを利用します。

上記記事の最後に「gTTS_test.mp3」というファイルがあります。
その音声ファイルは、次のテキストもとに生成されています。
過去最強クラスの台風14号が近づいてきています。 九州南部、そして北部の皆さんを中心に暴風、高波、高潮や大雨などに最大級の警戒をしてください。
利用するコードは、以下。
このコードは、公式で公開されているモノです。
from faster_whisper import WhisperModel
model_size = "large-v3"
# Run on GPU with FP16
model = WhisperModel(model_size, device="cuda", compute_type="float16")
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# or run on CPU with INT8
# model = WhisperModel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe("gTTS_test.mp3", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
上記を実行した結果は、以下となります。
Detected language 'ja' with probability 0.998535 [0.00s -> 10.54s] 過去最強クラスの台風14号が近づいてきています 九州南部そして北部の皆さんを中心に暴風 [10.54s -> 16.12s] 高波高潮や大雨などに最大級の警戒をしてください
句読点を無視すれば、完璧です。
ちなみに、上記コードでは「large-v3」というモデルを利用しています。
これは、現時点で最も精度の高いモデルになります。
Faster Whisperでならば、そこまで強力なGPUでなくても動くはずです。

