「表示領域を区切ってプロンプトを反映させたい」
「画像生成ガチャの運ゲー要素を少しでも減らしたい」
このような場合には、ComfyUIをオススメします。
この記事では、ComfyUIについて解説しています。
本記事の内容
- ComfyUIとは?
- ComfyUIのシステム要件
- ComfyUIのインストール
- ComfyUIの動作確認
それでは、上記に沿って解説していきます。
ComfyUIとは?
ComfyUIとは、Stable DiffusionのGUIツールです。
Stable DiffusionのGUIツールと言えば、AUTOMATIC1111版web UIなどが存在します。
GUIツールの中でも、ComfyUIは最もGUI的なツールと言えます。
でも、この画面を見て面倒だと思った人はいませんか?
私は、初めてみたとき面倒だと思いました。
マウスを使ってチマチマとしていくのは、好みではありません。
どちらかと言うと、できる限りコマンドでガンガンとやりたい人間です。
しかし、そんな私でもComfyUIの使い方を覚えました。
それほどまでに、ComfyUIの機能がスゴイのです。
詳細は、Redditのスレッドに詳しく記載されています。
https://www.reddit.com/r/StableDiffusion/comments/10lzgze/i_figured_out_a_way_to_apply_different_prompts_to/
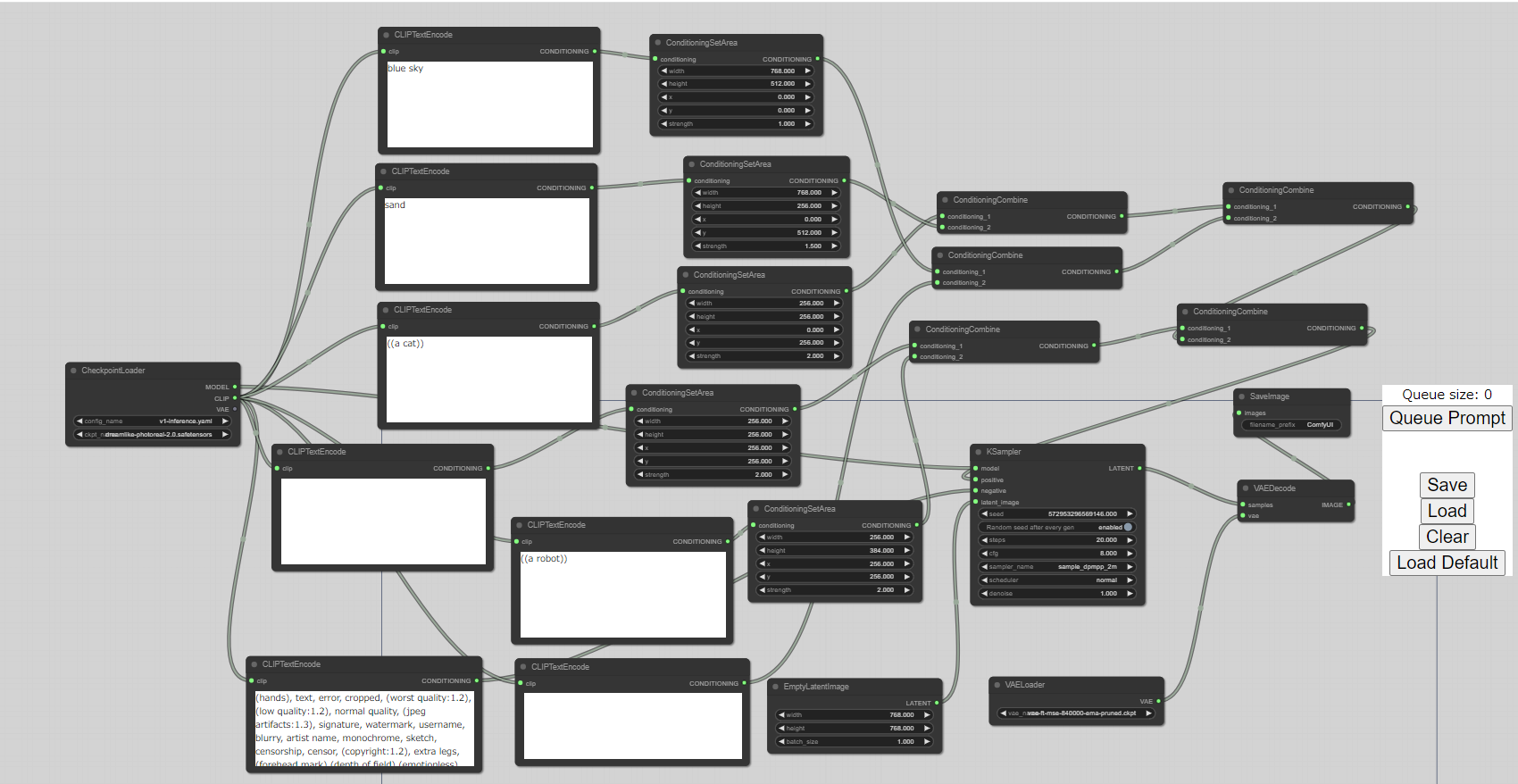
ComfyUIの機能については、次の画像を見るのが一番早いです。

わかったでしょうか?
左の画像のように画像を3つのセクションに分割しています。
そして、分割されたセクション毎にプロンプトを設定できるのです。
そうやって生成された画像が、右の画像になります。
この左側の画像の設定を表現するために、GUIが活躍するということです。
設定情報は、jsonとして保存することができます。
そのjsonを読み込んで、画面上に再現することも可能です。
とにかく、まずは触ってみることをオススメします。
食わず嫌いでComfyUIを利用しないのは、本当に勿体ないです。
ComfyUIを使えば、新たな画像生成の世界を垣間見ることができます。
以上、ComfyUIについて説明しました。
次は、ComfyUIのシステム要件を説明します。
ComfyUIのシステム要件
ComfyUIは、まだバージョン管理はされていません。
2023年になって、Githubで公開されたばかりです。
comfyanonymous/ComfyUI: A powerful and modular stable diffusion GUI.
https://github.com/comfyanonymous/ComfyUI
システム要件は、次の点に注意すればよいでしょう。
- OS
- Pythonバージョン
- PyTorch
それぞれを以下で説明します。
OS
サポートOSに関しては、以下を含むクロスプラットフォーム対応のはずです。
- Windows
- macOS
- Linux
少なくともWindowsで動くことは確認できました。
ソースを見る限り、OS依存はないようです。
Pythonバージョン
現時点でのPython公式開発サイクルは、以下。
| バージョン | リリース日 | サポート期限 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
| 3.11 | 2022年10月25日 | 2027年10月 |
ただし、公式ページではPython 3.10であることを確認するように記載されています。
また、Python 3.11では問題があるという記述もあります。
つまり、Python 3.10を使いましょうと言えますね。
私もPython 3.10で検証しています。
PyTorch
PyTorchのインストールは、事前に済ませておきましょう。
基本的には、GPU版のPyTorchが前提になっています。
おそらく、CPUではまともに動かないと思います。
そのため、GPU版のPyTorchをインストールしておきましょう。

現時点では、1.13.1が最新バージョンとなります。

以上、ComfyUIのシステム要件を説明しました。
次は、ComfyUIのインストールを説明します。
ComfyUIのインストール
ComfyUIのインストールは、Python仮想環境の利用をオススメします。
Python仮想環境は、次の記事で解説しています。

検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
そして、システム要件であるGPU版PyTorchをインストール済という状況です。
このような状況において、次の手順でComfyUIのインストールを進めます。
- ComfyUIの取得(GitHubから)
- requirements.txtを使った一括インストール
それぞれを下記で説明します。
ComfyUIの取得(GitHubから)
次のコマンドでGitHUbからリポジトリを取得します。
git clone https://github.com/comfyanonymous/ComfyUI.git
リポジトリをダウンロードできたら、リポジトリルートへ移動しておきます。
cd ComfyUI
基本的には、このリポジトリルートでコマンドを実行します。
requirements.txtを使った一括インストール
リポジトリルートでは、以下のファイルが確認できます。
requirements.txt
torch torchdiffeq torchsde omegaconf einops open-clip-torch transformers safetensors pytorch_lightning
事前にPyTorchはインストール済みです。
そのため、PyTorchはコメントにします。
#torch
ファイルを変更できたら、次のコマンドで一気にインストールしましょう。
pip install -r requirements.txt
インストールには、そこまで時間がかからないはずです。
以上、ComfyUIのインストールを説明しました。
次は、ComfyUIの動作確認を説明します。
ComfyUIの動作確認
ComfyUIの動作確認を行うには、モデルが必要となります。
最低でも1個のモデルを用意しましょう。
runwayml/stable-diffusion-v1-5 at main
https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
無難なモデルとして、以下のどちらかをダウンロードします。
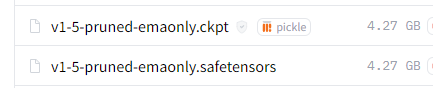
ダウンロードしたモデルは、「checkpoints」に保存します。
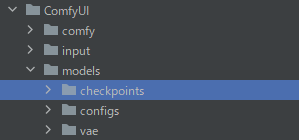
VAEを利用する場合は、「vae」に保存することになります。
とりあえず、今回は上記のモデルのみで動作確認を行います。
モデルが用意できたので、ComfyUIを起動します。
起動するには、リポジトリルートで次のコマンドを実行しましょう。
python main.py
実行すると、コンソールに次のように表示されます。
Using sub quadratic optimization for cross attention, if you have memory or speed issues try using: --use-split-cross-attention Starting server To see the GUI go to: http://127.0.0.1:8188
ブラウザで「http://127.0.0.1:8188」にアクセスします。
アクセスすると、次のような画面を確認できます。
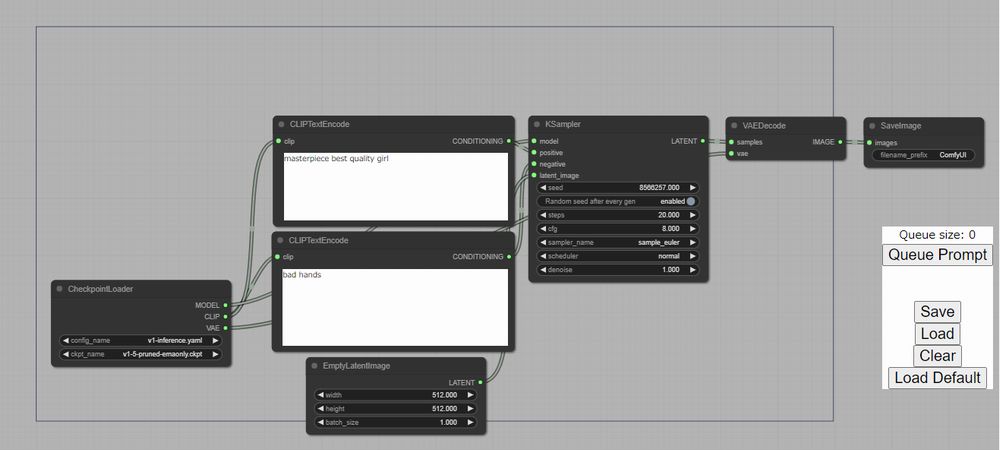
一番左端のノードを確認します。
先ほどダウンロードしたモデルが表示されていますか?
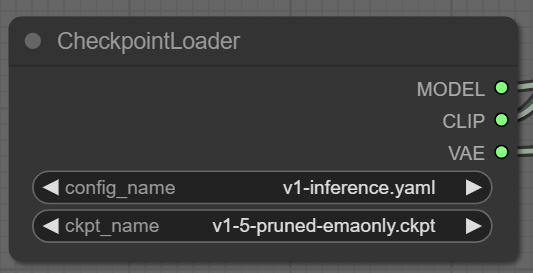
もし表示されていなければ、上記のように設定します。
設定できたら、「Queue Prompt」ボタンを」クリック。
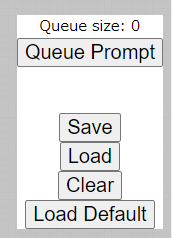
正常に機能すれば、「Queue size」がカウントアップします。
クリックすればするほど、処理がキューに入ることになります。
そして、処理が完了すればこの値が減少していきます。
生成された画像は、以下のディレクトリに保存されています。
処理を4回実行した後には、4つの画像を確認できます。
生成された画像は、以下。
質が低いのは、ここでは置いておきましょう。

このような画像が生成されたのは、以下のように設定しているからです。
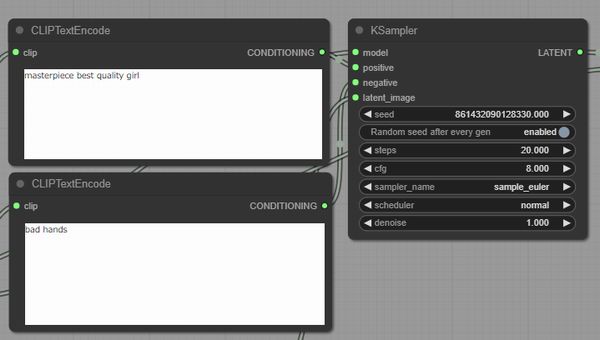
Stable Diffusionユーザーなら、大体わかりますよね。
そもそも、この画面のヘルプは存在していません。
実際に見て、触って覚えるしかありません。
まずは、いろいろと触ってみてください。
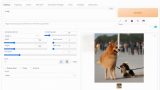
コツがわかってくれば、次のような画像を簡単に作れるようになります。

上記の画像は、画像を横軸に3分割しています。
左から、「a cat」「a dog」「a robot」とそれぞれプロンプトに設定しました。
モデルには、「AbyssOrangeMix2」というモデルを利用しています。
アニメモデルのため、ロボットが女性化しています。
とにかく、まずは触って覚えましょう。
これしかありません。
以上、ComfyUIの動作確認を説明しました。

